 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi and Weakly Supervised Semantic Segmentation Using Generative Adversarial Network
Paper and Code
Mar 28, 2017
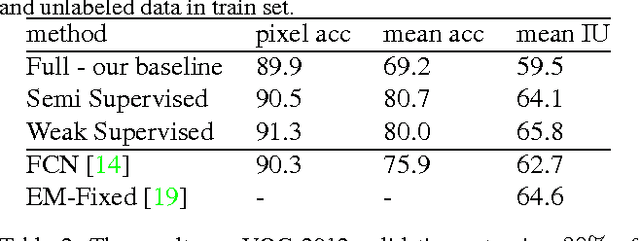


Semantic segmentation has been a long standing challenging task in computer vision. It aims at assigning a label to each image pixel and needs significant number of pixellevel annotated data, which is often unavailable. To address this lack, in this paper, we leverage, on one hand, massive amount of available unlabeled or weakly labeled data, and on the other hand, non-real images created through Generative Adversarial Networks. In particular, we propose a semi-supervised framework ,based on Generative Adversarial Networks (GANs), which consists of a generator network to provide extra training examples to a multi-class classifier, acting as discriminator in the GAN framework, that assigns sample a label y from the K possible classes or marks it as a fake sample (extra class). The underlying idea is that adding large fake visual data forces real samples to be close in the feature space, enabling a bottom-up clustering process, which, in turn, improves multiclass pixel classification. To ensure higher quality of generated images for GANs with consequent improved pixel classification, we extend the above framework by adding weakly annotated data, i.e., we provide class level information to the generator. We tested our approaches on several challenging benchmarking visual datasets, i.e. PASCAL, SiftFLow, Stanford and CamVid, achieving competitive performance also compared to state-of-the-art semantic segmentation method