 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Open Semantics from CLIP: A Relation Transition Perspective for Few-Shot Learning
Paper and Code
Jun 17, 2024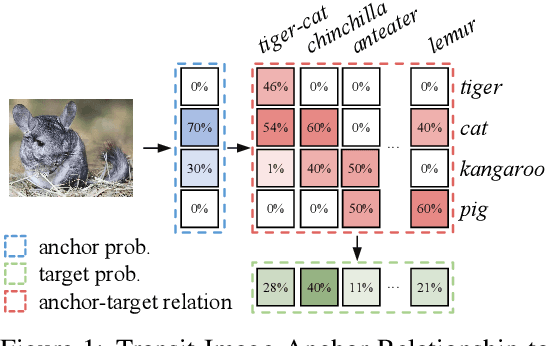
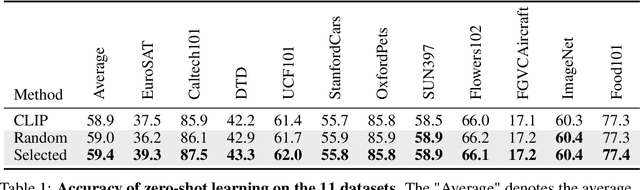
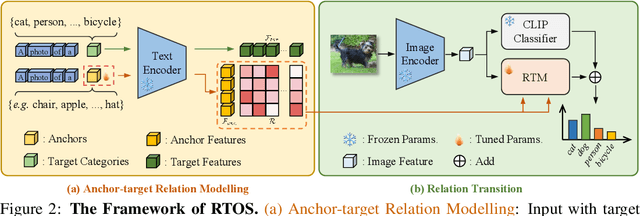
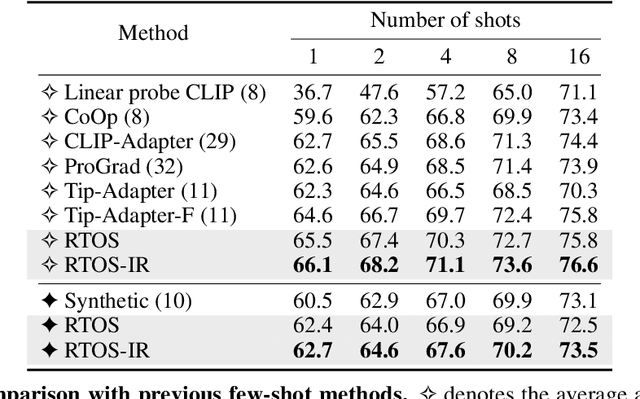
Contrastive Vision-Language Pre-training(CLIP) demonstrates impressive zero-shot capability. The key to improve the adaptation of CLIP to downstream task with few exemplars lies in how to effectively model and transfer the useful knowledge embedded in CLIP. Previous work mines the knowledge typically based on the limited visual samples and close-set semantics (i.e., within target category set of downstream task). However, the aligned CLIP image/text encoders contain abundant relationships between visual features and almost infinite open semantics, which may benefit the few-shot learning but remains unexplored. In this paper, we propose to mine open semantics as anchors to perform a relation transition from image-anchor relationship to image-target relationship to make predictions. Specifically, we adopt a transformer module which takes the visual feature as "Query", the text features of the anchors as "Key" and the similarity matrix between the text features of anchor and target classes as "Value". In this way, the output of such a transformer module represents the relationship between the image and target categories, i.e., the classification predictions. To avoid manually selecting the open semantics, we make the [CLASS] token of input text embedding learnable. We conduct extensive experiments on eleven representative classification datasets. The results show that our method performs favorably against previous state-of-the-arts considering few-shot classification settings.