 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArt2Mus: Artwork-to-Music Generation via Visual Conditioning and Large-Scale Cross-Modal Alignment
Feb 19, 2026Music generation has advanced markedly through multimodal deep learning, enabling models to synthesize audio from text and, more recently, from images. However, existing image-conditioned systems suffer from two fundamental limitations: (i) they are typically trained on natural photographs, limiting their ability to capture the richer semantic, stylistic, and cultural content of artworks; and (ii) most rely on an image-to-text conversion stage, using language as a semantic shortcut that simplifies conditioning but prevents direct visual-to-audio learning. Motivated by these gaps, we introduce ArtSound, a large-scale multimodal dataset of 105,884 artwork-music pairs enriched with dual-modality captions, obtained by extending ArtGraph and the Free Music Archive. We further propose ArtToMus, the first framework explicitly designed for direct artwork-to-music generation, which maps digitized artworks to music without image-to-text translation or language-based semantic supervision. The framework projects visual embeddings into the conditioning space of a latent diffusion model, enabling music synthesis guided solely by visual information. Experimental results show that ArtToMus generates musically coherent and stylistically consistent outputs that reflect salient visual cues of the source artworks. While absolute alignment scores remain lower than those of text-conditioned systems-as expected given the substantially increased difficulty of removing linguistic supervision-ArtToMus achieves competitive perceptual quality and meaningful cross-modal correspondence. This work establishes direct visual-to-music generation as a distinct and challenging research direction, and provides resources that support applications in multimedia art, cultural heritage, and AI-assisted creative practice. Code and dataset will be publicly released upon acceptance.
ArtSeek: Deep artwork understanding via multimodal in-context reasoning and late interaction retrieval
Jul 29, 2025Analyzing digitized artworks presents unique challenges, requiring not only visual interpretation but also a deep understanding of rich artistic, contextual, and historical knowledge. We introduce ArtSeek, a multimodal framework for art analysis that combines multimodal large language models with retrieval-augmented generation. Unlike prior work, our pipeline relies only on image input, enabling applicability to artworks without links to Wikidata or Wikipedia-common in most digitized collections. ArtSeek integrates three key components: an intelligent multimodal retrieval module based on late interaction retrieval, a contrastive multitask classification network for predicting artist, genre, style, media, and tags, and an agentic reasoning strategy enabled through in-context examples for complex visual question answering and artwork explanation via Qwen2.5-VL. Central to this approach is WikiFragments, a Wikipedia-scale dataset of image-text fragments curated to support knowledge-grounded multimodal reasoning. Our framework achieves state-of-the-art results on multiple benchmarks, including a +8.4% F1 improvement in style classification over GraphCLIP and a +7.1 BLEU@1 gain in captioning on ArtPedia. Qualitative analyses show that ArtSeek can interpret visual motifs, infer historical context, and retrieve relevant knowledge, even for obscure works. Though focused on visual arts, our approach generalizes to other domains requiring external knowledge, supporting scalable multimodal AI research. Both the dataset and the source code will be made publicly available at https://github.com/cilabuniba/artseek.
I Dream My Painting: Connecting MLLMs and Diffusion Models via Prompt Generation for Text-Guided Multi-Mask Inpainting
Nov 28, 2024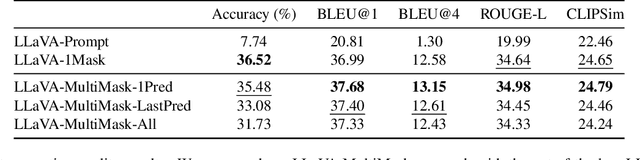
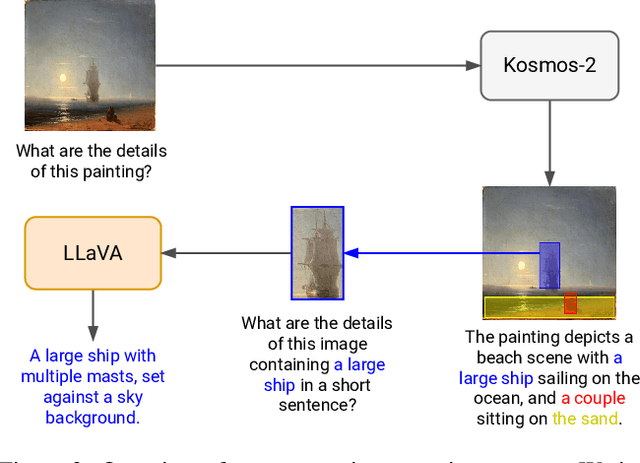

