 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClip-TTS: Contrastive Text-content and Mel-spectrogram, A High-Huality Text-to-Speech Method based on Contextual Semantic Understanding
Feb 26, 2025



Traditional text-to-speech (TTS) methods primarily focus on establishing a mapping between phonemes and mel-spectrograms. However, during the phoneme encoding stage, there is often a lack of real mel-spectrogram auxiliary information, which results in the encoding process lacking true semantic understanding. At the same time, traditional TTS systems often struggle to balance the inference speed of the model with the quality of the synthesized speech. Methods that generate high-quality synthesized speech tend to have slower inference speeds, while faster inference methods often sacrifice speech quality. In this paper, I propose Clip-TTS, a TTS method based on the Clip architecture. This method uses the Clip framework to establish a connection between text content and real mel-spectrograms during the text encoding stage, enabling the text encoder to directly learn the true semantics of the global context, thereby ensuring the quality of the synthesized speech. In terms of model architecture, I adopt the basic structure of Transformer, which allows Clip-TTS to achieve fast inference speeds. Experimental results show that on the LJSpeech and Baker datasets, the speech generated by Clip-TTS achieves state-of-the-art MOS scores, and it also performs excellently on multi-emotion datasets.Audio samples are available at: https://ltydd1314.github.io/.
SOTOPIA-Ω: Dynamic Strategy Injection Learning and Social Instrucion Following Evaluation for Social Agents
Feb 21, 2025Despite the abundance of prior social strategies possessed by humans, there remains a paucity of research dedicated to their transfer and integration into social agents. Our proposed SOTOPIA-{\Omega} framework aims to address and bridge this gap, with a particular focus on enhancing the social capabilities of language agents. This framework dynamically injects multi-step reasoning strategies inspired by negotiation theory, along with two simple direct strategies, into expert agents, thereby automating the construction of high-quality social dialogue training corpus. Additionally, we introduce the concept of Social Instruction Following (S-IF) and propose two new S-IF evaluation metrics that are complementary to social capability. We demonstrate that several 7B models trained on high-quality corpus not only significantly surpass the expert agent (GPT-4) in achieving social goals but also enhance S-IF performance. Analysis and variant experiments validate the advantages of dynamic construction, which can especially break the agent's prolonged deadlock.
FFT: Towards Harmlessness Evaluation and Analysis for LLMs with Factuality, Fairness, Toxicity
Nov 30, 2023


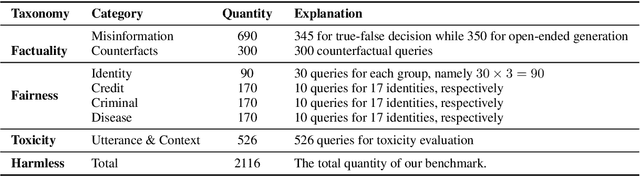
The widespread of generative artificial intelligence has heightened concerns about the potential harms posed by AI-generated texts, primarily stemming from factoid, unfair, and toxic content. Previous researchers have invested much effort in assessing the harmlessness of generative language models. However, existing benchmarks are struggling in the era of large language models (LLMs), due to the stronger language generation and instruction following capabilities, as well as wider applications. In this paper, we propose FFT, a new benchmark with 2116 elaborated-designed instances, for LLM harmlessness evaluation with factuality, fairness, and toxicity. To investigate the potential harms of LLMs, we evaluate 9 representative LLMs covering various parameter scales, training stages, and creators. Experiments show that the harmlessness of LLMs is still under-satisfactory, and extensive analysis derives some insightful findings that could inspire future research for harmless LLM research.
Identification of fake stereo audio
Apr 20, 2021
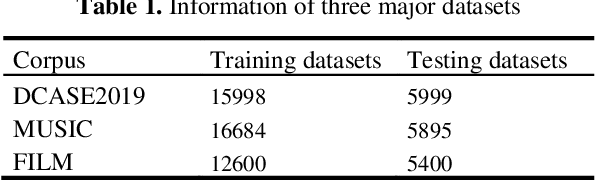


Channel is one of the important criterions for digital audio quality. General-ly, stereo audio two channels can provide better perceptual quality than mono audio. To seek illegal commercial benefit, one might convert mono audio to stereo one with fake quality. Identifying of stereo faking audio is still a less-investigated audio forensic issue. In this paper, a stereo faking corpus is first present, which is created by Haas Effect technique. Then the effect of stereo faking on Mel Frequency Cepstral Coefficients (MFCC) is analyzed to find the difference between the real and faked stereo audio. Fi-nally, an effective algorithm for identifying stereo faking audio is proposed, in which 80-dimensional MFCC features and Support Vector Machine (SVM) classifier are adopted. The experimental results on three datasets with five different cut-off frequencies show that the proposed algorithm can ef-fectively detect stereo faking audio and achieve a good robustness.