 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpportunityFinder: A Framework for Automated Causal Inference
Sep 22, 2023We introduce OpportunityFinder, a code-less framework for performing a variety of causal inference studies with panel data for non-expert users. In its current state, OpportunityFinder only requires users to provide raw observational data and a configuration file. A pipeline is then triggered that inspects/processes data, chooses the suitable algorithm(s) to execute the causal study. It returns the causal impact of the treatment on the configured outcome, together with sensitivity and robustness results. Causal inference is widely studied and used to estimate the downstream impact of individual's interactions with products and features. It is common that these causal studies are performed by scientists and/or economists periodically. Business stakeholders are often bottle-necked on scientist or economist bandwidth to conduct causal studies. We offer OpportunityFinder as a solution for commonly performed causal studies with four key features: (1) easy to use for both Business Analysts and Scientists, (2) abstraction of multiple algorithms under a single I/O interface, (3) support for causal impact analysis under binary treatment with panel data and (4) dynamic selection of algorithm based on scale of data.
AutoWS: Automated Weak Supervision Framework for Text Classification
Feb 07, 2023



Creating large, good quality labeled data has become one of the major bottlenecks for developing machine learning applications. Multiple techniques have been developed to either decrease the dependence of labeled data (zero/few-shot learning, weak supervision) or to improve the efficiency of labeling process (active learning). Among those, Weak Supervision has been shown to reduce labeling costs by employing hand crafted labeling functions designed by domain experts. We propose AutoWS -- a novel framework for increasing the efficiency of weak supervision process while decreasing the dependency on domain experts. Our method requires a small set of labeled examples per label class and automatically creates a set of labeling functions to assign noisy labels to numerous unlabeled data. Noisy labels can then be aggregated into probabilistic labels used by a downstream discriminative classifier. Our framework is fully automatic and requires no hyper-parameter specification by users. We compare our approach with different state-of-the-art work on weak supervision and noisy training. Experimental results show that our method outperforms competitive baselines.
Robust Product Classification with Instance-Dependent Noise
Sep 14, 2022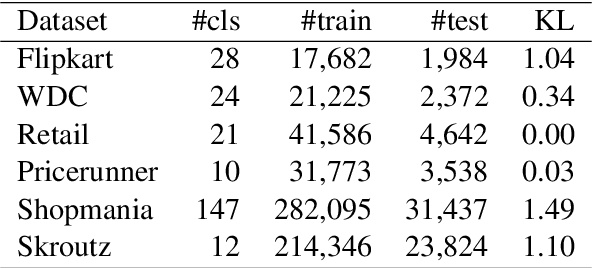
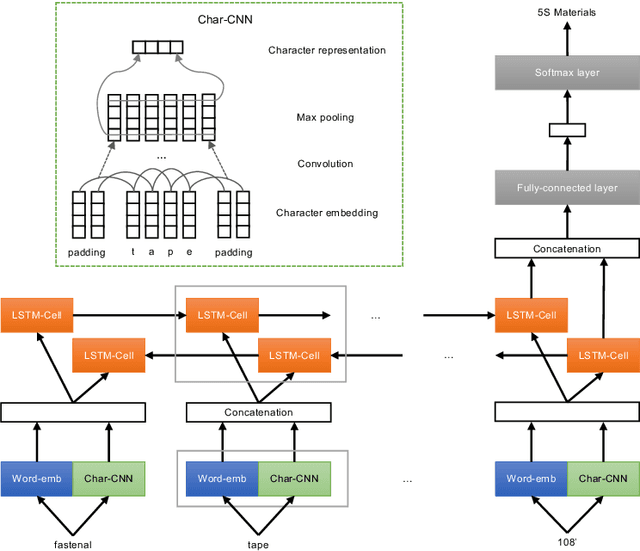


Noisy labels in large E-commerce product data (i.e., product items are placed into incorrect categories) are a critical issue for product categorization task because they are unavoidable, non-trivial to remove and degrade prediction performance significantly. Training a product title classification model which is robust to noisy labels in the data is very important to make product classification applications more practical. In this paper, we study the impact of instance-dependent noise to performance of product title classification by comparing our data denoising algorithm and different noise-resistance training algorithms which were designed to prevent a classifier model from over-fitting to noise. We develop a simple yet effective Deep Neural Network for product title classification to use as a base classifier. Along with recent methods of stimulating instance-dependent noise, we propose a novel noise stimulation algorithm based on product title similarity. Our experiments cover multiple datasets, various noise methods and different training solutions. Results uncover the limit of classification task when noise rate is not negligible and data distribution is highly skewed.