 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArt2Mus: Artwork-to-Music Generation via Visual Conditioning and Large-Scale Cross-Modal Alignment
Feb 19, 2026Music generation has advanced markedly through multimodal deep learning, enabling models to synthesize audio from text and, more recently, from images. However, existing image-conditioned systems suffer from two fundamental limitations: (i) they are typically trained on natural photographs, limiting their ability to capture the richer semantic, stylistic, and cultural content of artworks; and (ii) most rely on an image-to-text conversion stage, using language as a semantic shortcut that simplifies conditioning but prevents direct visual-to-audio learning. Motivated by these gaps, we introduce ArtSound, a large-scale multimodal dataset of 105,884 artwork-music pairs enriched with dual-modality captions, obtained by extending ArtGraph and the Free Music Archive. We further propose ArtToMus, the first framework explicitly designed for direct artwork-to-music generation, which maps digitized artworks to music without image-to-text translation or language-based semantic supervision. The framework projects visual embeddings into the conditioning space of a latent diffusion model, enabling music synthesis guided solely by visual information. Experimental results show that ArtToMus generates musically coherent and stylistically consistent outputs that reflect salient visual cues of the source artworks. While absolute alignment scores remain lower than those of text-conditioned systems-as expected given the substantially increased difficulty of removing linguistic supervision-ArtToMus achieves competitive perceptual quality and meaningful cross-modal correspondence. This work establishes direct visual-to-music generation as a distinct and challenging research direction, and provides resources that support applications in multimedia art, cultural heritage, and AI-assisted creative practice. Code and dataset will be publicly released upon acceptance.
Take a Peek: Efficient Encoder Adaptation for Few-Shot Semantic Segmentation via LoRA
Dec 11, 2025Few-shot semantic segmentation (FSS) aims to segment novel classes in query images using only a small annotated support set. While prior research has mainly focused on improving decoders, the encoder's limited ability to extract meaningful features for unseen classes remains a key bottleneck. In this work, we introduce \textit{Take a Peek} (TaP), a simple yet effective method that enhances encoder adaptability for both FSS and cross-domain FSS (CD-FSS). TaP leverages Low-Rank Adaptation (LoRA) to fine-tune the encoder on the support set with minimal computational overhead, enabling fast adaptation to novel classes while mitigating catastrophic forgetting. Our method is model-agnostic and can be seamlessly integrated into existing FSS pipelines. Extensive experiments across multiple benchmarks--including COCO $20^i$, Pascal $5^i$, and cross-domain datasets such as DeepGlobe, ISIC, and Chest X-ray--demonstrate that TaP consistently improves segmentation performance across diverse models and shot settings. Notably, TaP delivers significant gains in complex multi-class scenarios, highlighting its practical effectiveness in realistic settings. A rank sensitivity analysis also shows that strong performance can be achieved even with low-rank adaptations, ensuring computational efficiency. By addressing a critical limitation in FSS--the encoder's generalization to novel classes--TaP paves the way toward more robust, efficient, and generalizable segmentation systems. The code is available at https://github.com/pasqualedem/TakeAPeek.
LAYA: Layer-wise Attention Aggregation for Interpretable Depth-Aware Neural Networks
Nov 16, 2025Deep neural networks typically rely on the representation produced by their final hidden layer to make predictions, implicitly assuming that this single vector fully captures the semantics encoded across all preceding transformations. However, intermediate layers contain rich and complementary information -- ranging from low-level patterns to high-level abstractions -- that is often discarded when the decision head depends solely on the last representation. This paper revisits the role of the output layer and introduces LAYA (Layer-wise Attention Aggregator), a novel output head that dynamically aggregates internal representations through attention. Instead of projecting only the deepest embedding, LAYA learns input-conditioned attention weights over layer-wise features, yielding an interpretable and architecture-agnostic mechanism for synthesizing predictions. Experiments on vision and language benchmarks show that LAYA consistently matches or improves the performance of standard output heads, with relative gains of up to about one percentage point in accuracy, while providing explicit layer-attribution scores that reveal how different abstraction levels contribute to each decision. Crucially, these interpretability signals emerge directly from the model's computation, without any external post hoc explanations. The code to reproduce LAYA is publicly available at: https://github.com/gvessio/LAYA.
