 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel View Synthesis with Neural Radiance Fields for Industrial Robot Applications
May 07, 2024Neural Radiance Fields (NeRFs) have become a rapidly growing research field with the potential to revolutionize typical photogrammetric workflows, such as those used for 3D scene reconstruction. As input, NeRFs require multi-view images with corresponding camera poses as well as the interior orientation. In the typical NeRF workflow, the camera poses and the interior orientation are estimated in advance with Structure from Motion (SfM). But the quality of the resulting novel views, which depends on different parameters such as the number and distribution of available images, as well as the accuracy of the related camera poses and interior orientation, is difficult to predict. In addition, SfM is a time-consuming pre-processing step, and its quality strongly depends on the image content. Furthermore, the undefined scaling factor of SfM hinders subsequent steps in which metric information is required. In this paper, we evaluate the potential of NeRFs for industrial robot applications. We propose an alternative to SfM pre-processing: we capture the input images with a calibrated camera that is attached to the end effector of an industrial robot and determine accurate camera poses with metric scale based on the robot kinematics. We then investigate the quality of the novel views by comparing them to ground truth, and by computing an internal quality measure based on ensemble methods. For evaluation purposes, we acquire multiple datasets that pose challenges for reconstruction typical of industrial applications, like reflective objects, poor texture, and fine structures. We show that the robot-based pose determination reaches similar accuracy as SfM in non-demanding cases, while having clear advantages in more challenging scenarios. Finally, we present first results of applying the ensemble method to estimate the quality of the synthetic novel view in the absence of a ground truth.
Image-based Deep Learning for the time-dependent prediction of fresh concrete properties
Feb 09, 2024



Increasing the degree of digitisation and automation in the concrete production process can play a crucial role in reducing the CO$_2$ emissions that are associated with the production of concrete. In this paper, a method is presented that makes it possible to predict the properties of fresh concrete during the mixing process based on stereoscopic image sequences of the concretes flow behaviour. A Convolutional Neural Network (CNN) is used for the prediction, which receives the images supported by information on the mix design as input. In addition, the network receives temporal information in the form of the time difference between the time at which the images are taken and the time at which the reference values of the concretes are carried out. With this temporal information, the network implicitly learns the time-dependent behaviour of the concretes properties. The network predicts the slump flow diameter, the yield stress and the plastic viscosity. The time-dependent prediction potentially opens up the pathway to determine the temporal development of the fresh concrete properties already during mixing. This provides a huge advantage for the concrete industry. As a result, countermeasures can be taken in a timely manner. It is shown that an approach based on depth and optical flow images, supported by information of the mix design, achieves the best results.
ConsInstancy: Learning Instance Representations for Semi-Supervised Panoptic Segmentation of Concrete Aggregate Particles
Apr 10, 2022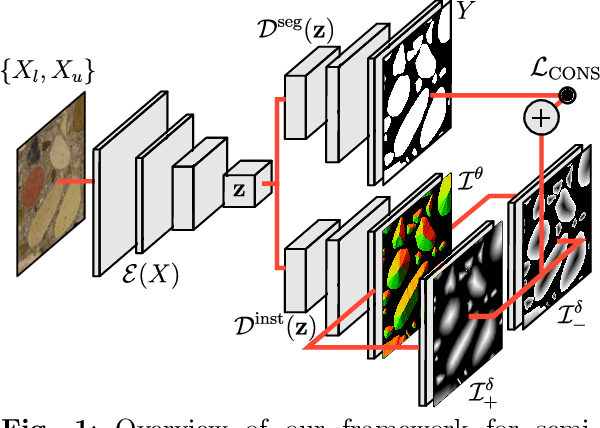
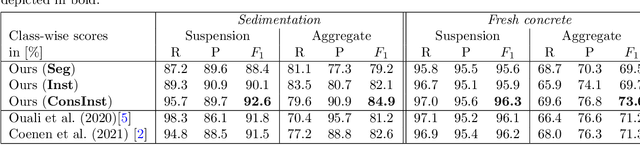

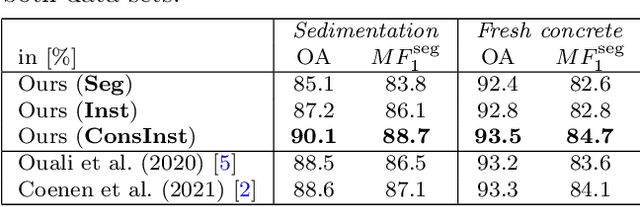
We present a semi-supervised method for panoptic segmentation based on ConsInstancy regularisation, a novel strategy for semi-supervised learning. It leverages completely unlabelled data by enforcing consistency between predicted instance representations and semantic segmentations during training in order to improve the segmentation performance. To this end, we also propose new types of instance representations that can be predicted by one simple forward path through a fully convolutional network (FCN), delivering a convenient and simple-to-train framework for panoptic segmentation. More specifically, we propose the prediction of a three-dimensional instance orientation map as intermediate representation and two complementary distance transform maps as final representation, providing unique instance representations for a panoptic segmentation. We test our method on two challenging data sets of both, hardened and fresh concrete, the latter being proposed by the authors in this paper demonstrating the effectiveness of our approach, outperforming the results achieved by state-of-the-art methods for semi-supervised segmentation. In particular, we are able to show that by leveraging completely unlabeled data in our semi-supervised approach the achieved overall accuracy (OA) is increased by up to 5% compared to an entirely supervised training using only labeled data. Furthermore, we exceed the OA achieved by state-of-the-art semi-supervised methods by up to 1.5%.