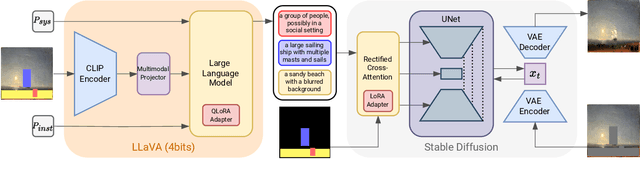
Inpainting focuses on filling missing or corrupted regions of an image to blend seamlessly with its surrounding content and style. While conditional diffusion models have proven effective for text-guided inpainting, we introduce the novel task of multi-mask inpainting, where multiple regions are simultaneously inpainted using distinct prompts. Furthermore, we design a fine-tuning procedure for multimodal LLMs, such as LLaVA, to generate multi-mask prompts automatically using corrupted images as inputs. These models can generate helpful and detailed prompt suggestions for filling the masked regions. The generated prompts are then fed to Stable Diffusion, which is fine-tuned for the multi-mask inpainting problem using rectified cross-attention, enforcing prompts onto their designated regions for filling. Experiments on digitized paintings from WikiArt and the Densely Captioned Images dataset demonstrate that our pipeline delivers creative and accurate inpainting results. Our code, data, and trained models are available at https://cilabuniba.github.io/i-dream-my-painting.
Art2Mus: Bridging Visual Arts and Music through Cross-Modal Generation
Oct 07, 2024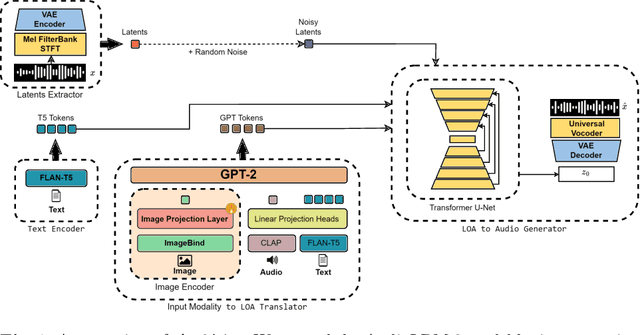

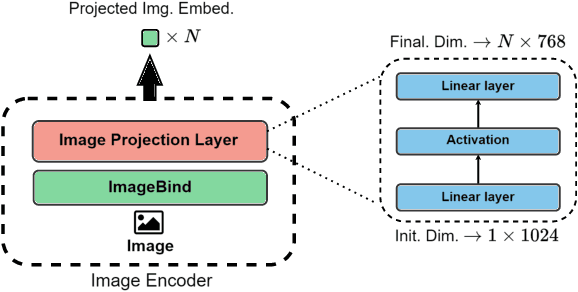

Artificial Intelligence and generative models have revolutionized music creation, with many models leveraging textual or visual prompts for guidance. However, existing image-to-music models are limited to simple images, lacking the capability to generate music from complex digitized artworks. To address this gap, we introduce $\mathcal{A}\textit{rt2}\mathcal{M}\textit{us}$, a novel model designed to create music from digitized artworks or text inputs. $\mathcal{A}\textit{rt2}\mathcal{M}\textit{us}$ extends the AudioLDM~2 architecture, a text-to-audio model, and employs our newly curated datasets, created via ImageBind, which pair digitized artworks with music. Experimental results demonstrate that $\mathcal{A}\textit{rt2}\mathcal{M}\textit{us}$ can generate music that resonates with the input stimuli. These findings suggest promising applications in multimedia art, interactive installations, and AI-driven creative tools.
Label Anything: Multi-Class Few-Shot Semantic Segmentation with Visual Prompts
Jul 02, 2024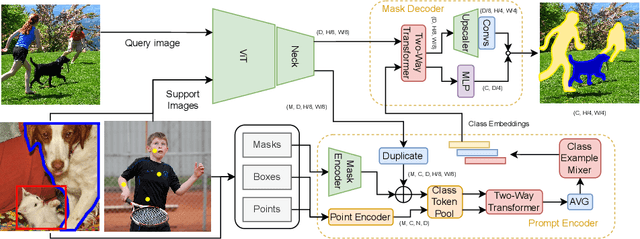
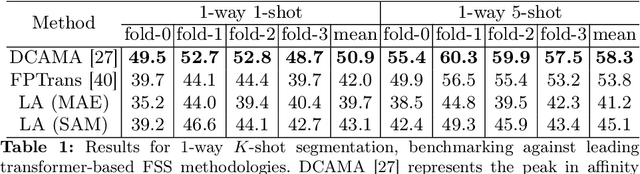
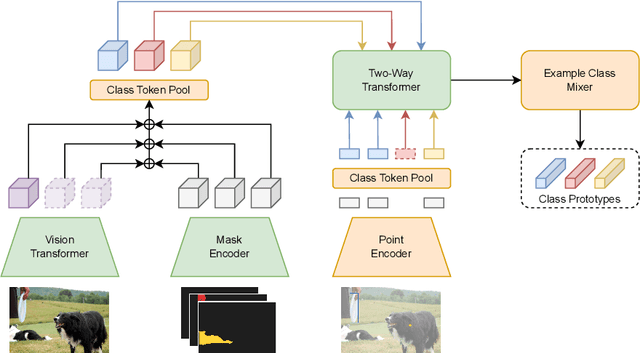

We present Label Anything, an innovative neural network architecture designed for few-shot semantic segmentation (FSS) that demonstrates remarkable generalizability across multiple classes with minimal examples required per class. Diverging from traditional FSS methods that predominantly rely on masks for annotating support images, Label Anything introduces varied visual prompts -- points, bounding boxes, and masks -- thereby enhancing the framework's versatility and adaptability. Unique to our approach, Label Anything is engineered for end-to-end training across multi-class FSS scenarios, efficiently learning from diverse support set configurations without retraining. This approach enables a "universal" application to various FSS challenges, ranging from $1$-way $1$-shot to complex $N$-way $K$-shot configurations while remaining agnostic to the specific number of class examples. This innovative training strategy reduces computational requirements and substantially improves the model's adaptability and generalization across diverse segmentation tasks. Our comprehensive experimental validation, particularly achieving state-of-the-art results on the COCO-$20^i$ benchmark, underscores Label Anything's robust generalization and flexibility. The source code is publicly available at: https://github.com/pasqualedem/LabelAnything.