ArtSeek: Deep artwork understanding via multimodal in-context reasoning and late interaction retrieval
Jul 29, 2025Analyzing digitized artworks presents unique challenges, requiring not only visual interpretation but also a deep understanding of rich artistic, contextual, and historical knowledge. We introduce ArtSeek, a multimodal framework for art analysis that combines multimodal large language models with retrieval-augmented generation. Unlike prior work, our pipeline relies only on image input, enabling applicability to artworks without links to Wikidata or Wikipedia-common in most digitized collections. ArtSeek integrates three key components: an intelligent multimodal retrieval module based on late interaction retrieval, a contrastive multitask classification network for predicting artist, genre, style, media, and tags, and an agentic reasoning strategy enabled through in-context examples for complex visual question answering and artwork explanation via Qwen2.5-VL. Central to this approach is WikiFragments, a Wikipedia-scale dataset of image-text fragments curated to support knowledge-grounded multimodal reasoning. Our framework achieves state-of-the-art results on multiple benchmarks, including a +8.4% F1 improvement in style classification over GraphCLIP and a +7.1 BLEU@1 gain in captioning on ArtPedia. Qualitative analyses show that ArtSeek can interpret visual motifs, infer historical context, and retrieve relevant knowledge, even for obscure works. Though focused on visual arts, our approach generalizes to other domains requiring external knowledge, supporting scalable multimodal AI research. Both the dataset and the source code will be made publicly available at https://github.com/cilabuniba/artseek.
I Dream My Painting: Connecting MLLMs and Diffusion Models via Prompt Generation for Text-Guided Multi-Mask Inpainting
Nov 28, 2024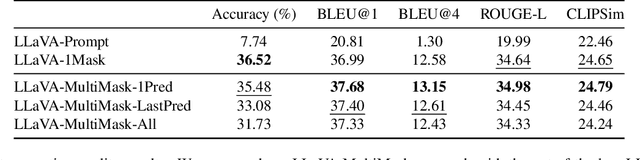
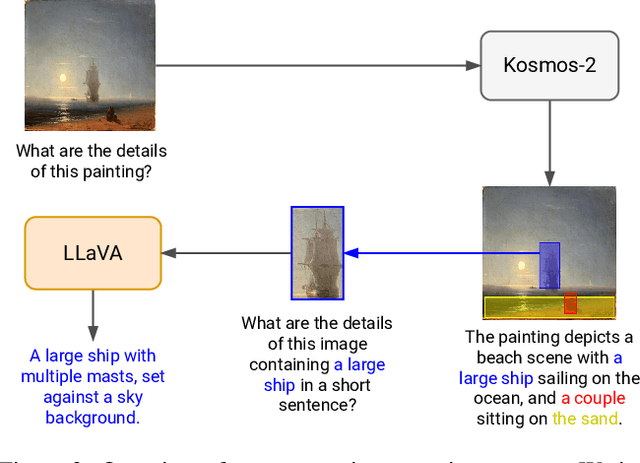

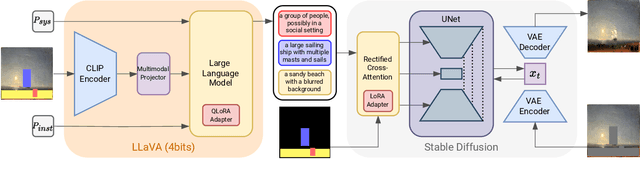
Inpainting focuses on filling missing or corrupted regions of an image to blend seamlessly with its surrounding content and style. While conditional diffusion models have proven effective for text-guided inpainting, we introduce the novel task of multi-mask inpainting, where multiple regions are simultaneously inpainted using distinct prompts. Furthermore, we design a fine-tuning procedure for multimodal LLMs, such as LLaVA, to generate multi-mask prompts automatically using corrupted images as inputs. These models can generate helpful and detailed prompt suggestions for filling the masked regions. The generated prompts are then fed to Stable Diffusion, which is fine-tuned for the multi-mask inpainting problem using rectified cross-attention, enforcing prompts onto their designated regions for filling. Experiments on digitized paintings from WikiArt and the Densely Captioned Images dataset demonstrate that our pipeline delivers creative and accurate inpainting results. Our code, data, and trained models are available at https://cilabuniba.github.io/i-dream-my-painting.
