 Add to Chrome
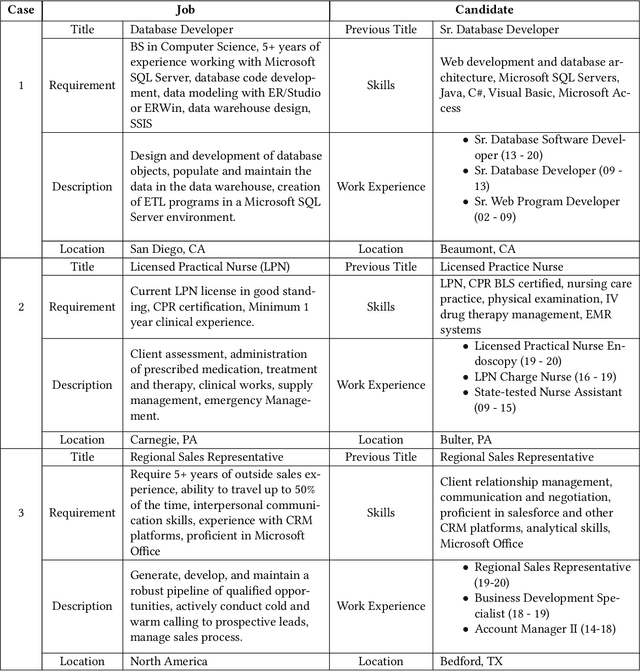
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding-based Recommender System for Job to Candidate Matching on Scale
Jul 01, 2021

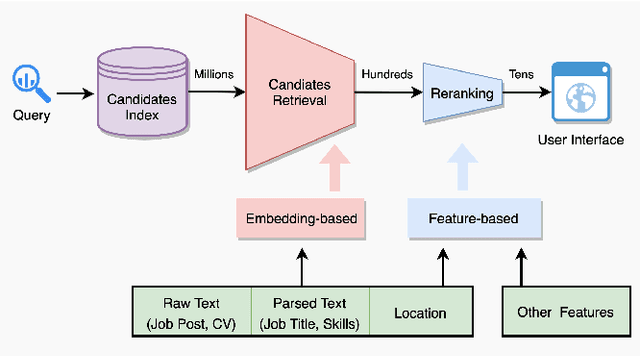
The online recruitment matching system has been the core technology and service platform in CareerBuilder. One of the major challenges in an online recruitment scenario is to provide good matches between job posts and candidates using a recommender system on the scale. In this paper, we discussed the techniques for applying an embedding-based recommender system for the large scale of job to candidates matching. To learn the comprehensive and effective embedding for job posts and candidates, we have constructed a fused-embedding via different levels of representation learning from raw text, semantic entities and location information. The clusters of fused-embedding of job and candidates are then used to build and train the Faiss index that supports runtime approximate nearest neighbor search for candidate retrieval. After the first stage of candidate retrieval, a second stage reranking model that utilizes other contextual information was used to generate the final matching result. Both offline and online evaluation results indicate a significant improvement of our proposed two-staged embedding-based system in terms of click-through rate (CTR), quality and normalized discounted accumulated gain (nDCG), compared to those obtained from our baseline system. We further described the deployment of the system that supports the million-scale job and candidate matching process at CareerBuilder. The overall improvement of our job to candidate matching system has demonstrated its feasibility and scalability at a major online recruitment site.
Tripartite Vector Representations for Better Job Recommendation
Jul 23, 2019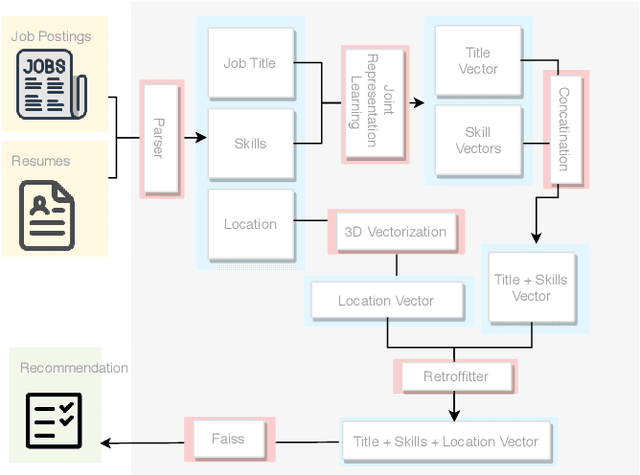
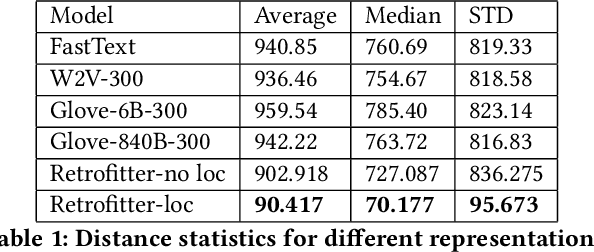
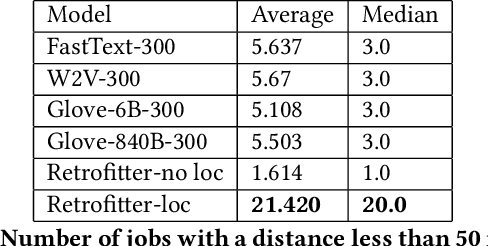
Job recommendation is a crucial part of the online job recruitment business. To match the right person with the right job, a good representation of job postings is required. Such representations should ideally recommend jobs with fitting titles, aligned skill set, and reasonable commute. To address these aspects, we utilize three information graphs ( job-job, skill-skill, job-skill) from historical job data to learn a joint representation for both job titles and skills in a shared latent space. This allows us to gain a representation of job postings/ resume using both elements, which subsequently can be combined with location. In this paper, we first present how the presentation of each component is obtained, and then we discuss how these different representations are combined together into one single space to acquire the final representation. The results of comparing the proposed methodology against different base-line methods show significant improvement in terms of relevancy.