 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSR-CACO-2: A Dataset for Confocal Fluorescence Microscopy Image Super-Resolution
Jun 13, 2024



Confocal fluorescence microscopy is one of the most accessible and widely used imaging techniques for the study of biological processes. Scanning confocal microscopy allows the capture of high-quality images from 3D samples, yet suffers from well-known limitations such as photobleaching and phototoxicity of specimens caused by intense light exposure, which limits its use in some applications, especially for living cells. Cellular damage can be alleviated by changing imaging parameters to reduce light exposure, often at the expense of image quality. Machine/deep learning methods for single-image super-resolution (SISR) can be applied to restore image quality by upscaling lower-resolution (LR) images to produce high-resolution images (HR). These SISR methods have been successfully applied to photo-realistic images due partly to the abundance of publicly available data. In contrast, the lack of publicly available data partly limits their application and success in scanning confocal microscopy. In this paper, we introduce a large scanning confocal microscopy dataset named SR-CACO-2 that is comprised of low- and high-resolution image pairs marked for three different fluorescent markers. It allows the evaluation of performance of SISR methods on three different upscaling levels (X2, X4, X8). SR-CACO-2 contains the human epithelial cell line Caco-2 (ATCC HTB-37), and it is composed of 22 tiles that have been translated in the form of 9,937 image patches for experiments with SISR methods. Given the new SR-CACO-2 dataset, we also provide benchmarking results for 15 state-of-the-art methods that are representative of the main SISR families. Results show that these methods have limited success in producing high-resolution textures, indicating that SR-CACO-2 represents a challenging problem. Our dataset, code and pretrained weights are available: https://github.com/sbelharbi/sr-caco-2.
Embedding-based Recommender System for Job to Candidate Matching on Scale
Jul 01, 2021
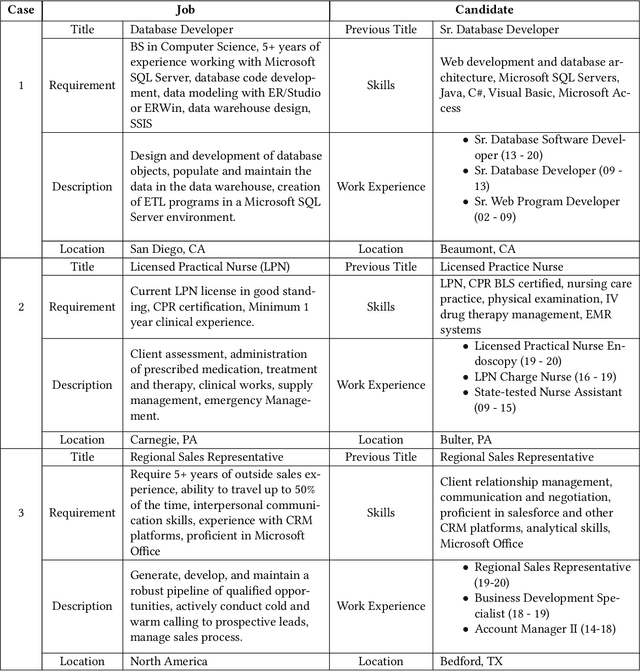