Neural network modelling of kinematic and dynamic features for signature verification
Nov 26, 2024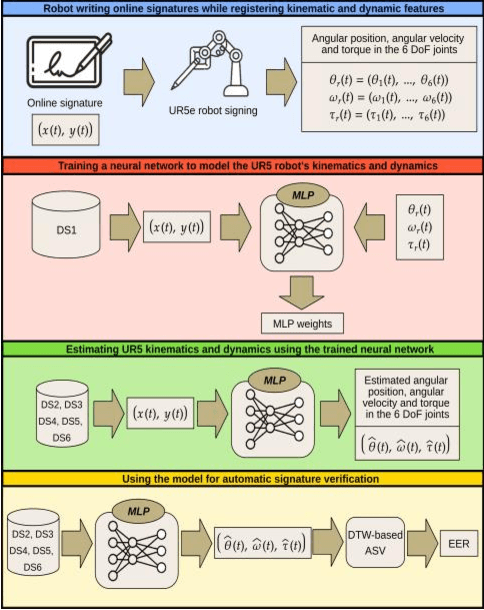
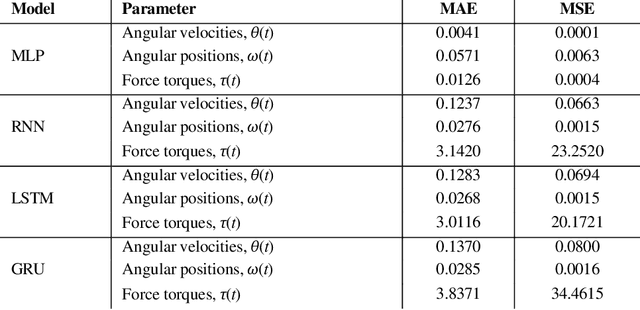
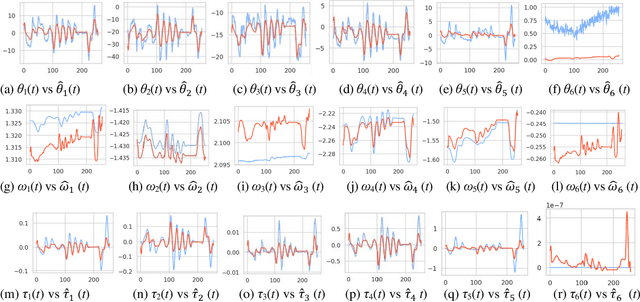
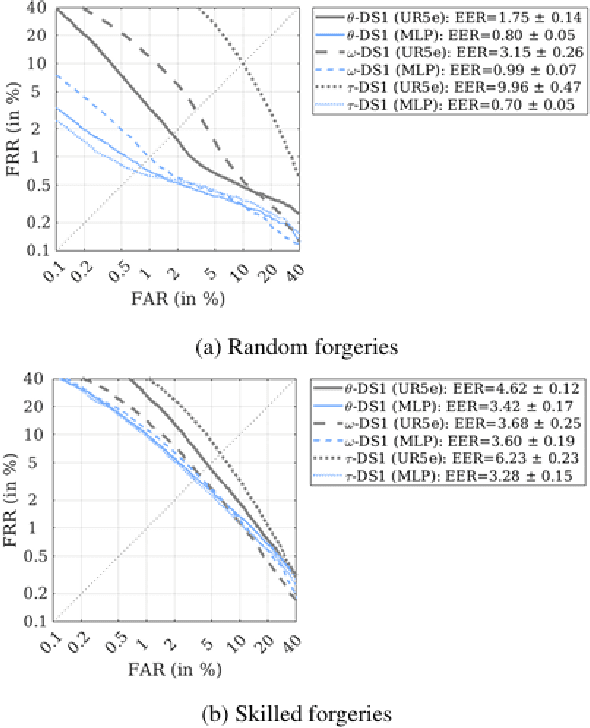
Online signature parameters, which are based on human characteristics, broaden the applicability of an automatic signature verifier. Although kinematic and dynamic features have previously been suggested, accurately measuring features such as arm and forearm torques remains challenging. We present two approaches for estimating angular velocities, angular positions, and force torques. The first approach involves using a physical UR5e robotic arm to reproduce a signature while capturing those parameters over time. The second method, a cost effective approach, uses a neural network to estimate the same parameters. Our findings demonstrate that a simple neural network model can extract effective parameters for signature verification. Training the neural network with the MCYT300 dataset and cross validating with other databases, namely, BiosecurID, Visual, Blind, OnOffSigDevanagari 75 and OnOffSigBengali 75 confirm the models generalization capability.
