 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^\star$: Every Task Deserves Its Own Memory Harness
Apr 10, 2026Large language model agents rely on specialized memory systems to accumulate and reuse knowledge during extended interactions. Recent architectures typically adopt a fixed memory design tailored to specific domains, such as semantic retrieval for conversations or skills reused for coding. However, a memory system optimized for one purpose frequently fails to transfer to others. To address this limitation, we introduce M$^\star$, a method that automatically discovers task-optimized memory harnesses through executable program evolution. Specifically, M$^\star$ models an agent memory system as a memory program written in Python. This program encapsulates the data Schema, the storage Logic, and the agent workflow Instructions. We optimize these components jointly using a reflective code evolution method; this approach employs a population-based search strategy and analyzes evaluation failures to iteratively refine the candidate programs. We evaluate M$^\star$ on four distinct benchmarks spanning conversation, embodied planning, and expert reasoning. Our results demonstrate that M$^\star$ improves performance over existing fixed-memory baselines robustly across all evaluated tasks. Furthermore, the evolved memory programs exhibit structurally distinct processing mechanisms for each domain. This finding indicates that specializing the memory mechanism for a given task explores a broad design space and provides a superior solution compared to general-purpose memory paradigms.
Towards Long-Horizon Interpretability: Efficient and Faithful Multi-Token Attribution for Reasoning LLMs
Feb 02, 2026Token attribution methods provide intuitive explanations for language model outputs by identifying causally important input tokens. However, as modern LLMs increasingly rely on extended reasoning chains, existing schemes face two critical challenges: (1) efficiency bottleneck, where attributing a target span of M tokens within a context of length N requires O(M*N) operations, making long-context attribution prohibitively slow; and (2) faithfulness drop, where intermediate reasoning tokens absorb attribution mass, preventing importance from propagating back to the original input. To address these, we introduce FlashTrace, an efficient multi-token attribution method that employs span-wise aggregation to compute attribution over multi-token targets in a single pass, while maintaining faithfulness. Moreover, we design a recursive attribution mechanism that traces importance through intermediate reasoning chains back to source inputs. Extensive experiments on long-context retrieval (RULER) and multi-step reasoning (MATH, MorehopQA) tasks demonstrate that FlashTrace achieves over 130x speedup over existing baselines while maintaining superior faithfulness. We further analyze the dynamics of recursive attribution, showing that even a single recursive hop improves faithfulness by tracing importance through the reasoning chain.
Can LLMs Refuse Questions They Do Not Know? Measuring Knowledge-Aware Refusal in Factual Tasks
Oct 02, 2025Large Language Models (LLMs) should refuse to answer questions beyond their knowledge. This capability, which we term knowledge-aware refusal, is crucial for factual reliability. However, existing metrics fail to faithfully measure this ability. On the one hand, simple refusal-based metrics are biased by refusal rates and yield inconsistent scores when models exhibit different refusal tendencies. On the other hand, existing calibration metrics are proxy-based, capturing the performance of auxiliary calibration processes rather than the model's actual refusal behavior. In this work, we propose the Refusal Index (RI), a principled metric that measures how accurately LLMs refuse questions they do not know. We define RI as Spearman's rank correlation between refusal probability and error probability. To make RI practically measurable, we design a lightweight two-pass evaluation method that efficiently estimates RI from observed refusal rates across two standard evaluation runs. Extensive experiments across 16 models and 5 datasets demonstrate that RI accurately quantifies a model's intrinsic knowledge-aware refusal capability in factual tasks. Notably, RI remains stable across different refusal rates and provides consistent model rankings independent of a model's overall accuracy and refusal rates. More importantly, RI provides insight into an important but previously overlooked aspect of LLM factuality: while LLMs achieve high accuracy on factual tasks, their refusal behavior can be unreliable and fragile. This finding highlights the need to complement traditional accuracy metrics with the Refusal Index for comprehensive factuality evaluation.
