 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubsethood Measures of Spatial Granules
Sep 06, 2023Subsethood, which is to measure the degree of set inclusion relation, is predominant in fuzzy set theory. This paper introduces some basic concepts of spatial granules, coarse-fine relation, and operations like meet, join, quotient meet and quotient join. All the atomic granules can be hierarchized by set-inclusion relation and all the granules can be hierarchized by coarse-fine relation. Viewing an information system from the micro and the macro perspectives, we can get a micro knowledge space and a micro knowledge space, from which a rough set model and a spatial rough granule model are respectively obtained. The classical rough set model is the special case of the rough set model induced from the micro knowledge space, while the spatial rough granule model will be play a pivotal role in the problem-solving of structures. We discuss twelve axioms of monotone increasing subsethood and twelve corresponding axioms of monotone decreasing supsethood, and generalize subsethood and supsethood to conditional granularity and conditional fineness respectively. We develop five conditional granularity measures and five conditional fineness measures and prove that each conditional granularity or fineness measure satisfies its corresponding twelve axioms although its subsethood or supsethood measure only hold one of the two boundary conditions. We further define five conditional granularity entropies and five conditional fineness entropies respectively, and each entropy only satisfies part of the boundary conditions but all the ten monotone conditions.
Real-time object detection method based on improved YOLOv4-tiny
Nov 09, 2020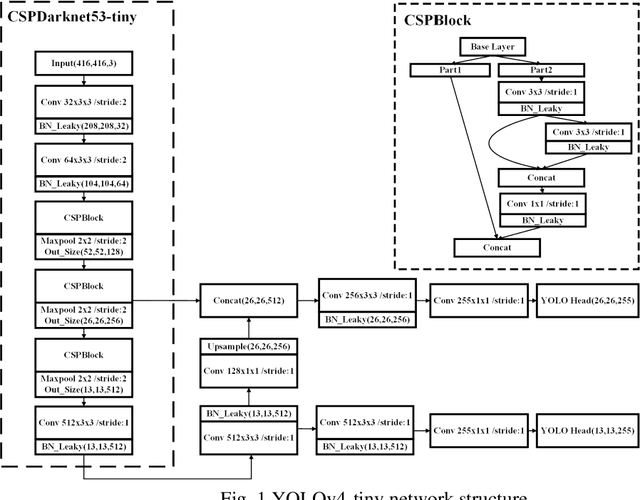
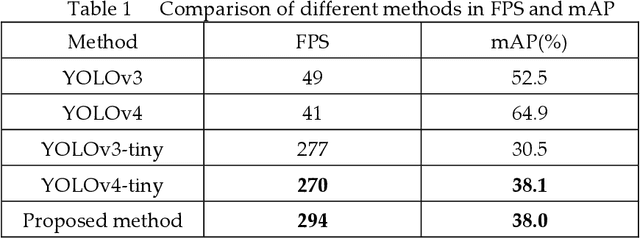
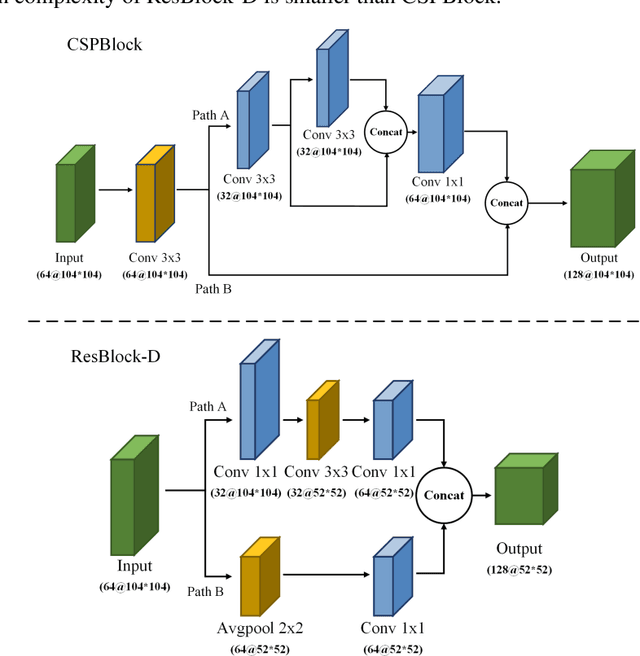
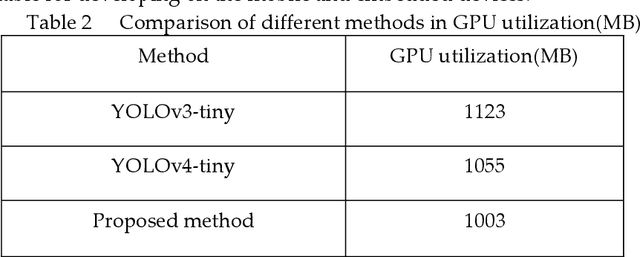
The "You only look once v4"(YOLOv4) is one type of object detection methods in deep learning. YOLOv4-tiny is proposed based on YOLOv4 to simple the network structure and reduce parameters, which makes it be suitable for developing on the mobile and embedded devices. To improve the real-time of object detection, a fast object detection method is proposed based on YOLOv4-tiny. It firstly uses two ResBlock-D modules in ResNet-D network instead of two CSPBlock modules in Yolov4-tiny, which reduces the computation complexity. Secondly, it designs an auxiliary residual network block to extract more feature information of object to reduce detection error. In the design of auxiliary network, two consecutive 3x3 convolutions are used to obtain 5x5 receptive fields to extract global features, and channel attention and spatial attention are also used to extract more effective information. In the end, it merges the auxiliary network and backbone network to construct the whole network structure of improved YOLOv4-tiny. Simulation results show that the proposed method has faster object detection than YOLOv4-tiny and YOLOv3-tiny, and almost the same mean value of average precision as the YOLOv4-tiny. It is more suitable for real-time object detection.