 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Dream My Painting: Connecting MLLMs and Diffusion Models via Prompt Generation for Text-Guided Multi-Mask Inpainting
Paper and Code
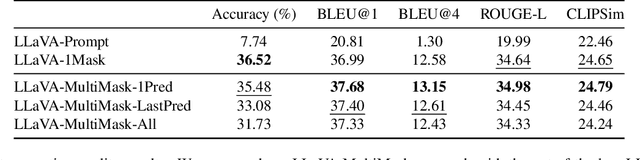
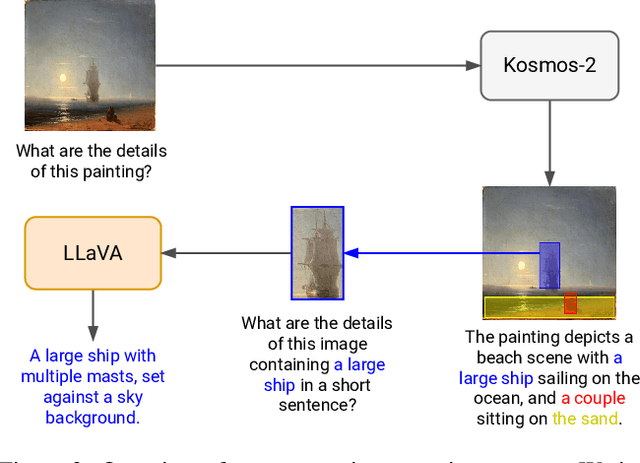

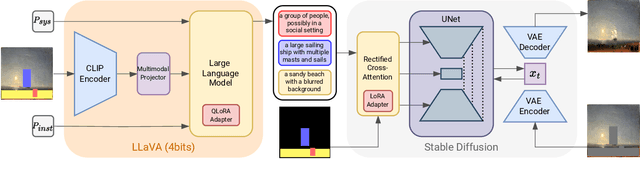
Inpainting focuses on filling missing or corrupted regions of an image to blend seamlessly with its surrounding content and style. While conditional diffusion models have proven effective for text-guided inpainting, we introduce the novel task of multi-mask inpainting, where multiple regions are simultaneously inpainted using distinct prompts. Furthermore, we design a fine-tuning procedure for multimodal LLMs, such as LLaVA, to generate multi-mask prompts automatically using corrupted images as inputs. These models can generate helpful and detailed prompt suggestions for filling the masked regions. The generated prompts are then fed to Stable Diffusion, which is fine-tuned for the multi-mask inpainting problem using rectified cross-attention, enforcing prompts onto their designated regions for filling. Experiments on digitized paintings from WikiArt and the Densely Captioned Images dataset demonstrate that our pipeline delivers creative and accurate inpainting results. Our code, data, and trained models are available at https://cilabuniba.github.io/i-dream-my-painting.