 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the interpretability of GNN predictions through conformal-based graph sparsification
Apr 18, 2024

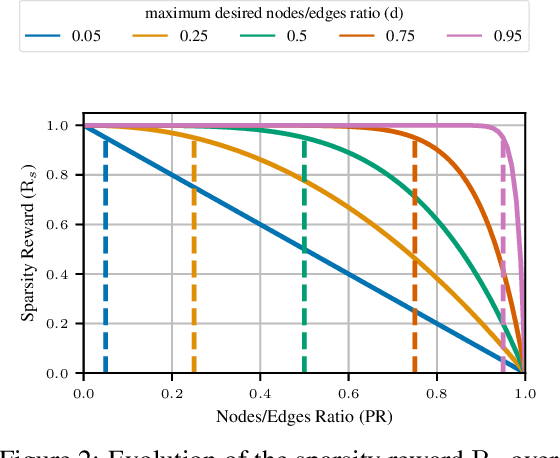

Graph Neural Networks (GNNs) have achieved state-of-the-art performance in solving graph classification tasks. However, most GNN architectures aggregate information from all nodes and edges in a graph, regardless of their relevance to the task at hand, thus hindering the interpretability of their predictions. In contrast to prior work, in this paper we propose a GNN \emph{training} approach that jointly i) finds the most predictive subgraph by removing edges and/or nodes -- -\emph{without making assumptions about the subgraph structure} -- while ii) optimizing the performance of the graph classification task. To that end, we rely on reinforcement learning to solve the resulting bi-level optimization with a reward function based on conformal predictions to account for the current in-training uncertainty of the classifier. Our empirical results on nine different graph classification datasets show that our method competes in performance with baselines while relying on significantly sparser subgraphs, leading to more interpretable GNN-based predictions.
Variational Mixture of HyperGenerators for Learning Distributions Over Functions
Feb 13, 2023Recent approaches build on implicit neural representations (INRs) to propose generative models over function spaces. However, they are computationally intensive when dealing with inference tasks, such as missing data imputation, or directly cannot tackle them. In this work, we propose a novel deep generative model, named VAMoH. VAMoH combines the capabilities of modeling continuous functions using INRs and the inference capabilities of Variational Autoencoders (VAEs). In addition, VAMoH relies on a normalizing flow to define the prior, and a mixture of hypernetworks to parametrize the data log-likelihood. This gives VAMoH a high expressive capability and interpretability. Through experiments on a diverse range of data types, such as images, voxels, and climate data, we show that VAMoH can effectively learn rich distributions over continuous functions. Furthermore, it can perform inference-related tasks, such as conditional super-resolution generation and in-painting, as well or better than previous approaches, while being less computationally demanding.
Learnable Graph Convolutional Attention Networks
Nov 21, 2022Existing Graph Neural Networks (GNNs) compute the message exchange between nodes by either aggregating uniformly (convolving) the features of all the neighboring nodes, or by applying a non-uniform score (attending) to the features. Recent works have shown the strengths and weaknesses of the resulting GNN architectures, respectively, GCNs and GATs. In this work, we aim at exploiting the strengths of both approaches to their full extent. To this end, we first introduce the graph convolutional attention layer (CAT), which relies on convolutions to compute the attention scores. Unfortunately, as in the case of GCNs and GATs, we show that there exists no clear winner between the three (neither theoretically nor in practice) as their performance directly depends on the nature of the data (i.e., of the graph and features). This result brings us to the main contribution of our work, the learnable graph convolutional attention network (L-CAT): a GNN architecture that automatically interpolates between GCN, GAT and CAT in each layer, by adding only two scalar parameters. Our results demonstrate that L-CAT is able to efficiently combine different GNN layers along the network, outperforming competing methods in a wide range of datasets, and resulting in a more robust model that reduces the need of cross-validating.
VACA: Design of Variational Graph Autoencoders for Interventional and Counterfactual Queries
Oct 27, 2021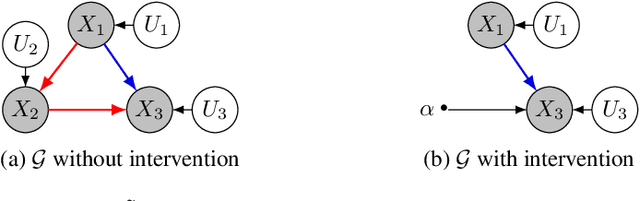
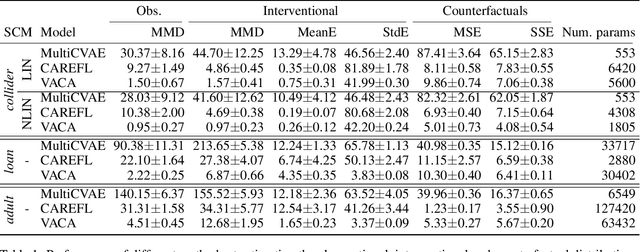
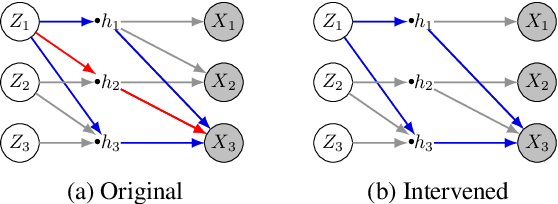

In this paper, we introduce VACA, a novel class of variational graph autoencoders for causal inference in the absence of hidden confounders, when only observational data and the causal graph are available. Without making any parametric assumptions, VACA mimics the necessary properties of a Structural Causal Model (SCM) to provide a flexible and practical framework for approximating interventions (do-operator) and abduction-action-prediction steps. As a result, and as shown by our empirical results, VACA accurately approximates the interventional and counterfactual distributions on diverse SCMs. Finally, we apply VACA to evaluate counterfactual fairness in fair classification problems, as well as to learn fair classifiers without compromising performance.