 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealImpact: A Dataset of Impact Sound Fields for Real Objects
Jun 16, 2023Objects make unique sounds under different perturbations, environment conditions, and poses relative to the listener. While prior works have modeled impact sounds and sound propagation in simulation, we lack a standard dataset of impact sound fields of real objects for audio-visual learning and calibration of the sim-to-real gap. We present RealImpact, a large-scale dataset of real object impact sounds recorded under controlled conditions. RealImpact contains 150,000 recordings of impact sounds of 50 everyday objects with detailed annotations, including their impact locations, microphone locations, contact force profiles, material labels, and RGBD images. We make preliminary attempts to use our dataset as a reference to current simulation methods for estimating object impact sounds that match the real world. Moreover, we demonstrate the usefulness of our dataset as a testbed for acoustic and audio-visual learning via the evaluation of two benchmark tasks, including listener location classification and visual acoustic matching.
Integrating Commercial and Social Determinants of Health: A Unified Ontology for Non-Clinical Determinants of Health
Apr 04, 2023The objectives of this research are 1) to develop an ontology for CDoH by utilizing PubMed articles and ChatGPT; 2) to foster ontology reuse by integrating CDoH with an existing SDoH ontology into a unified structure; 3) to devise an overarching conception for all non-clinical determinants of health and to create an initial ontology, called N-CODH, for them; 4) and to validate the degree of correspondence between concepts provided by ChatGPT with the existing SDoH ontology
An Ontology for the Social Determinants of Health Domain
Nov 15, 2022



Social determinants of health are societal factors, such as where a person was born, grew up, works, lives, etc, along with socioeconomic and community factors that affect individual health. Social Determinants of Health are correlated with many clinical outcomes, hence it is desirable to record SDOH data in Electronic Health Records (EHRs). Besides storing images, text, etc., EHRs rely on coded terms available in standard ontologies and terminologies to record observations and analyses. There is a substantial amount of research on understanding the clinical impact of SDOH, ranging from screening tools to practice based interventions. However, there is no comprehensive collection of terms for recording SDOH observations in EHRs. Our research goal is to develop an ontology that covers the terms describing SDOH. We present a prototype ontology called Social Determinant of Health Ontology (SOHO) that covers relevant concepts and IS--A relationships describing impacts and associations of social determinants. We describe the evaluation techniques that we applied to SOHO, including human experts review and algorithmic evaluation.
FDB: Fraud Dataset Benchmark
Aug 31, 2022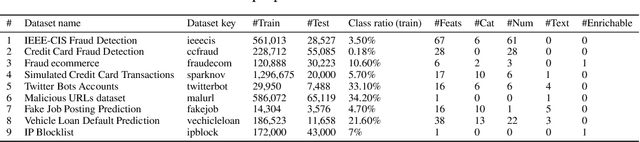
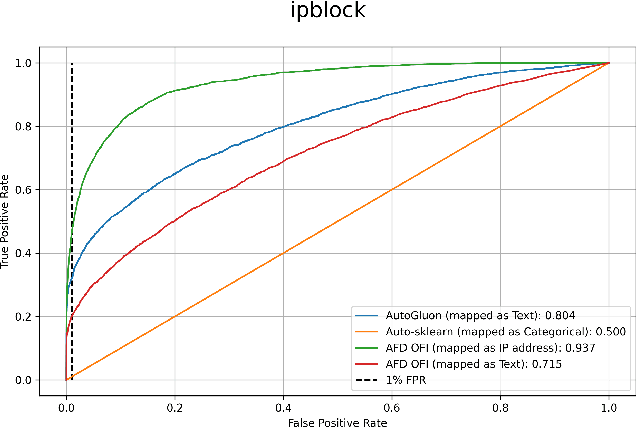


Standardized datasets and benchmarks have spurred innovations in computer vision, natural language processing, multi-modal and tabular settings. We note that, as compared to other well researched fields fraud detection has numerous differences. The differences include a high class imbalance, diverse feature types, frequently changing fraud patterns, and adversarial nature of the problem. Due to these differences, the modeling approaches that are designed for other classification tasks may not work well for the fraud detection. We introduce Fraud Dataset Benchmark (FDB), a compilation of publicly available datasets catered to fraud detection. FDB comprises variety of fraud related tasks, ranging from identifying fraudulent card-not-present transactions, detecting bot attacks, classifying malicious URLs, predicting risk of loan to content moderation. The Python based library from FDB provides consistent API for data loading with standardized training and testing splits. For reference, we also provide baseline evaluations of different modeling approaches on FDB. Considering the increasing popularity of Automated Machine Learning (AutoML) for various research and business problems, we used AutoML frameworks for our baseline evaluations. For fraud prevention, the organizations that operate with limited resources and lack ML expertise often hire a team of investigators, use blocklists and manual rules, all of which are inefficient and do not scale well. Such organizations can benefit from AutoML solutions that are easy to deploy in production and pass the bar of fraud prevention requirements. We hope that FDB helps in the development of customized fraud detection techniques catered to different fraud modus operandi (MOs) as well as in the improvement of AutoML systems that can work well for all datasets in the benchmark.