 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Networks and Tabular Data: A Survey
Paper and Code
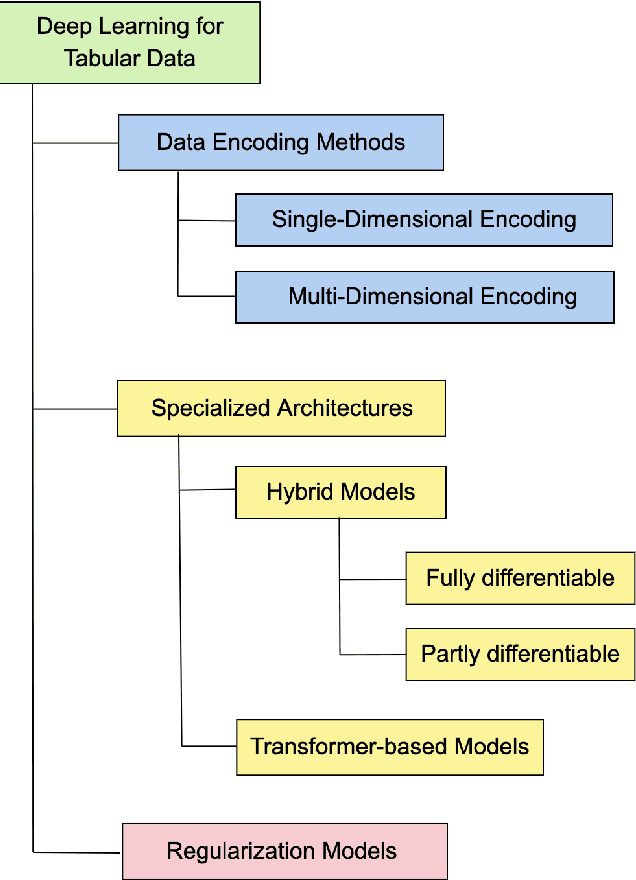
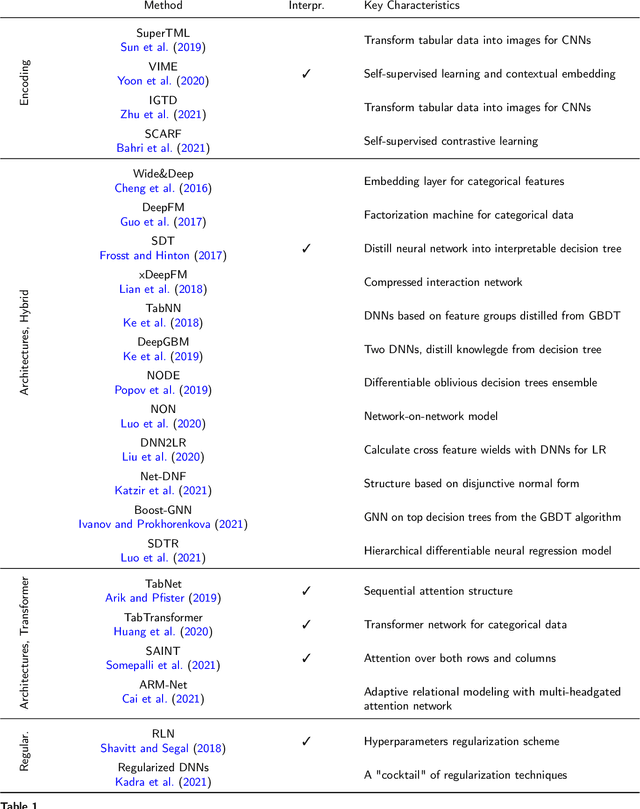
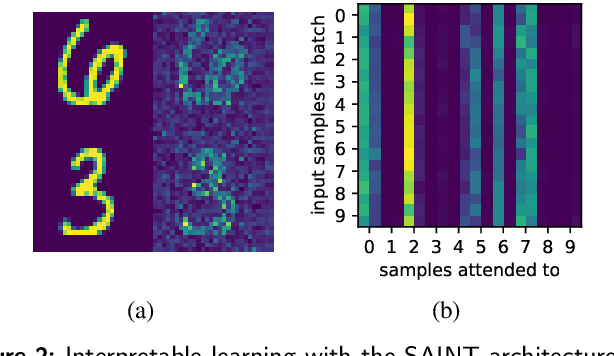
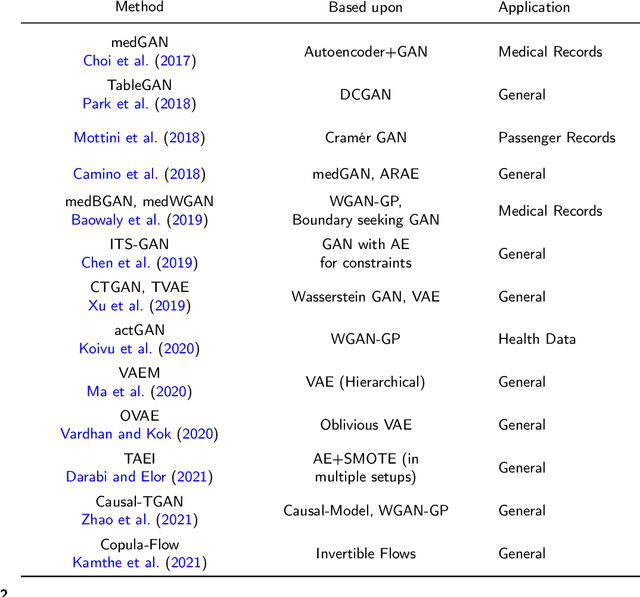
Heterogeneous tabular data are the most commonly used form of data and are essential for numerous critical and computationally demanding applications. On homogeneous data sets, deep neural networks have repeatedly shown excellent performance and have therefore been widely adopted. However, their application to modeling tabular data (inference or generation) remains highly challenging. This work provides an overview of state-of-the-art deep learning methods for tabular data. We start by categorizing them into three groups: data transformations, specialized architectures, and regularization models. We then provide a comprehensive overview of the main approaches in each group. A discussion of deep learning approaches for generating tabular data is complemented by strategies for explaining deep models on tabular data. Our primary contribution is to address the main research streams and existing methodologies in this area, while highlighting relevant challenges and open research questions. To the best of our knowledge, this is the first in-depth look at deep learning approaches for tabular data. This work can serve as a valuable starting point and guide for researchers and practitioners interested in deep learning with tabular data.