Breaking Language Barriers: Cross-Lingual Continual Pre-Training at Scale
Jul 02, 2024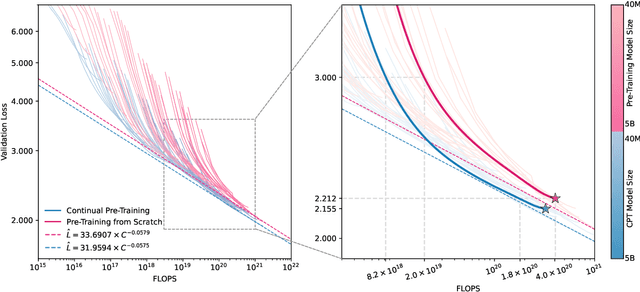
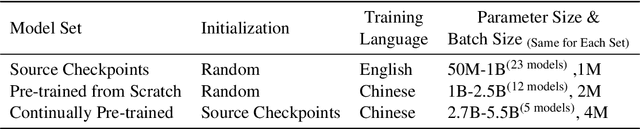
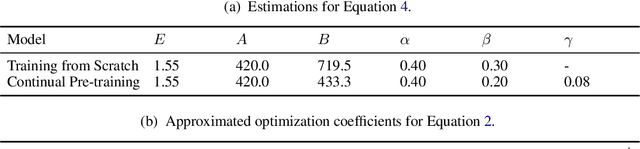
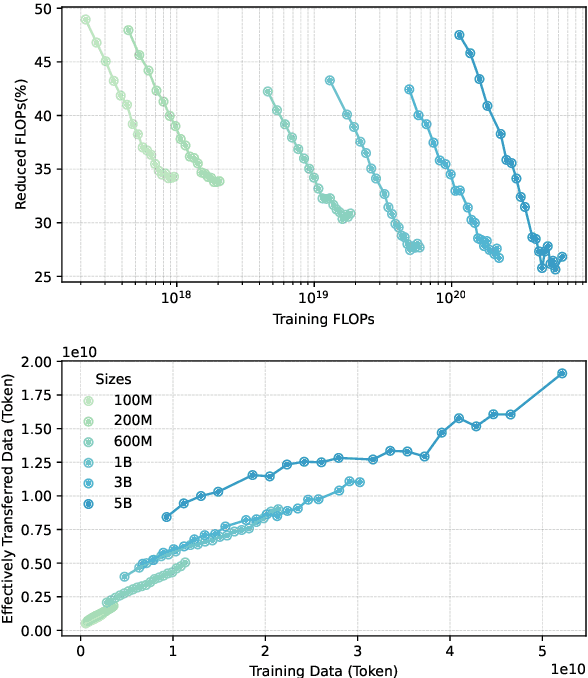
In recent years, Large Language Models (LLMs) have made significant strides towards Artificial General Intelligence. However, training these models from scratch requires substantial computational resources and vast amounts of text data. In this paper, we explore an alternative approach to constructing an LLM for a new language by continually pretraining (CPT) from existing pretrained LLMs, instead of using randomly initialized parameters. Based on parallel experiments on 40 model sizes ranging from 40M to 5B parameters, we find that 1) CPT converges faster and saves significant resources in a scalable manner; 2) CPT adheres to an extended scaling law derived from Hoffmann et al. (2022) with a joint data-parameter scaling term; 3) The compute-optimal data-parameter allocation for CPT markedly differs based on our estimated scaling factors; 4) The effectiveness of transfer at scale is influenced by training duration and linguistic properties, while robust to data replaying, a method that effectively mitigates catastrophic forgetting in CPT. We hope our findings provide deeper insights into the transferability of LLMs at scale for the research community.
