 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-based Deep Learning for the time-dependent prediction of fresh concrete properties
Feb 09, 2024



Increasing the degree of digitisation and automation in the concrete production process can play a crucial role in reducing the CO$_2$ emissions that are associated with the production of concrete. In this paper, a method is presented that makes it possible to predict the properties of fresh concrete during the mixing process based on stereoscopic image sequences of the concretes flow behaviour. A Convolutional Neural Network (CNN) is used for the prediction, which receives the images supported by information on the mix design as input. In addition, the network receives temporal information in the form of the time difference between the time at which the images are taken and the time at which the reference values of the concretes are carried out. With this temporal information, the network implicitly learns the time-dependent behaviour of the concretes properties. The network predicts the slump flow diameter, the yield stress and the plastic viscosity. The time-dependent prediction potentially opens up the pathway to determine the temporal development of the fresh concrete properties already during mixing. This provides a huge advantage for the concrete industry. As a result, countermeasures can be taken in a timely manner. It is shown that an approach based on depth and optical flow images, supported by information of the mix design, achieves the best results.
ConsInstancy: Learning Instance Representations for Semi-Supervised Panoptic Segmentation of Concrete Aggregate Particles
Apr 10, 2022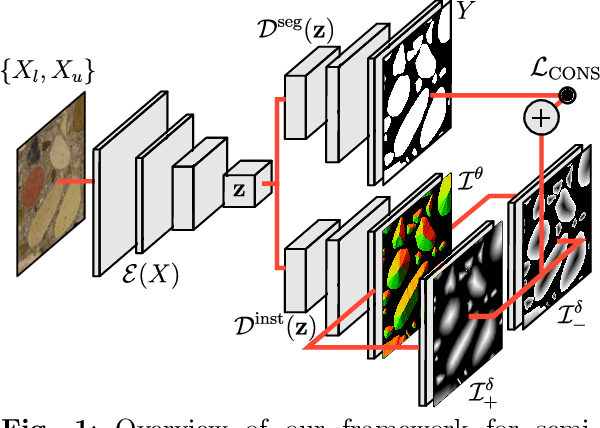
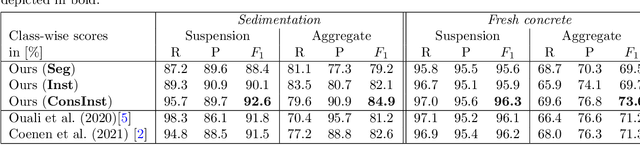

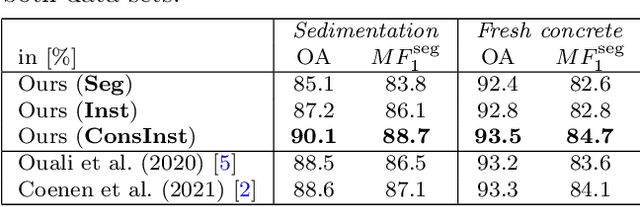
We present a semi-supervised method for panoptic segmentation based on ConsInstancy regularisation, a novel strategy for semi-supervised learning. It leverages completely unlabelled data by enforcing consistency between predicted instance representations and semantic segmentations during training in order to improve the segmentation performance. To this end, we also propose new types of instance representations that can be predicted by one simple forward path through a fully convolutional network (FCN), delivering a convenient and simple-to-train framework for panoptic segmentation. More specifically, we propose the prediction of a three-dimensional instance orientation map as intermediate representation and two complementary distance transform maps as final representation, providing unique instance representations for a panoptic segmentation. We test our method on two challenging data sets of both, hardened and fresh concrete, the latter being proposed by the authors in this paper demonstrating the effectiveness of our approach, outperforming the results achieved by state-of-the-art methods for semi-supervised segmentation. In particular, we are able to show that by leveraging completely unlabeled data in our semi-supervised approach the achieved overall accuracy (OA) is increased by up to 5% compared to an entirely supervised training using only labeled data. Furthermore, we exceed the OA achieved by state-of-the-art semi-supervised methods by up to 1.5%.
Learning to Sieve: Prediction of Grading Curves from Images of Concrete Aggregate
Apr 07, 2022



