 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Variate Temporal GAN for Large Scale Video Generation
Paper and Code



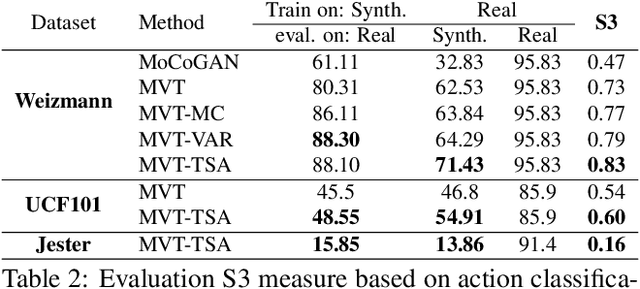
In this paper, we present a network architecture for video generation that models spatio-temporal consistency without resorting to costly 3D architectures. In particular, we elaborate on the components of noise generation, sequence generation, and frame generation. The architecture facilitates the information exchange between neighboring time points, which improves the temporal consistency of the generated frames both at the structural level and the detailed level. The approach achieves state-of-the-art quantitative performance, as measured by the inception score, on the UCF-101 dataset, which is in line with a qualitative inspection of the generated videos. We also introduce a new quantitative measure that uses downstream tasks for evaluation.