Learning to Sieve: Prediction of Grading Curves from Images of Concrete Aggregate
Apr 07, 2022



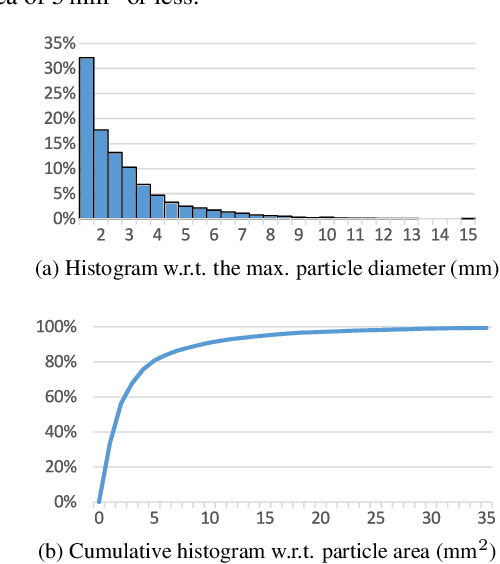
A large component of the building material concrete consists of aggregate with varying particle sizes between 0.125 and 32 mm. Its actual size distribution significantly affects the quality characteristics of the final concrete in both, the fresh and hardened states. The usually unknown variations in the size distribution of the aggregate particles, which can be large especially when using recycled aggregate materials, are typically compensated by an increased usage of cement which, however, has severe negative impacts on economical and ecological aspects of the concrete production. In order to allow a precise control of the target properties of the concrete, unknown variations in the size distribution have to be quantified to enable a proper adaptation of the concrete's mixture design in real time. To this end, this paper proposes a deep learning based method for the determination of concrete aggregate grading curves. In this context, we propose a network architecture applying multi-scale feature extraction modules in order to handle the strongly diverse object sizes of the particles. Furthermore, we propose and publish a novel dataset of concrete aggregate used for the quantitative evaluation of our method.
Semi-Supervised Segmentation of Concrete Aggregate Using Consensus Regularisation and Prior Guidance
Apr 22, 2021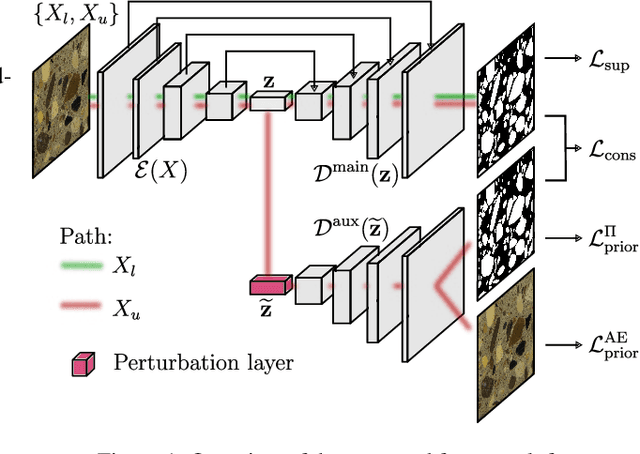


In order to leverage and profit from unlabelled data, semi-supervised frameworks for semantic segmentation based on consistency training have been proven to be powerful tools to significantly improve the performance of purely supervised segmentation learning. However, the consensus principle behind consistency training has at least one drawback, which we identify in this paper: imbalanced label distributions within the data. To overcome the limitations of standard consistency training, we propose a novel semi-supervised framework for semantic segmentation, introducing additional losses based on prior knowledge. Specifically, we propose a light-weight architecture consisting of a shared encoder and a main decoder, which is trained in a supervised manner. An auxiliary decoder is added as additional branch in order to make use of unlabelled data based on consensus training, and we add additional constraints derived from prior information on the class distribution and on auto-encoder regularisation. Experiments performed on our "concrete aggregate dataset" presented in this paper demonstrate the effectiveness of the proposed approach, outperforming the segmentation results achieved by purely supervised segmentation and standard consistency training.