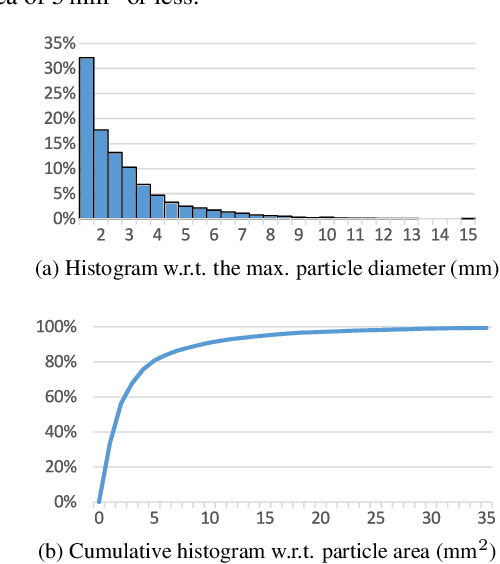
A large component of the building material concrete consists of aggregate with varying particle sizes between 0.125 and 32 mm. Its actual size distribution significantly affects the quality characteristics of the final concrete in both, the fresh and hardened states. The usually unknown variations in the size distribution of the aggregate particles, which can be large especially when using recycled aggregate materials, are typically compensated by an increased usage of cement which, however, has severe negative impacts on economical and ecological aspects of the concrete production. In order to allow a precise control of the target properties of the concrete, unknown variations in the size distribution have to be quantified to enable a proper adaptation of the concrete's mixture design in real time. To this end, this paper proposes a deep learning based method for the determination of concrete aggregate grading curves. In this context, we propose a network architecture applying multi-scale feature extraction modules in order to handle the strongly diverse object sizes of the particles. Furthermore, we propose and publish a novel dataset of concrete aggregate used for the quantitative evaluation of our method.
Pose Estimation and 3D Reconstruction of Vehicles from Stereo-Images Using a Subcategory-Aware Shape Prior
Jul 22, 2021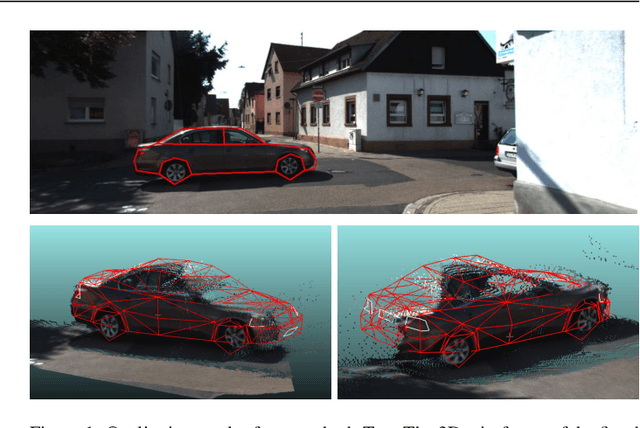
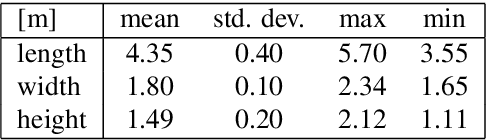
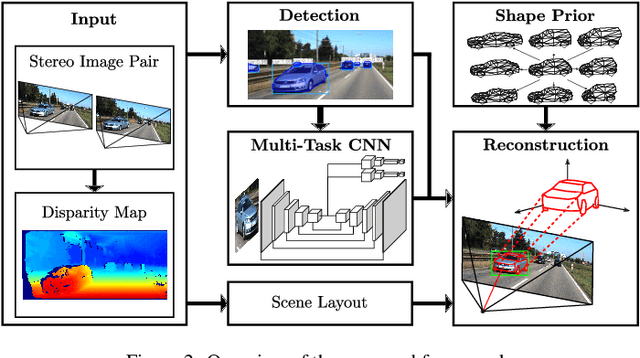

The 3D reconstruction of objects is a prerequisite for many highly relevant applications of computer vision such as mobile robotics or autonomous driving. To deal with the inverse problem of reconstructing 3D objects from their 2D projections, a common strategy is to incorporate prior object knowledge into the reconstruction approach by establishing a 3D model and aligning it to the 2D image plane. However, current approaches are limited due to inadequate shape priors and the insufficiency of the derived image observations for a reliable alignment with the 3D model. The goal of this paper is to show how 3D object reconstruction can profit from a more sophisticated shape prior and from a combined incorporation of different observation types inferred from the images. We introduce a subcategory-aware deformable vehicle model that makes use of a prediction of the vehicle type for a more appropriate regularisation of the vehicle shape. A multi-branch CNN is presented to derive predictions of the vehicle type and orientation. This information is also introduced as prior information for model fitting. Furthermore, the CNN extracts vehicle keypoints and wireframes, which are well-suited for model-to-image association and model fitting. The task of pose estimation and reconstruction is addressed by a versatile probabilistic model. Extensive experiments are conducted using two challenging real-world data sets on both of which the benefit of the developed shape prior can be shown. A comparison to state-of-the-art methods for vehicle pose estimation shows that the proposed approach performs on par or better, confirming the suitability of the developed shape prior and probabilistic model for vehicle reconstruction.
Semi-Supervised Segmentation of Concrete Aggregate Using Consensus Regularisation and Prior Guidance
Apr 22, 2021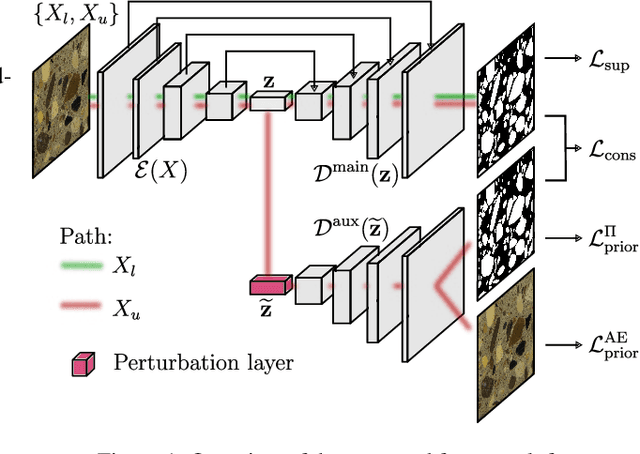


