 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpportunityFinder: A Framework for Automated Causal Inference
Sep 22, 2023We introduce OpportunityFinder, a code-less framework for performing a variety of causal inference studies with panel data for non-expert users. In its current state, OpportunityFinder only requires users to provide raw observational data and a configuration file. A pipeline is then triggered that inspects/processes data, chooses the suitable algorithm(s) to execute the causal study. It returns the causal impact of the treatment on the configured outcome, together with sensitivity and robustness results. Causal inference is widely studied and used to estimate the downstream impact of individual's interactions with products and features. It is common that these causal studies are performed by scientists and/or economists periodically. Business stakeholders are often bottle-necked on scientist or economist bandwidth to conduct causal studies. We offer OpportunityFinder as a solution for commonly performed causal studies with four key features: (1) easy to use for both Business Analysts and Scientists, (2) abstraction of multiple algorithms under a single I/O interface, (3) support for causal impact analysis under binary treatment with panel data and (4) dynamic selection of algorithm based on scale of data.
FDB: Fraud Dataset Benchmark
Aug 31, 2022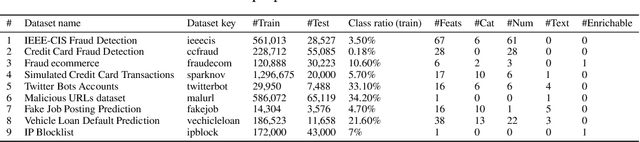
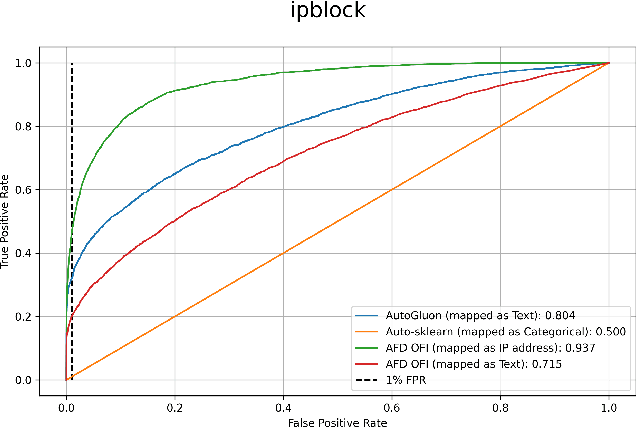


Standardized datasets and benchmarks have spurred innovations in computer vision, natural language processing, multi-modal and tabular settings. We note that, as compared to other well researched fields fraud detection has numerous differences. The differences include a high class imbalance, diverse feature types, frequently changing fraud patterns, and adversarial nature of the problem. Due to these differences, the modeling approaches that are designed for other classification tasks may not work well for the fraud detection. We introduce Fraud Dataset Benchmark (FDB), a compilation of publicly available datasets catered to fraud detection. FDB comprises variety of fraud related tasks, ranging from identifying fraudulent card-not-present transactions, detecting bot attacks, classifying malicious URLs, predicting risk of loan to content moderation. The Python based library from FDB provides consistent API for data loading with standardized training and testing splits. For reference, we also provide baseline evaluations of different modeling approaches on FDB. Considering the increasing popularity of Automated Machine Learning (AutoML) for various research and business problems, we used AutoML frameworks for our baseline evaluations. For fraud prevention, the organizations that operate with limited resources and lack ML expertise often hire a team of investigators, use blocklists and manual rules, all of which are inefficient and do not scale well. Such organizations can benefit from AutoML solutions that are easy to deploy in production and pass the bar of fraud prevention requirements. We hope that FDB helps in the development of customized fraud detection techniques catered to different fraud modus operandi (MOs) as well as in the improvement of AutoML systems that can work well for all datasets in the benchmark.