 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAC: 2D-3D Retrieval with Noisy Labels via Divide-and-Conquer Alignment and Correction
Paper and Code
Jul 25, 2024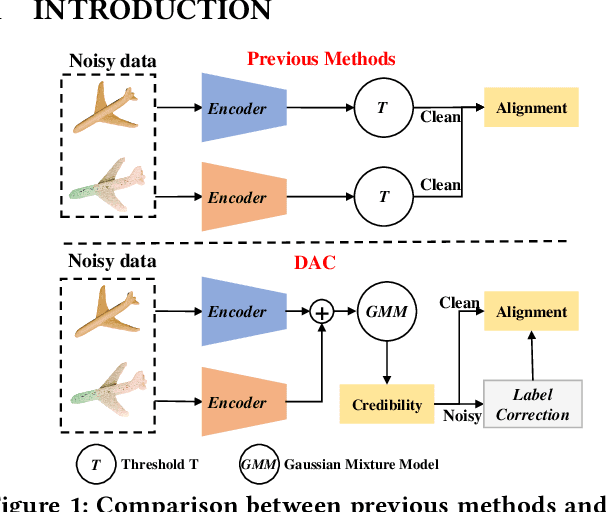

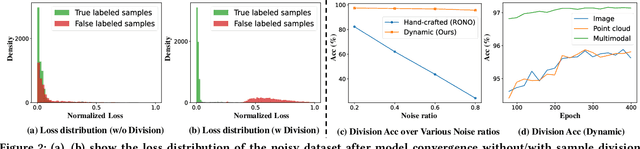

With the recent burst of 2D and 3D data, cross-modal retrieval has attracted increasing attention recently. However, manual labeling by non-experts will inevitably introduce corrupted annotations given ambiguous 2D/3D content. Though previous works have addressed this issue by designing a naive division strategy with hand-crafted thresholds, their performance generally exhibits great sensitivity to the threshold value. Besides, they fail to fully utilize the valuable supervisory signals within each divided subset. To tackle this problem, we propose a Divide-and-conquer 2D-3D cross-modal Alignment and Correction framework (DAC), which comprises Multimodal Dynamic Division (MDD) and Adaptive Alignment and Correction (AAC). Specifically, the former performs accurate sample division by adaptive credibility modeling for each sample based on the compensation information within multimodal loss distribution. Then in AAC, samples in distinct subsets are exploited with different alignment strategies to fully enhance the semantic compactness and meanwhile alleviate over-fitting to noisy labels, where a self-correction strategy is introduced to improve the quality of representation. Moreover. To evaluate the effectiveness in real-world scenarios, we introduce a challenging noisy benchmark, namely Objaverse-N200, which comprises 200k-level samples annotated with 1156 realistic noisy labels. Extensive experiments on both traditional and the newly proposed benchmarks demonstrate the generality and superiority of our DAC, where DAC outperforms state-of-the-art models by a large margin. (i.e., with +5.9% gain on ModelNet40 and +5.8% on Objaverse-N200).