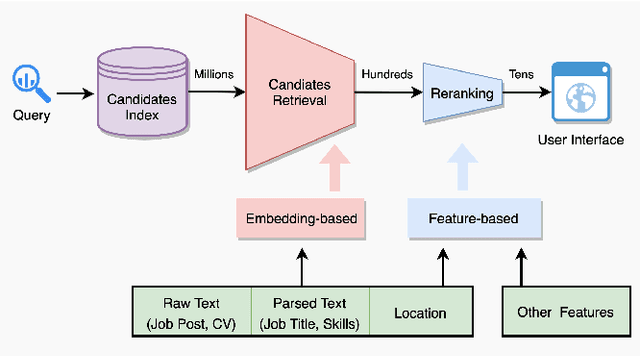
The online recruitment matching system has been the core technology and service platform in CareerBuilder. One of the major challenges in an online recruitment scenario is to provide good matches between job posts and candidates using a recommender system on the scale. In this paper, we discussed the techniques for applying an embedding-based recommender system for the large scale of job to candidates matching. To learn the comprehensive and effective embedding for job posts and candidates, we have constructed a fused-embedding via different levels of representation learning from raw text, semantic entities and location information. The clusters of fused-embedding of job and candidates are then used to build and train the Faiss index that supports runtime approximate nearest neighbor search for candidate retrieval. After the first stage of candidate retrieval, a second stage reranking model that utilizes other contextual information was used to generate the final matching result. Both offline and online evaluation results indicate a significant improvement of our proposed two-staged embedding-based system in terms of click-through rate (CTR), quality and normalized discounted accumulated gain (nDCG), compared to those obtained from our baseline system. We further described the deployment of the system that supports the million-scale job and candidate matching process at CareerBuilder. The overall improvement of our job to candidate matching system has demonstrated its feasibility and scalability at a major online recruitment site.
Automated Discovery and Classification of Training Videos for Career Progression
Jul 23, 2019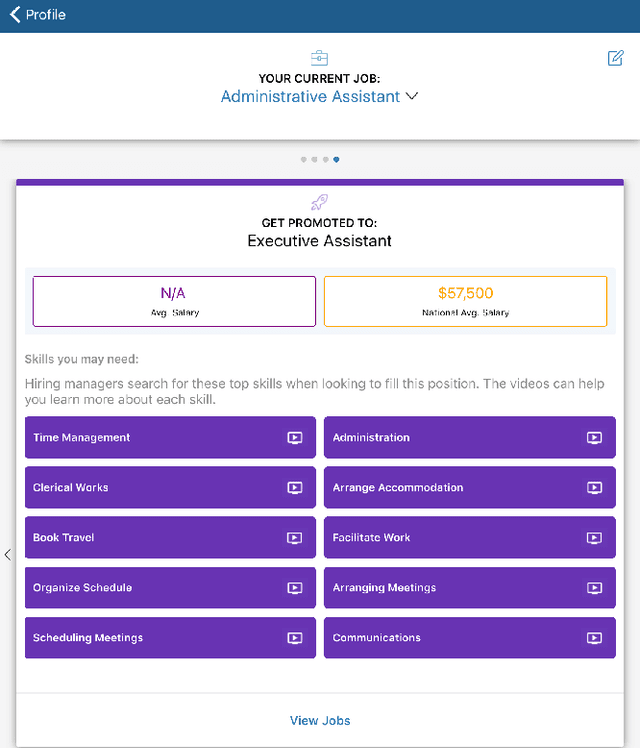
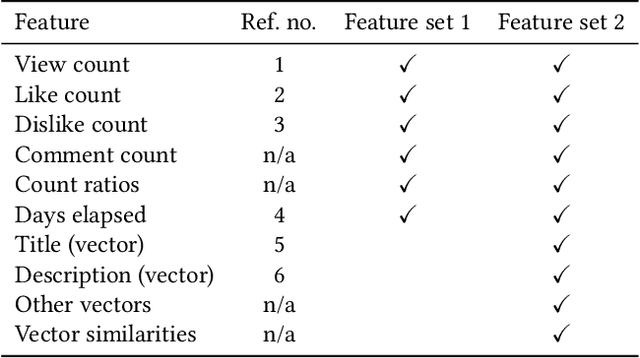


Job transitions and upskilling are common actions taken by many industry working professionals throughout their career. With the current rapidly changing job landscape where requirements are constantly changing and industry sectors are emerging, it is especially difficult to plan and navigate a predetermined career path. In this work, we implemented a system to automate the collection and classification of training videos to help job seekers identify and acquire the skills necessary to transition to the next step in their career. We extracted educational videos and built a machine learning classifier to predict video relevancy. This system allows us to discover relevant videos at a large scale for job title-skill pairs. Our experiments show significant improvements in the model performance by incorporating embedding vectors associated with the video attributes. Additionally, we evaluated the optimal probability threshold to extract as many videos as possible with minimal false positive rate.