End-to-end Task-oriented Dialogue: A Survey of Tasks, Methods, and Future Directions
Nov 15, 2023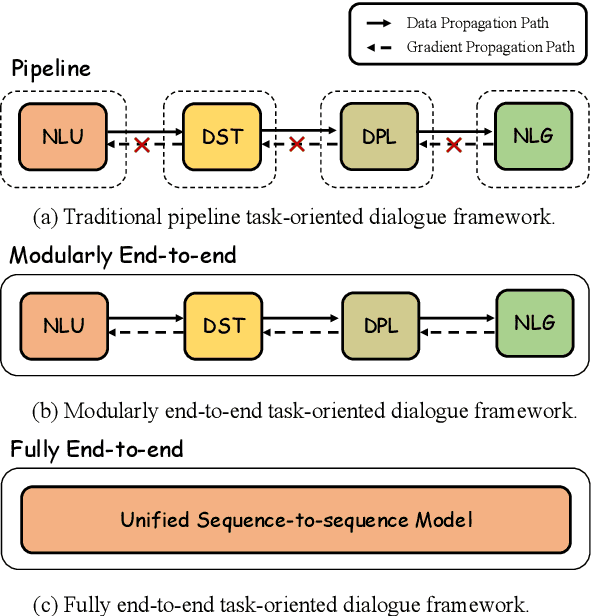
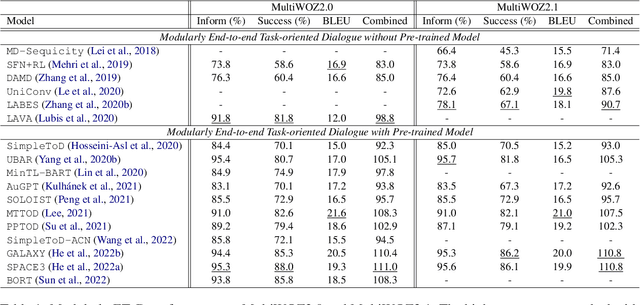
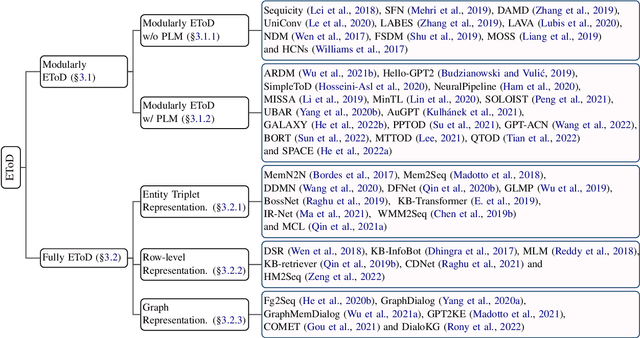
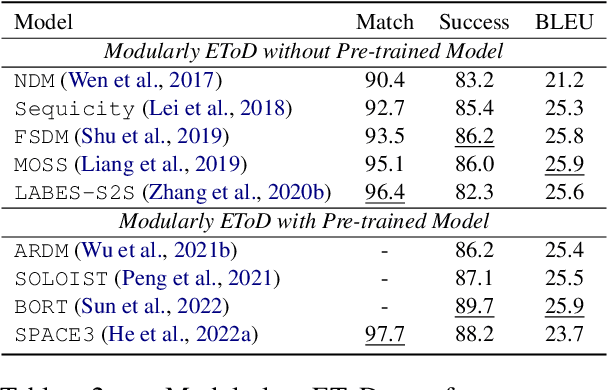
End-to-end task-oriented dialogue (EToD) can directly generate responses in an end-to-end fashion without modular training, which attracts escalating popularity. The advancement of deep neural networks, especially the successful use of large pre-trained models, has further led to significant progress in EToD research in recent years. In this paper, we present a thorough review and provide a unified perspective to summarize existing approaches as well as recent trends to advance the development of EToD research. The contributions of this paper can be summarized: (1) \textbf{\textit{First survey}}: to our knowledge, we take the first step to present a thorough survey of this research field; (2) \textbf{\textit{New taxonomy}}: we first introduce a unified perspective for EToD, including (i) \textit{Modularly EToD} and (ii) \textit{Fully EToD}; (3) \textbf{\textit{New Frontiers}}: we discuss some potential frontier areas as well as the corresponding challenges, hoping to spur breakthrough research in EToD field; (4) \textbf{\textit{Abundant resources}}: we build a public website\footnote{We collect the related papers, baseline projects, and leaderboards for the community at \url{https://etods.net/}.}, where EToD researchers could directly access the recent progress. We hope this work can serve as a thorough reference for the EToD research community.
A Preliminary Evaluation of ChatGPT for Zero-shot Dialogue Understanding
Apr 09, 2023



Zero-shot dialogue understanding aims to enable dialogue to track the user's needs without any training data, which has gained increasing attention. In this work, we investigate the understanding ability of ChatGPT for zero-shot dialogue understanding tasks including spoken language understanding (SLU) and dialogue state tracking (DST). Experimental results on four popular benchmarks reveal the great potential of ChatGPT for zero-shot dialogue understanding. In addition, extensive analysis shows that ChatGPT benefits from the multi-turn interactive prompt in the DST task but struggles to perform slot filling for SLU. Finally, we summarize several unexpected behaviors of ChatGPT in dialogue understanding tasks, hoping to provide some insights for future research on building zero-shot dialogue understanding systems with Large Language Models (LLMs).