A hierarchical deep learning framework for the consistent classification of land use objects in geospatial databases
Apr 14, 2021
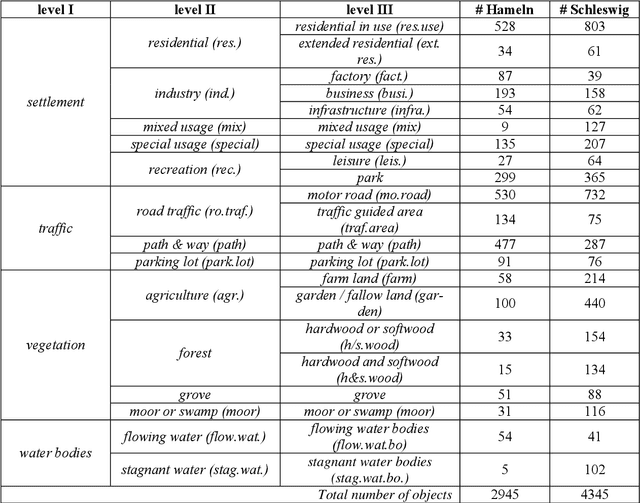
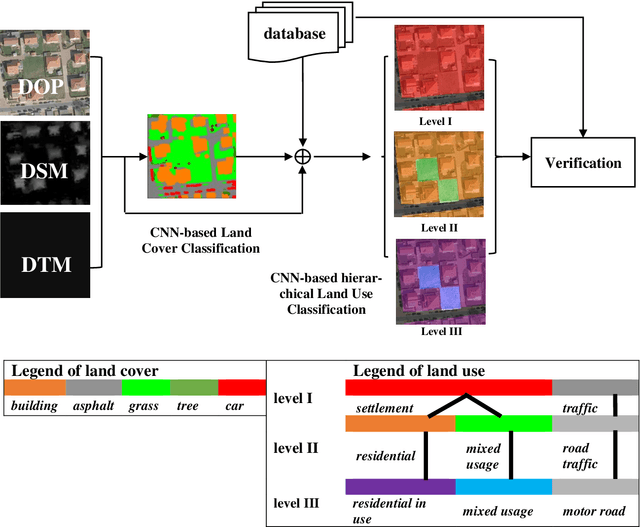

Land use as contained in geospatial databases constitutes an essential input for different applica-tions such as urban management, regional planning and environmental monitoring. In this paper, a hierarchical deep learning framework is proposed to verify the land use information. For this purpose, a two-step strategy is applied. First, given high-resolution aerial images, the land cover information is determined. To achieve this, an encoder-decoder based convolutional neural net-work (CNN) is proposed. Second, the pixel-wise land cover information along with the aerial images serves as input for another CNN to classify land use. Because the object catalogue of geospatial databases is frequently constructed in a hierarchical manner, we propose a new CNN-based method aiming to predict land use in multiple levels hierarchically and simultaneously. A so called Joint Optimization (JO) is proposed where predictions are made by selecting the hier-archical tuple over all levels which has the maximum joint class scores, providing consistent results across the different levels. The conducted experiments show that the CNN relying on JO outperforms previous results, achieving an overall accuracy up to 92.5%. In addition to the individual experiments on two test sites, we investigate whether data showing different characteristics can improve the results of land cover and land use classification, when processed together. To do so, we combine the two datasets and undertake some additional experiments. The results show that adding more data helps both land cover and land use classification, especially the identification of underrepre-sented categories, despite their different characteristics.
CNN-based Cost Volume Analysis as Confidence Measure for Dense Matching
May 17, 2019
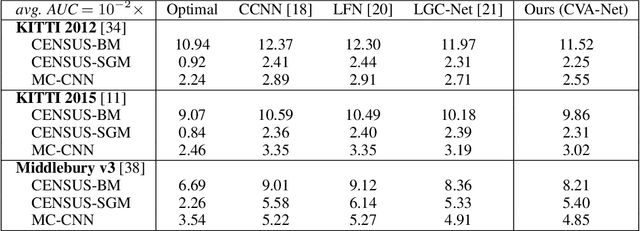

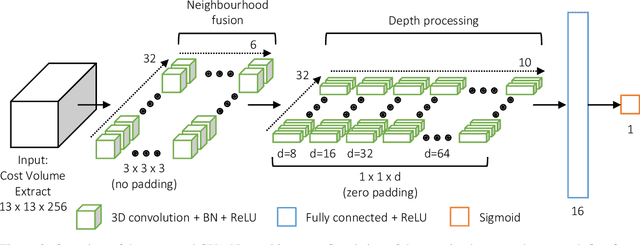
Due to its capability to identify erroneous disparity assignments in dense stereo matching, confidence estimation is beneficial for a wide range of applications, e.g. autonomous driving, which needs a certain degree of confidence as mandatory prerequisite. Especially, the introduction of deep learning based methods resulted in an increasing popularity of this field in recent years, caused by a significantly improved accuracy. Despite this remarkable development, most of these methods rely on features learned from disparity maps only, not taking into account the corresponding 3-dimensional cost volumes. However, it was already demonstrated that with conventional methods based on hand-crafted features this additional information can be used to further increase the accuracy. In order to combine the advantages of deep learning and cost volume based features, in this paper, we propose a novel Convolutional Neural Network (CNN) architecture to directly learn features for confidence estimation from volumetric 3D data. An extensive evaluation on three datasets using three common dense stereo matching techniques demonstrates the generality and state-of-the-art accuracy of the proposed method.
