 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-teacher Distillation for Multilingual Spelling Correction
Nov 20, 2023



Accurate spelling correction is a critical step in modern search interfaces, especially in an era of mobile devices and speech-to-text interfaces. For services that are deployed around the world, this poses a significant challenge for multilingual NLP: spelling errors need to be caught and corrected in all languages, and even in queries that use multiple languages. In this paper, we tackle this challenge using multi-teacher distillation. On our approach, a monolingual teacher model is trained for each language/locale, and these individual models are distilled into a single multilingual student model intended to serve all languages/locales. In experiments using open-source data as well as user data from a worldwide search service, we show that this leads to highly effective spelling correction models that can meet the tight latency requirements of deployed services.
Bilateral Dependency Optimization: Defending Against Model-inversion Attacks
Jun 18, 2022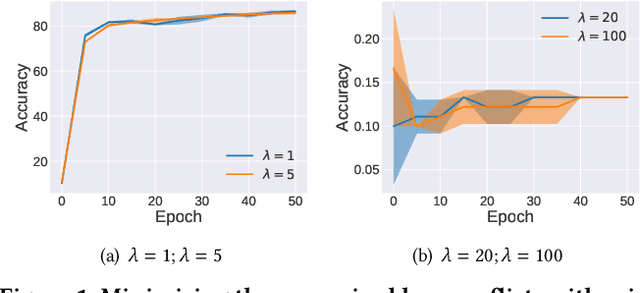
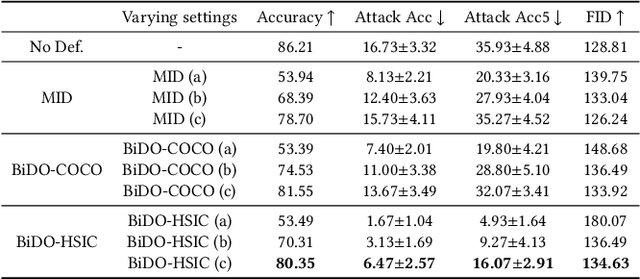
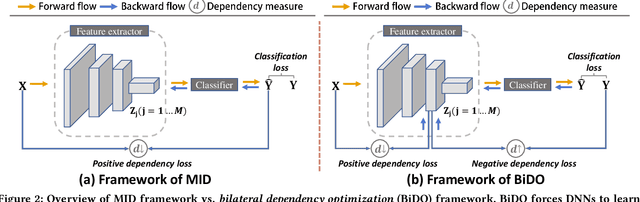
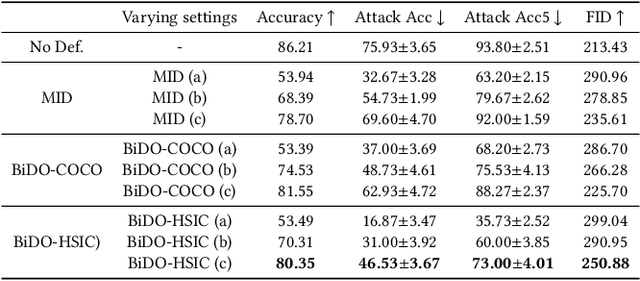
Through using only a well-trained classifier, model-inversion (MI) attacks can recover the data used for training the classifier, leading to the privacy leakage of the training data. To defend against MI attacks, previous work utilizes a unilateral dependency optimization strategy, i.e., minimizing the dependency between inputs (i.e., features) and outputs (i.e., labels) during training the classifier. However, such a minimization process conflicts with minimizing the supervised loss that aims to maximize the dependency between inputs and outputs, causing an explicit trade-off between model robustness against MI attacks and model utility on classification tasks. In this paper, we aim to minimize the dependency between the latent representations and the inputs while maximizing the dependency between latent representations and the outputs, named a bilateral dependency optimization (BiDO) strategy. In particular, we use the dependency constraints as a universally applicable regularizer in addition to commonly used losses for deep neural networks (e.g., cross-entropy), which can be instantiated with appropriate dependency criteria according to different tasks. To verify the efficacy of our strategy, we propose two implementations of BiDO, by using two different dependency measures: BiDO with constrained covariance (BiDO-COCO) and BiDO with Hilbert-Schmidt Independence Criterion (BiDO-HSIC). Experiments show that BiDO achieves the state-of-the-art defense performance for a variety of datasets, classifiers, and MI attacks while suffering a minor classification-accuracy drop compared to the well-trained classifier with no defense, which lights up a novel road to defend against MI attacks.
* Accepted to KDD 2022 (Research Track)