 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLENS: LLM-Enabled Narrative Synthesis for Mental Health by Aligning Multimodal Sensing with Language Models
Dec 28, 2025Multimodal health sensing offers rich behavioral signals for assessing mental health, yet translating these numerical time-series measurements into natural language remains challenging. Current LLMs cannot natively ingest long-duration sensor streams, and paired sensor-text datasets are scarce. To address these challenges, we introduce LENS, a framework that aligns multimodal sensing data with language models to generate clinically grounded mental-health narratives. LENS first constructs a large-scale dataset by transforming Ecological Momentary Assessment (EMA) responses related to depression and anxiety symptoms into natural-language descriptions, yielding over 100,000 sensor-text QA pairs from 258 participants. To enable native time-series integration, we train a patch-level encoder that projects raw sensor signals directly into an LLM's representation space. Our results show that LENS outperforms strong baselines on standard NLP metrics and task-specific measures of symptom-severity accuracy. A user study with 13 mental-health professionals further indicates that LENS-produced narratives are comprehensive and clinically meaningful. Ultimately, our approach advances LLMs as interfaces for health sensing, providing a scalable path toward models that can reason over raw behavioral signals and support downstream clinical decision-making.
Beyond Prompting: Time2Lang -- Bridging Time-Series Foundation Models and Large Language Models for Health Sensing
Feb 12, 2025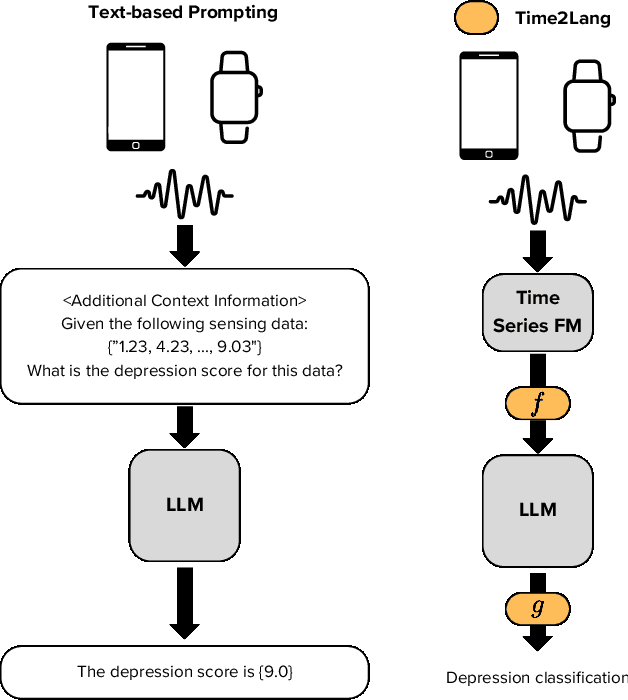
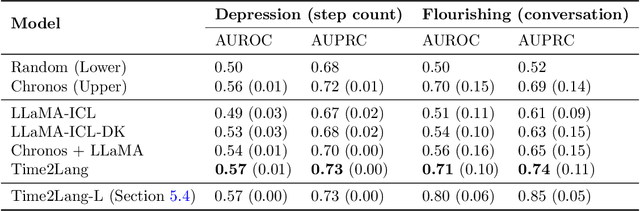
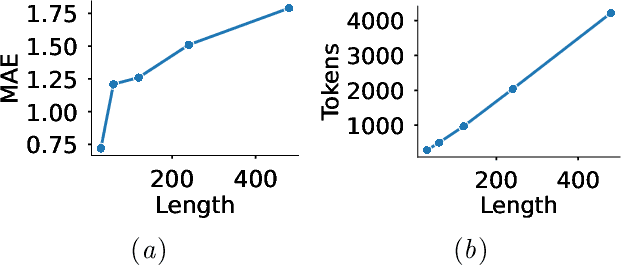

Large language models (LLMs) show promise for health applications when combined with behavioral sensing data. Traditional approaches convert sensor data into text prompts, but this process is prone to errors, computationally expensive, and requires domain expertise. These challenges are particularly acute when processing extended time series data. While time series foundation models (TFMs) have recently emerged as powerful tools for learning representations from temporal data, bridging TFMs and LLMs remains challenging. Here, we present Time2Lang, a framework that directly maps TFM outputs to LLM representations without intermediate text conversion. Our approach first trains on synthetic data using periodicity prediction as a pretext task, followed by evaluation on mental health classification tasks. We validate Time2Lang on two longitudinal wearable and mobile sensing datasets: daily depression prediction using step count data (17,251 days from 256 participants) and flourishing classification based on conversation duration (46 participants over 10 weeks). Time2Lang maintains near constant inference times regardless of input length, unlike traditional prompting methods. The generated embeddings preserve essential time-series characteristics such as auto-correlation. Our results demonstrate that TFMs and LLMs can be effectively integrated while minimizing information loss and enabling performance transfer across these distinct modeling paradigms. To our knowledge, we are the first to integrate a TFM and an LLM for health, thus establishing a foundation for future research combining general-purpose large models for complex healthcare tasks.