Art2Mus: Bridging Visual Arts and Music through Cross-Modal Generation
Oct 07, 2024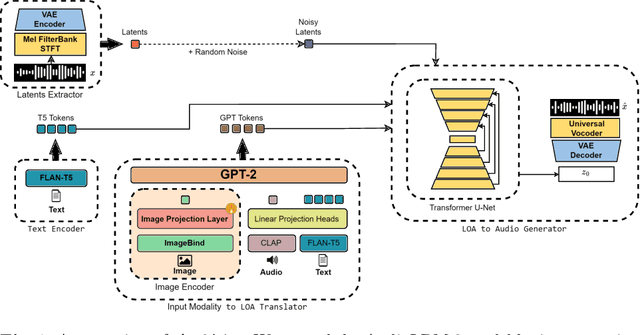

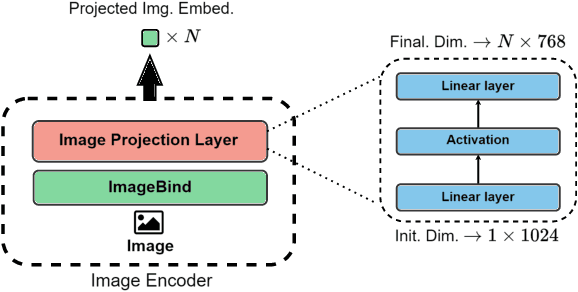

Artificial Intelligence and generative models have revolutionized music creation, with many models leveraging textual or visual prompts for guidance. However, existing image-to-music models are limited to simple images, lacking the capability to generate music from complex digitized artworks. To address this gap, we introduce $\mathcal{A}\textit{rt2}\mathcal{M}\textit{us}$, a novel model designed to create music from digitized artworks or text inputs. $\mathcal{A}\textit{rt2}\mathcal{M}\textit{us}$ extends the AudioLDM~2 architecture, a text-to-audio model, and employs our newly curated datasets, created via ImageBind, which pair digitized artworks with music. Experimental results demonstrate that $\mathcal{A}\textit{rt2}\mathcal{M}\textit{us}$ can generate music that resonates with the input stimuli. These findings suggest promising applications in multimedia art, interactive installations, and AI-driven creative tools.
What is the Relationship between Tensor Factorizations and Circuits (and How Can We Exploit it)?
Sep 12, 2024



This paper establishes a rigorous connection between circuit representations and tensor factorizations, two seemingly distinct yet fundamentally related areas. By connecting these fields, we highlight a series of opportunities that can benefit both communities. Our work generalizes popular tensor factorizations within the circuit language, and unifies various circuit learning algorithms under a single, generalized hierarchical factorization framework. Specifically, we introduce a modular "Lego block" approach to build tensorized circuit architectures. This, in turn, allows us to systematically construct and explore various circuit and tensor factorization models while maintaining tractability. This connection not only clarifies similarities and differences in existing models, but also enables the development of a comprehensive pipeline for building and optimizing new circuit/tensor factorization architectures. We show the effectiveness of our framework through extensive empirical evaluations, and highlight new research opportunities for tensor factorizations in probabilistic modeling.
