 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Language Barriers: Cross-Lingual Continual Pre-Training at Scale
Jul 02, 2024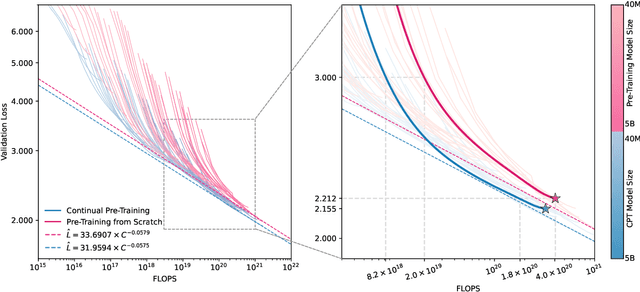
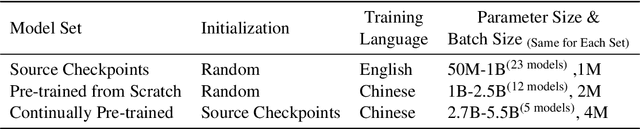
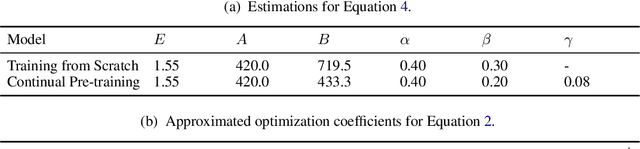
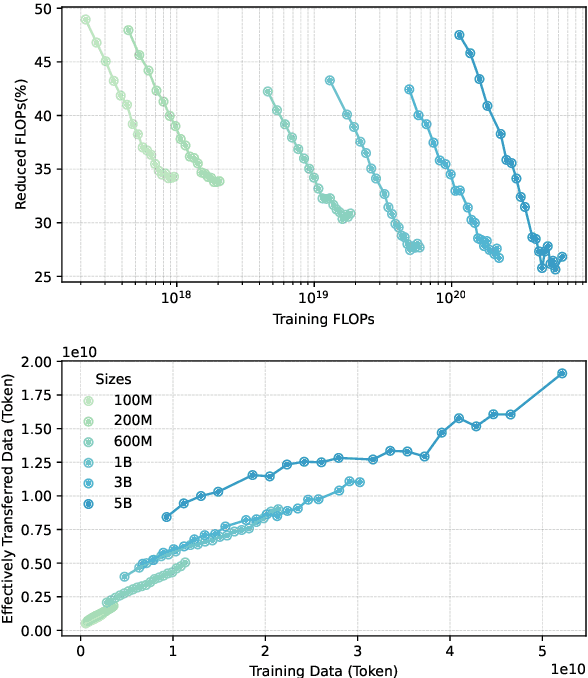
In recent years, Large Language Models (LLMs) have made significant strides towards Artificial General Intelligence. However, training these models from scratch requires substantial computational resources and vast amounts of text data. In this paper, we explore an alternative approach to constructing an LLM for a new language by continually pretraining (CPT) from existing pretrained LLMs, instead of using randomly initialized parameters. Based on parallel experiments on 40 model sizes ranging from 40M to 5B parameters, we find that 1) CPT converges faster and saves significant resources in a scalable manner; 2) CPT adheres to an extended scaling law derived from Hoffmann et al. (2022) with a joint data-parameter scaling term; 3) The compute-optimal data-parameter allocation for CPT markedly differs based on our estimated scaling factors; 4) The effectiveness of transfer at scale is influenced by training duration and linguistic properties, while robust to data replaying, a method that effectively mitigates catastrophic forgetting in CPT. We hope our findings provide deeper insights into the transferability of LLMs at scale for the research community.
Really should we pruning after model be totally trained? Pruning based on a small amount of training
Jan 24, 2019
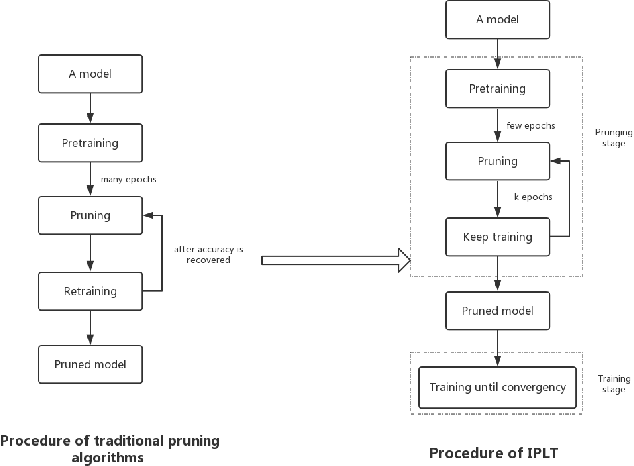
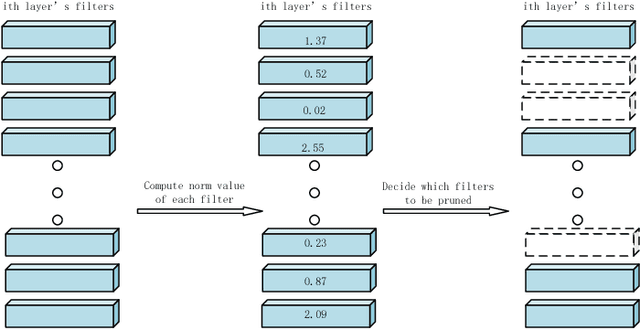
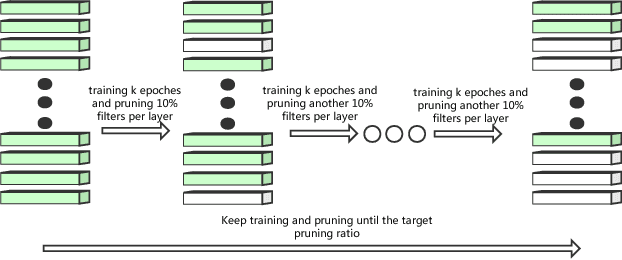
Pre-training of models in pruning algorithms plays an important role in pruning decision-making. We find that excessive pre-training is not necessary for pruning algorithms. According to this idea, we propose a pruning algorithm---Incremental pruning based on less training (IPLT). Compared with the traditional pruning algorithm based on a large number of pre-training, IPLT has competitive compression effect than the traditional pruning algorithm under the same simple pruning strategy. On the premise of ensuring accuracy, IPLT can achieve 8x-9x compression for VGG-19 on CIFAR-10 and only needs to pre-train few epochs. For VGG-19 on CIFAR-10, we can not only achieve 10 times test acceleration, but also about 10 times training acceleration. At present, the research mainly focuses on the compression and acceleration in the application stage of the model, while the compression and acceleration in the training stage are few. We newly proposed a pruning algorithm that can compress and accelerate in the training stage. It is novel to consider the amount of pre-training required by pruning algorithm. Our results have implications: Too much pre-training may be not necessary for pruning algorithms.