 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the interpretability of GNN predictions through conformal-based graph sparsification
Paper and Code


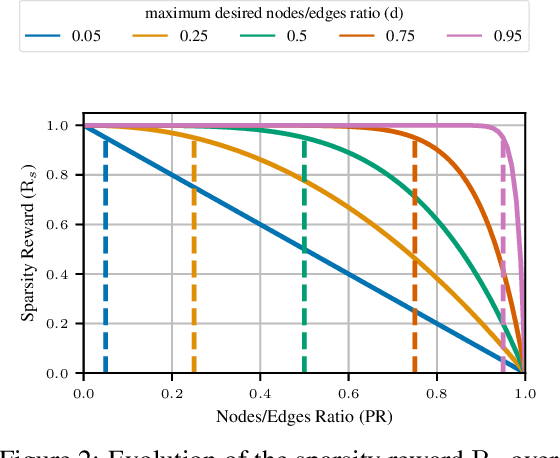

Graph Neural Networks (GNNs) have achieved state-of-the-art performance in solving graph classification tasks. However, most GNN architectures aggregate information from all nodes and edges in a graph, regardless of their relevance to the task at hand, thus hindering the interpretability of their predictions. In contrast to prior work, in this paper we propose a GNN \emph{training} approach that jointly i) finds the most predictive subgraph by removing edges and/or nodes -- -\emph{without making assumptions about the subgraph structure} -- while ii) optimizing the performance of the graph classification task. To that end, we rely on reinforcement learning to solve the resulting bi-level optimization with a reward function based on conformal predictions to account for the current in-training uncertainty of the classifier. Our empirical results on nine different graph classification datasets show that our method competes in performance with baselines while relying on significantly sparser subgraphs, leading to more interpretable GNN-based predictions.