 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-World Object Detection with Instance Representation Learning
Paper and Code
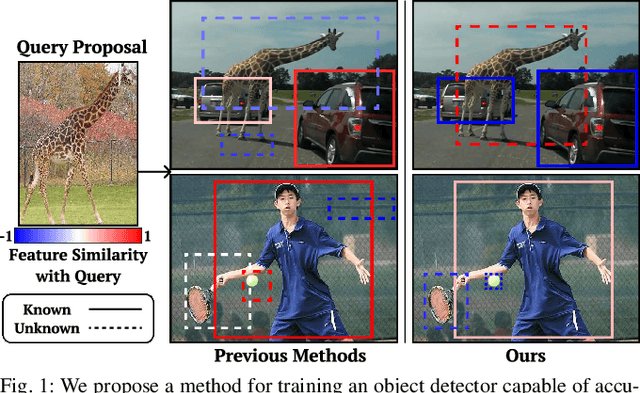
While humans naturally identify novel objects and understand their relationships, deep learning-based object detectors struggle to detect and relate objects that are not observed during training. To overcome this issue, Open World Object Detection(OWOD) has been introduced to enable models to detect unknown objects in open-world scenarios. However, OWOD methods fail to capture the fine-grained relationships between detected objects, which are crucial for comprehensive scene understanding and applications such as class discovery and tracking. In this paper, we propose a method to train an object detector that can both detect novel objects and extract semantically rich features in open-world conditions by leveraging the knowledge of Vision Foundation Models(VFM). We first utilize the semantic masks from the Segment Anything Model to supervise the box regression of unknown objects, ensuring accurate localization. By transferring the instance-wise similarities obtained from the VFM features to the detector's instance embeddings, our method then learns a semantically rich feature space of these embeddings. Extensive experiments show that our method learns a robust and generalizable feature space, outperforming other OWOD-based feature extraction methods. Additionally, we demonstrate that the enhanced feature from our model increases the detector's applicability to tasks such as open-world tracking.