 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoINS: Counterfactual Interactive Navigation via Skill-Aware VLM
Jan 07, 2026Recent Vision-Language Models (VLMs) have demonstrated significant potential in robotic planning. However, they typically function as semantic reasoners, lacking an intrinsic understanding of the specific robot's physical capabilities. This limitation is particularly critical in interactive navigation, where robots must actively modify cluttered environments to create traversable paths. Existing VLM-based navigators are predominantly confined to passive obstacle avoidance, failing to reason about when and how to interact with objects to clear blocked paths. To bridge this gap, we propose Counterfactual Interactive Navigation via Skill-aware VLM (CoINS), a hierarchical framework that integrates skill-aware reasoning and robust low-level execution. Specifically, we fine-tune a VLM, named InterNav-VLM, which incorporates skill affordance and concrete constraint parameters into the input context and grounds them into a metric-scale environmental representation. By internalizing the logic of counterfactual reasoning through fine-tuning on the proposed InterNav dataset, the model learns to implicitly evaluate the causal effects of object removal on navigation connectivity, thereby determining interaction necessity and target selection. To execute the generated high-level plans, we develop a comprehensive skill library through reinforcement learning, specifically introducing traversability-oriented strategies to manipulate diverse objects for path clearance. A systematic benchmark in Isaac Sim is proposed to evaluate both the reasoning and execution aspects of interactive navigation. Extensive simulations and real-world experiments demonstrate that CoINS significantly outperforms representative baselines, achieving a 17\% higher overall success rate and over 80\% improvement in complex long-horizon scenarios compared to the best-performing baseline
Real-time object detection method based on improved YOLOv4-tiny
Nov 09, 2020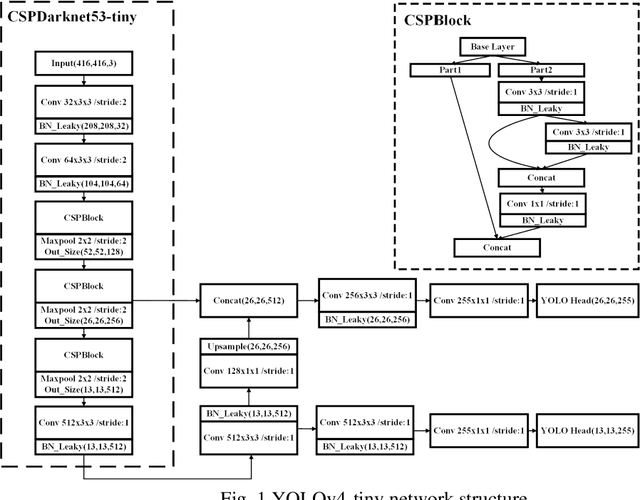
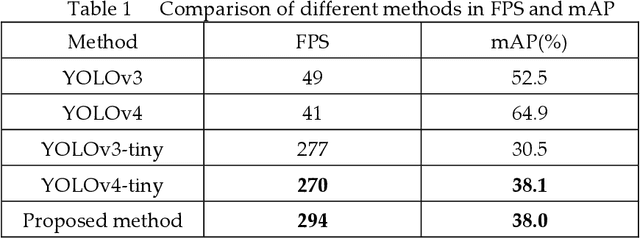
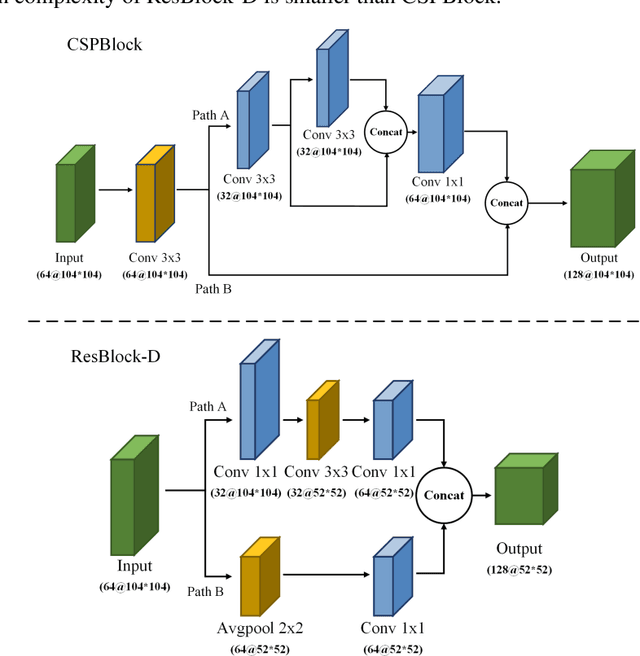
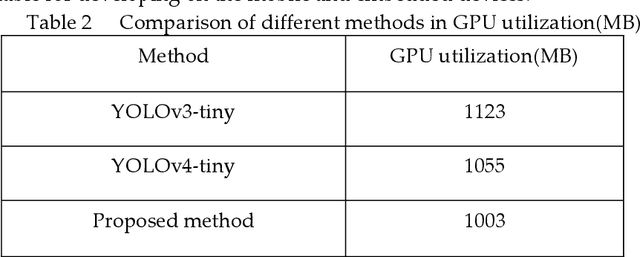
The "You only look once v4"(YOLOv4) is one type of object detection methods in deep learning. YOLOv4-tiny is proposed based on YOLOv4 to simple the network structure and reduce parameters, which makes it be suitable for developing on the mobile and embedded devices. To improve the real-time of object detection, a fast object detection method is proposed based on YOLOv4-tiny. It firstly uses two ResBlock-D modules in ResNet-D network instead of two CSPBlock modules in Yolov4-tiny, which reduces the computation complexity. Secondly, it designs an auxiliary residual network block to extract more feature information of object to reduce detection error. In the design of auxiliary network, two consecutive 3x3 convolutions are used to obtain 5x5 receptive fields to extract global features, and channel attention and spatial attention are also used to extract more effective information. In the end, it merges the auxiliary network and backbone network to construct the whole network structure of improved YOLOv4-tiny. Simulation results show that the proposed method has faster object detection than YOLOv4-tiny and YOLOv3-tiny, and almost the same mean value of average precision as the YOLOv4-tiny. It is more suitable for real-time object detection.