 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFault Diagnosis and Quantification for Photovoltaic Arrays based on Differentiable Physical Models
Dec 18, 2025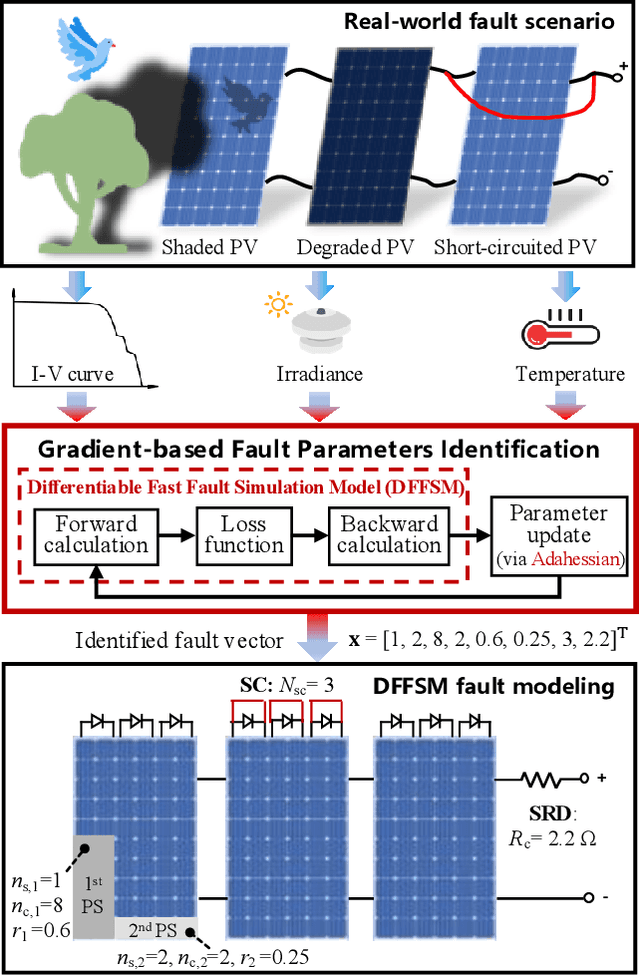
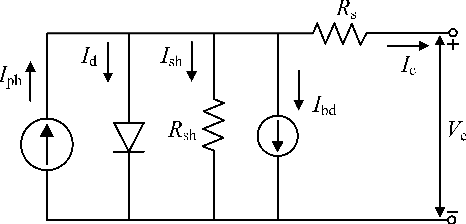
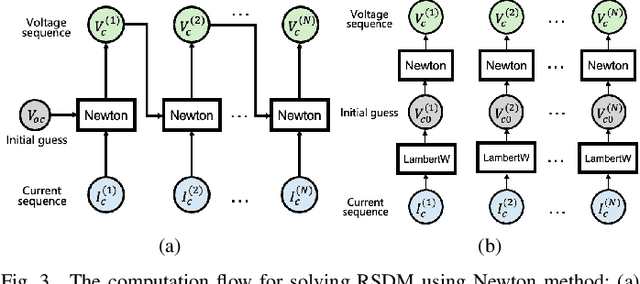
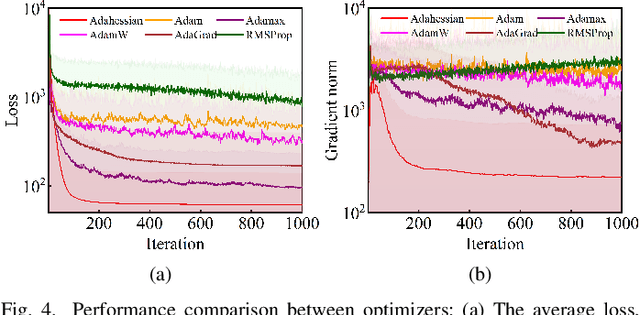
Accurate fault diagnosis and quantification are essential for the reliable operation and intelligent maintenance of photovoltaic (PV) arrays. However, existing fault quantification methods often suffer from limited efficiency and interpretability. To address these challenges, this paper proposes a novel fault quantification approach for PV strings based on a differentiable fast fault simulation model (DFFSM). The proposed DFFSM accurately models I-V characteristics under multiple faults and provides analytical gradients with respect to fault parameters. Leveraging this property, a gradient-based fault parameters identification (GFPI) method using the Adahessian optimizer is developed to efficiently quantify partial shading, short-circuit, and series-resistance degradation. Experimental results on both simulated and measured I-V curves demonstrate that the proposed GFPI achieves high quantification accuracy across different faults, with the I-V reconstruction error below 3%, confirming the feasibility and effectiveness of the application of differentiable physical simulators for PV system fault diagnosis.
RefPentester: A Knowledge-Informed Self-Reflective Penetration Testing Framework Based on Large Language Models
May 14, 2025Automated penetration testing (AutoPT) powered by large language models (LLMs) has gained attention for its ability to automate ethical hacking processes and identify vulnerabilities in target systems by leveraging the intrinsic knowledge of LLMs. However, existing LLM-based AutoPT frameworks often underperform compared to human experts in challenging tasks for several reasons: the imbalanced knowledge used in LLM training, short-sighted planning in the planning process, and hallucinations during command generation. In addition, the penetration testing (PT) process, with its trial-and-error nature, is limited by existing frameworks that lack mechanisms to learn from previous failed operations, restricting adaptive improvement of PT strategies. To address these limitations, we propose a knowledge-informed self-reflective PT framework powered by LLMs, called RefPentester, which is an AutoPT framework designed to assist human operators in identifying the current stage of the PT process, selecting appropriate tactic and technique for the stage, choosing suggested action, providing step-by-step operational guidance, and learning from previous failed operations. We also modeled the PT process as a seven-state Stage Machine to integrate the proposed framework effectively. The evaluation shows that RefPentester can successfully reveal credentials on Hack The Box's Sau machine, outperforming the baseline GPT-4o model by 16.7%. Across PT stages, RefPentester also demonstrates superior success rates on PT stage transitions.
Knowledge-Informed Auto-Penetration Testing Based on Reinforcement Learning with Reward Machine
May 24, 2024



Automated penetration testing (AutoPT) based on reinforcement learning (RL) has proven its ability to improve the efficiency of vulnerability identification in information systems. However, RL-based PT encounters several challenges, including poor sampling efficiency, intricate reward specification, and limited interpretability. To address these issues, we propose a knowledge-informed AutoPT framework called DRLRM-PT, which leverages reward machines (RMs) to encode domain knowledge as guidelines for training a PT policy. In our study, we specifically focus on lateral movement as a PT case study and formulate it as a partially observable Markov decision process (POMDP) guided by RMs. We design two RMs based on the MITRE ATT\&CK knowledge base for lateral movement. To solve the POMDP and optimize the PT policy, we employ the deep Q-learning algorithm with RM (DQRM). The experimental results demonstrate that the DQRM agent exhibits higher training efficiency in PT compared to agents without knowledge embedding. Moreover, RMs encoding more detailed domain knowledge demonstrated better PT performance compared to RMs with simpler knowledge.