 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-to-SQL: Towards Speech-driven SQL Query Generation From Natural Language Question
Paper and Code
Jan 04, 2022
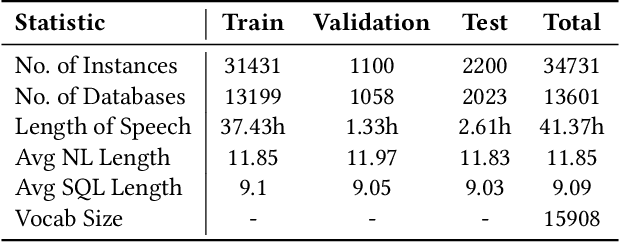
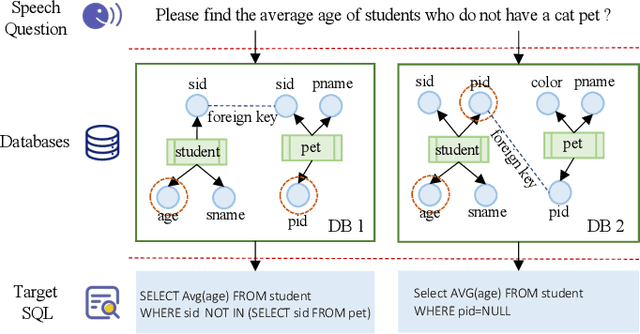
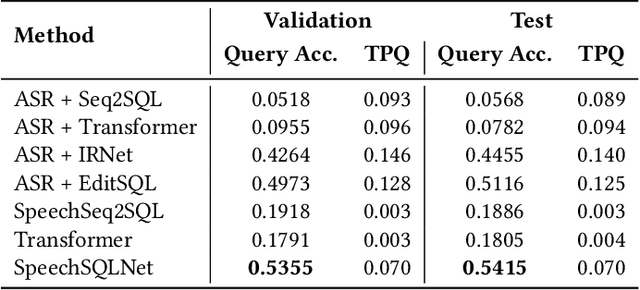
Speech-based inputs have been gaining significant momentum with the popularity of smartphones and tablets in our daily lives, since voice is the most easiest and efficient way for human-computer interaction. This paper works towards designing more effective speech-based interfaces to query the structured data in relational databases. We first identify a new task named Speech-to-SQL, which aims to understand the information conveyed by human speech and directly translate it into structured query language (SQL) statements. A naive solution to this problem can work in a cascaded manner, that is, an automatic speech recognition (ASR) component followed by a text-to-SQL component. However, it requires a high-quality ASR system and also suffers from the error compounding problem between the two components, resulting in limited performance. To handle these challenges, we further propose a novel end-to-end neural architecture named SpeechSQLNet to directly translate human speech into SQL queries without an external ASR step. SpeechSQLNet has the advantage of making full use of the rich linguistic information presented in speech. To the best of our knowledge, this is the first attempt to directly synthesize SQL based on arbitrary natural language questions, rather than a natural language-based version of SQL or its variants with a limited SQL grammar. To validate the effectiveness of the proposed problem and model, we further construct a dataset named SpeechQL, by piggybacking the widely-used text-to-SQL datasets. Extensive experimental evaluations on this dataset show that SpeechSQLNet can directly synthesize high-quality SQL queries from human speech, outperforming various competitive counterparts as well as the cascaded methods in terms of exact match accuracies.