In order to leverage and profit from unlabelled data, semi-supervised frameworks for semantic segmentation based on consistency training have been proven to be powerful tools to significantly improve the performance of purely supervised segmentation learning. However, the consensus principle behind consistency training has at least one drawback, which we identify in this paper: imbalanced label distributions within the data. To overcome the limitations of standard consistency training, we propose a novel semi-supervised framework for semantic segmentation, introducing additional losses based on prior knowledge. Specifically, we propose a light-weight architecture consisting of a shared encoder and a main decoder, which is trained in a supervised manner. An auxiliary decoder is added as additional branch in order to make use of unlabelled data based on consensus training, and we add additional constraints derived from prior information on the class distribution and on auto-encoder regularisation. Experiments performed on our "concrete aggregate dataset" presented in this paper demonstrate the effectiveness of the proposed approach, outperforming the segmentation results achieved by purely supervised segmentation and standard consistency training.
Probabilistic Vehicle Reconstruction Using a Multi-Task CNN
Feb 21, 2021
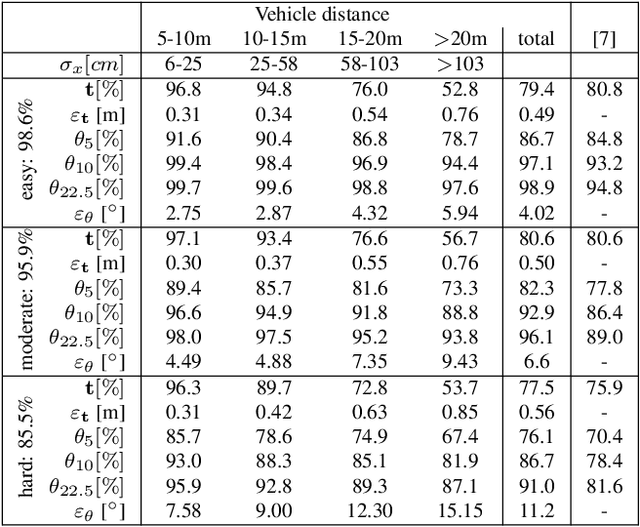
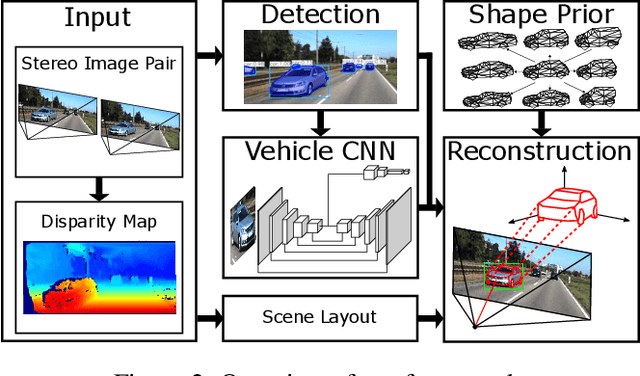

The retrieval of the 3D pose and shape of objects from images is an ill-posed problem. A common way to object reconstruction is to match entities such as keypoints, edges, or contours of a deformable 3D model, used as shape prior, to their corresponding entities inferred from the image. However, such approaches are highly sensitive to model initialisation, imprecise keypoint localisations and/or illumination conditions. In this paper, we present a probabilistic approach for shape-aware 3D vehicle reconstruction from stereo images that leverages the outputs of a novel multi-task CNN. Specifically, we train a CNN that outputs probability distributions for the vehicle's orientation and for both, vehicle keypoints and wireframe edges. Together with 3D stereo information we integrate the predicted distributions into a common probabilistic framework. We believe that the CNN-based detection of wireframe edges reduces the sensitivity to illumination conditions and object contrast and that using the raw probability maps instead of inferring keypoint positions reduces the sensitivity to keypoint localisation errors. We show that our method achieves state-of-the-art results, evaluating our method on the challenging KITTI benchmark and on our own new 'Stereo-Vehicle' dataset.