Label Anything: Multi-Class Few-Shot Semantic Segmentation with Visual Prompts
Jul 02, 2024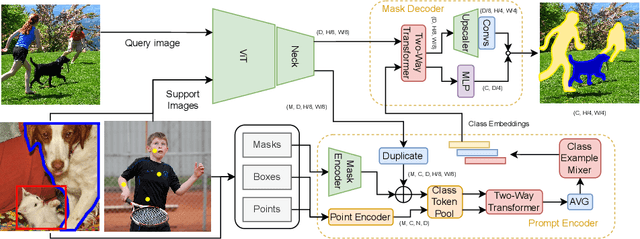
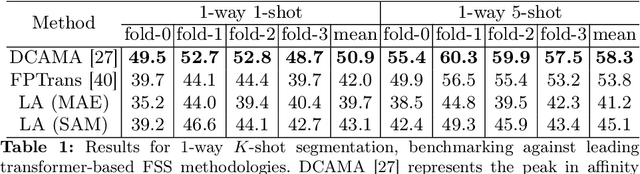
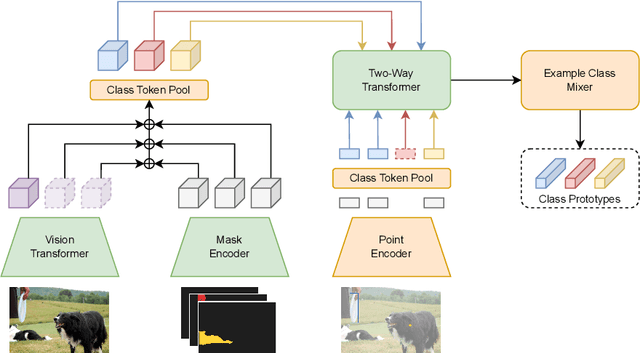

We present Label Anything, an innovative neural network architecture designed for few-shot semantic segmentation (FSS) that demonstrates remarkable generalizability across multiple classes with minimal examples required per class. Diverging from traditional FSS methods that predominantly rely on masks for annotating support images, Label Anything introduces varied visual prompts -- points, bounding boxes, and masks -- thereby enhancing the framework's versatility and adaptability. Unique to our approach, Label Anything is engineered for end-to-end training across multi-class FSS scenarios, efficiently learning from diverse support set configurations without retraining. This approach enables a "universal" application to various FSS challenges, ranging from $1$-way $1$-shot to complex $N$-way $K$-shot configurations while remaining agnostic to the specific number of class examples. This innovative training strategy reduces computational requirements and substantially improves the model's adaptability and generalization across diverse segmentation tasks. Our comprehensive experimental validation, particularly achieving state-of-the-art results on the COCO-$20^i$ benchmark, underscores Label Anything's robust generalization and flexibility. The source code is publicly available at: https://github.com/pasqualedem/LabelAnything.
Dynamically enhanced static handwriting representation for Parkinson's disease detection
May 22, 2024Computer aided diagnosis systems can provide non-invasive, low-cost tools to support clinicians. These systems have the potential to assist the diagnosis and monitoring of neurodegenerative disorders, in particular Parkinson's disease (PD). Handwriting plays a special role in the context of PD assessment. In this paper, the discriminating power of "dynamically enhanced" static images of handwriting is investigated. The enhanced images are synthetically generated by exploiting simultaneously the static and dynamic properties of handwriting. Specifically, we propose a static representation that embeds dynamic information based on: (i) drawing the points of the samples, instead of linking them, so as to retain temporal/velocity information; and (ii) adding pen-ups for the same purpose. To evaluate the effectiveness of the new handwriting representation, a fair comparison between this approach and state-of-the-art methods based on static and dynamic handwriting is conducted on the same dataset, i.e. PaHaW. The classification workflow employs transfer learning to extract meaningful features from multiple representations of the input data. An ensemble of different classifiers is used to achieve the final predictions. Dynamically enhanced static handwriting is able to outperform the results obtained by using static and dynamic handwriting separately.