 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSpeech 2020: The Second Automated Machine Learning Challenge for Speech Classification
Oct 25, 2020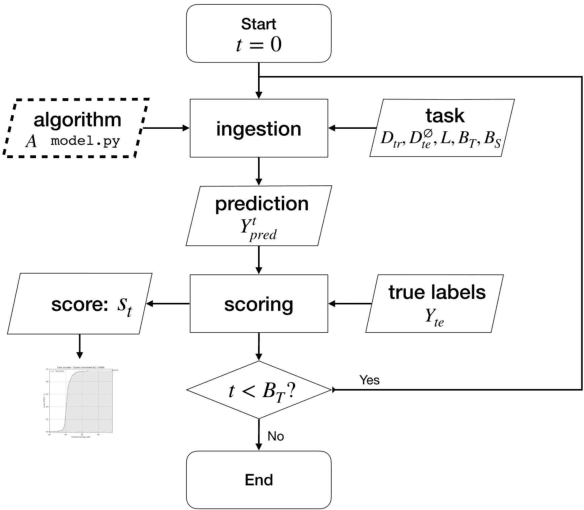
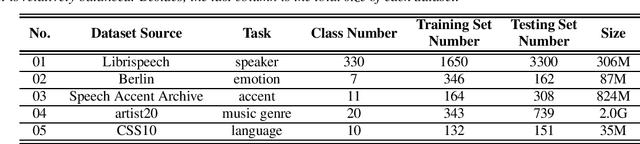
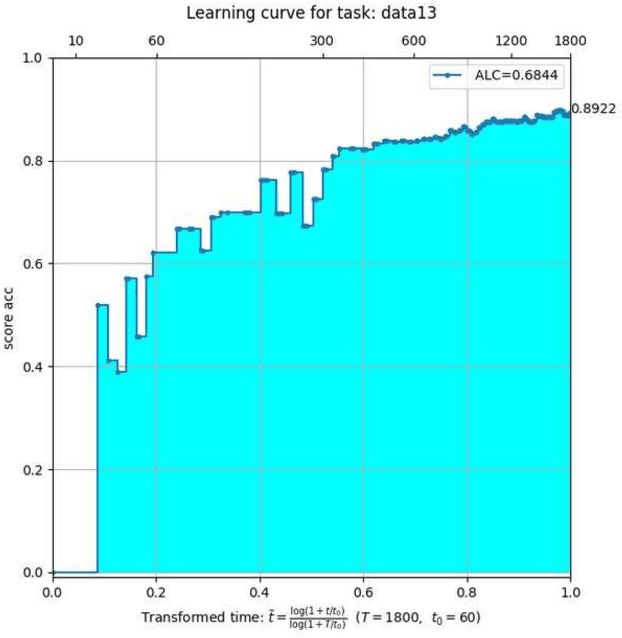
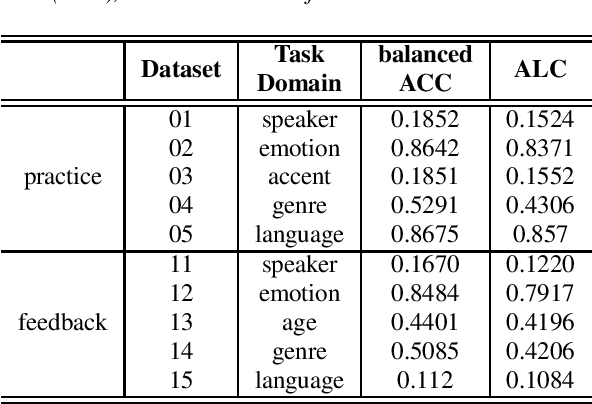
The AutoSpeech challenge calls for automated machine learning (AutoML) solutions to automate the process of applying machine learning to speech processing tasks. These tasks, which cover a large variety of domains, will be shown to the automated system in a random order. Each time when the tasks are switched, the information of the new task will be hinted with its corresponding training set. Thus, every submitted solution should contain an adaptation routine which adapts the system to the new task. Compared to the first edition, the 2020 edition includes advances of 1) more speech tasks, 2) noisier data in each task, 3) a modified evaluation metric. This paper outlines the challenge and describe the competition protocol, datasets, evaluation metric, starting kit, and baseline systems.