A two-layer Conditional Random Field for the classification of partially occluded objects
Sep 13, 2013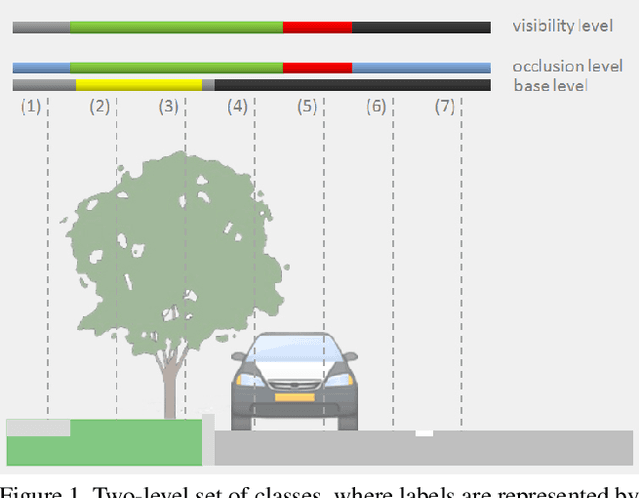
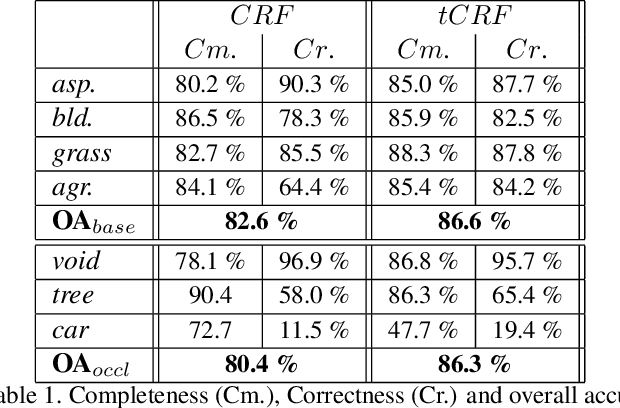
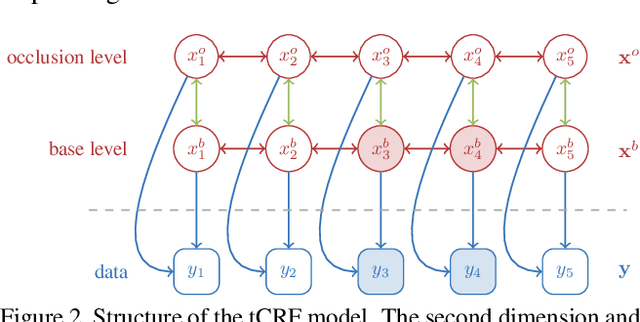
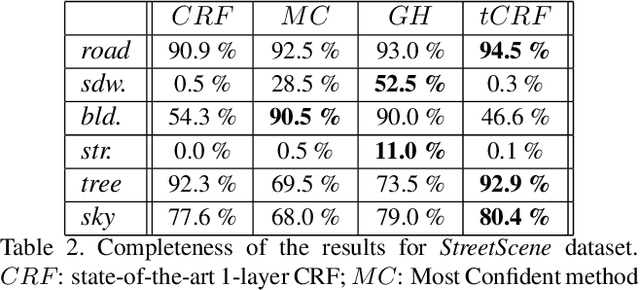
Conditional Random Fields (CRF) are among the most popular techniques for image labelling because of their flexibility in modelling dependencies between the labels and the image features. This paper proposes a novel CRF-framework for image labeling problems which is capable to classify partially occluded objects. Our approach is evaluated on aerial near-vertical images as well as on urban street-view images and compared with another methods.