Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Multi-task Uncertainties in Joint Semantic Segmentation and Monocular Depth Estimation
Paper and Code
May 27, 2024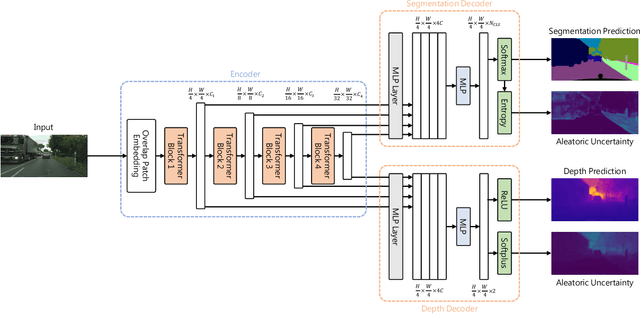
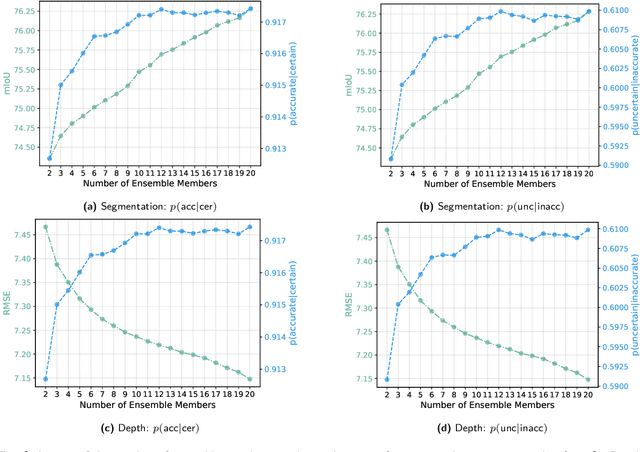
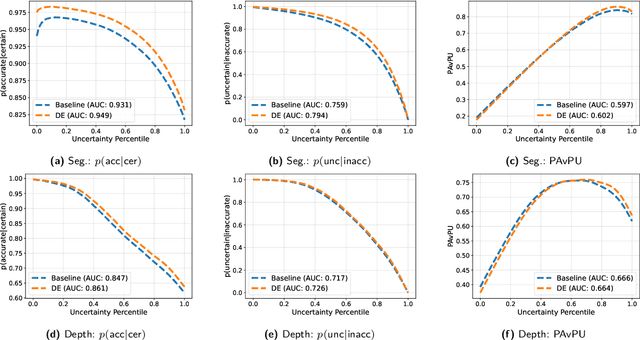
While a number of promising uncertainty quantification methods have been proposed to address the prevailing shortcomings of deep neural networks like overconfidence and lack of explainability, quantifying predictive uncertainties in the context of joint semantic segmentation and monocular depth estimation has not been explored yet. Since many real-world applications are multi-modal in nature and, hence, have the potential to benefit from multi-task learning, this is a substantial gap in current literature. To this end, we conduct a comprehensive series of experiments to study how multi-task learning influences the quality of uncertainty estimates in comparison to solving both tasks separately.
* Submitted to Forum Bildverarbeitung 2024. arXiv admin note:
substantial text overlap with arXiv:2402.10580
View paper on