 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Learning with Nonconvex L1-2 Regularization
Paper and Code
Jun 20, 2017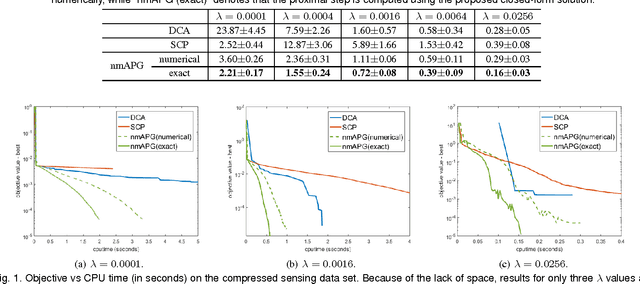
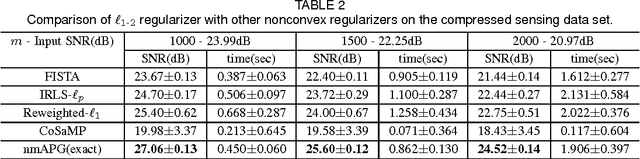
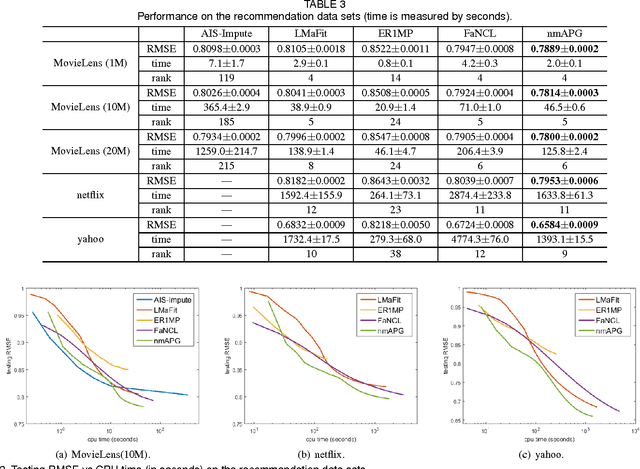
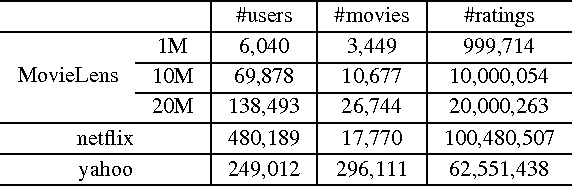
Convex regularizers are often used for sparse learning. They are easy to optimize, but can lead to inferior prediction performance. The difference of $\ell_1$ and $\ell_2$ ($\ell_{1-2}$) regularizer has been recently proposed as a nonconvex regularizer. It yields better recovery than both $\ell_0$ and $\ell_1$ regularizers on compressed sensing. However, how to efficiently optimize its learning problem is still challenging. The main difficulty is that both the $\ell_1$ and $\ell_2$ norms in $\ell_{1-2}$ are not differentiable, and existing optimization algorithms cannot be applied. In this paper, we show that a closed-form solution can be derived for the proximal step associated with this regularizer. We further extend the result for low-rank matrix learning and the total variation model. Experiments on both synthetic and real data sets show that the resultant accelerated proximal gradient algorithm is more efficient than other noncovex optimization algorithms.