 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTT-GaussOcc: Test-Time Compute for Self-Supervised Occupancy Prediction via Spatio-Temporal Gaussian Splatting
Paper and Code
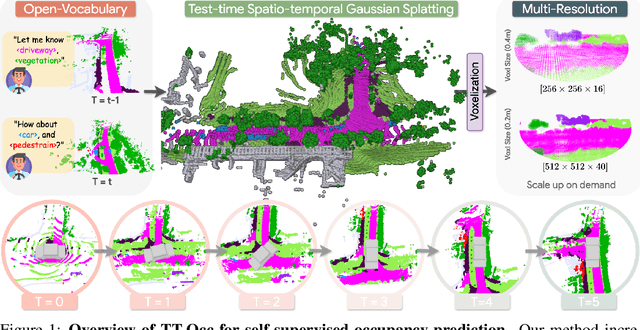


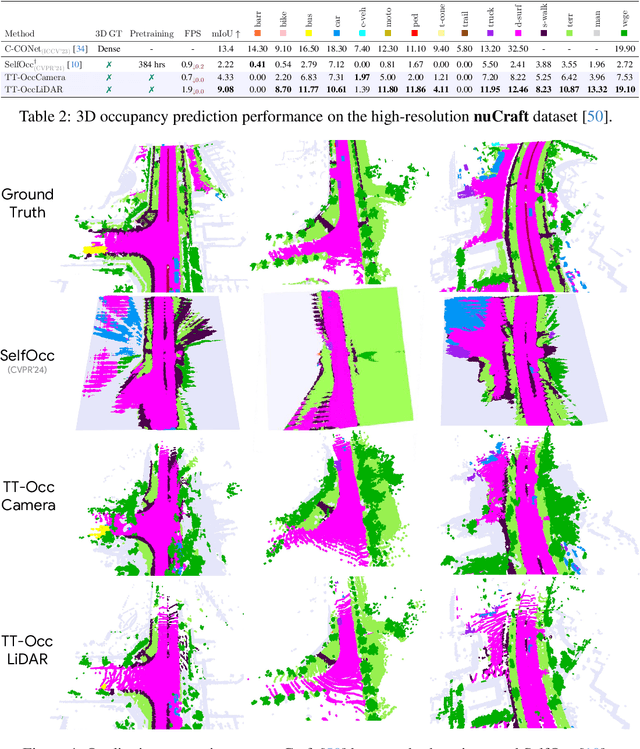
Self-supervised 3D occupancy prediction offers a promising solution for understanding complex driving scenes without requiring costly 3D annotations. However, training dense voxel decoders to capture fine-grained geometry and semantics can demand hundreds of GPU hours, and such models often fail to adapt to varying voxel resolutions or new classes without extensive retraining. To overcome these limitations, we propose a practical and flexible test-time occupancy prediction framework termed TT-GaussOcc. Our approach incrementally optimizes time-aware 3D Gaussians instantiated from raw sensor streams at runtime, enabling voxelization at arbitrary user-specified resolution. Specifically, TT-GaussOcc operates in a "lift-move-voxel" symphony: we first "lift" surrounding-view semantics obtained from 2D vision foundation models (VLMs) to instantiate Gaussians at non-empty 3D space; Next, we "move" dynamic Gaussians from previous frames along estimated Gaussian scene flow to complete appearance and eliminate trailing artifacts of fast-moving objects, while accumulating static Gaussians to enforce temporal consistency; Finally, we mitigate inherent noises in semantic predictions and scene flow vectors by periodically smoothing neighboring Gaussians during optimization, using proposed trilateral RBF kernels that jointly consider color, semantic, and spatial affinities. The historical static and current dynamic Gaussians are then combined and voxelized to generate occupancy prediction. Extensive experiments on Occ3D and nuCraft with varying voxel resolutions demonstrate that TT-GaussOcc surpasses self-supervised baselines by 46% on mIoU without any offline training, and supports finer voxel resolutions at 2.6 FPS inference speed.