 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCM3D: Object-Centric Monocular 3D Object Detection
Paper and Code
Apr 13, 2021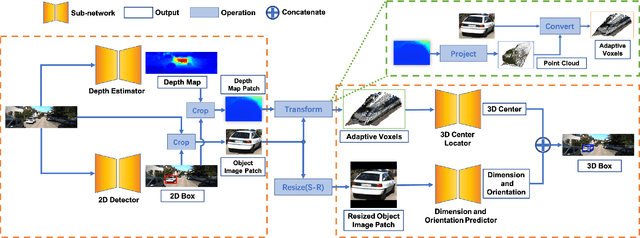
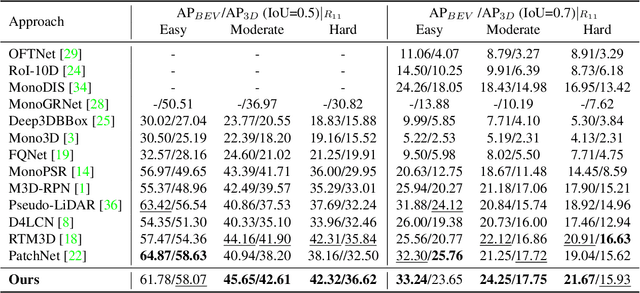
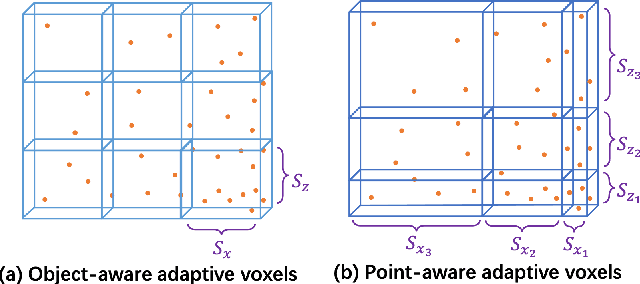

Image-only and pseudo-LiDAR representations are commonly used for monocular 3D object detection. However, methods based on them have shortcomings of either not well capturing the spatial relationships in neighbored image pixels or being hard to handle the noisy nature of the monocular pseudo-LiDAR point cloud. To overcome these issues, in this paper we propose a novel object-centric voxel representation tailored for monocular 3D object detection. Specifically, voxels are built on each object proposal, and their sizes are adaptively determined by the 3D spatial distribution of the points, allowing the noisy point cloud to be organized effectively within a voxel grid. This representation is proved to be able to locate the object in 3D space accurately. Furthermore, prior works would like to estimate the orientation via deep features extracted from an entire image or a noisy point cloud. By contrast, we argue that the local RoI information from the object image patch alone with a proper resizing scheme is a better input as it provides complete semantic clues meanwhile excludes irrelevant interferences. Besides, we decompose the confidence mechanism in monocular 3D object detection by considering the relationship between 3D objects and the associated 2D boxes. Evaluated on KITTI, our method outperforms state-of-the-art methods by a large margin. The code will be made publicly available soon.