Is Attention All You Need For Actigraphy? Foundation Models of Wearable Accelerometer Data for Mental Health Research
Nov 26, 2024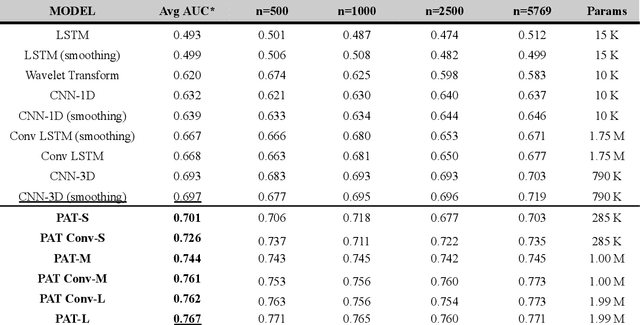
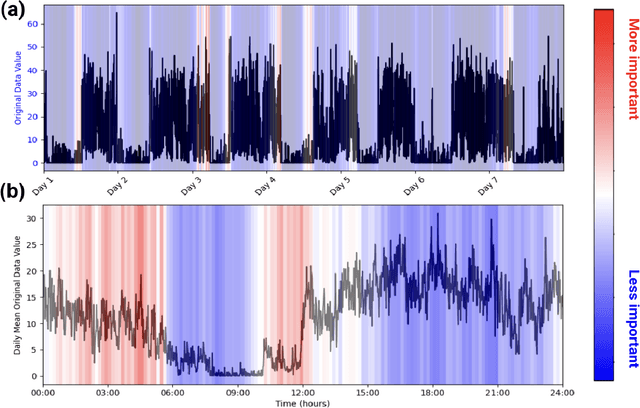
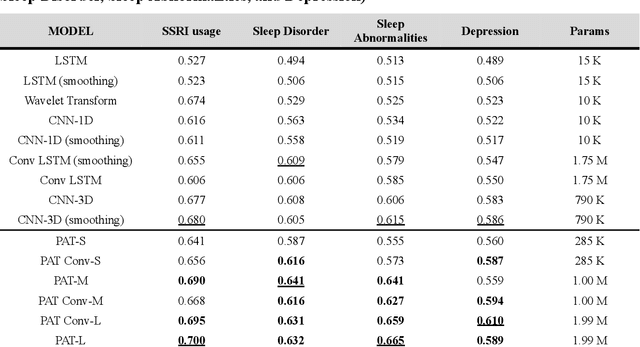
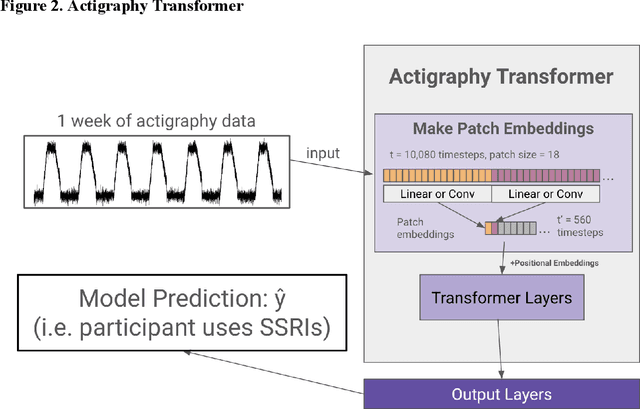
Wearable accelerometry (actigraphy) has provided valuable data for clinical insights since the 1970s and is increasingly important as wearable devices continue to become widespread. The effectiveness of actigraphy in research and clinical contexts is heavily dependent on the modeling architecture utilized. To address this, we developed the Pretrained Actigraphy Transformer (PAT)--the first pretrained and fully attention-based model designed specifically to handle actigraphy. PAT was pretrained on actigraphy from 29,307 participants in NHANES, enabling it to deliver state-of-the-art performance when fine-tuned across various actigraphy prediction tasks in the mental health domain, even in data-limited scenarios. For example, when trained to predict benzodiazepine usage using actigraphy from only 500 labeled participants, PAT achieved an 8.8 percentage-point AUC improvement over the best baseline. With fewer than 2 million parameters and built-in model explainability, PAT is robust yet easy to deploy in health research settings. GitHub: https://github.com/njacobsonlab/Pretrained-Actigraphy-Transformer/