 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sobering Look at Tabular Data Generation via Probabilistic Circuits
Mar 24, 2026Tabular data is more challenging to generate than text and images, due to its heterogeneous features and much lower sample sizes. On this task, diffusion-based models are the current state-of-the-art (SotA) model class, achieving almost perfect performance on commonly used benchmarks. In this paper, we question the perception of progress for tabular data generation. First, we highlight the limitations of current protocols to evaluate the fidelity of generated data, and advocate for alternative ones. Next, we revisit a simple baseline -- hierarchical mixture models in the form of deep probabilistic circuits (PCs) -- which delivers competitive or superior performance to SotA models for a fraction of the cost. PCs are the generative counterpart of decision forests, and as such can natively handle heterogeneous data as well as deliver tractable probabilistic generation and inference. Finally, in a rigorous empirical analysis we show that the apparent saturation of progress for SotA models is largely due to the use of inadequate metrics. As such, we highlight that there is still much to be done to generate realistic tabular data. Code available at https://github.com/april-tools/tabpc.
An Embarrassingly Simple Way to Optimize Orthogonal Matrices at Scale
Feb 16, 2026Orthogonality constraints are ubiquitous in robust and probabilistic machine learning. Unfortunately, current optimizers are computationally expensive and do not scale to problems with hundreds or thousands of constraints. One notable exception is the Landing algorithm (Ablin et al., 2024) which, however comes at the expense of temporarily relaxing orthogonality. In this work, we revisit and improve on the ideas behind Landing, enabling the inclusion of modern adaptive optimizers while ensuring that orthogonal constraints are effectively met. Remarkably, these improvements come at little to no cost, and reduce the number of required hyperparemeters. Our algorithm POGO is fast and GPU-friendly, consisting of only 5 matrix products, and in practice maintains orthogonality at all times. On several challenging benchmarks, POGO greatly outperforms recent optimizers and shows it can optimize problems with thousands of orthogonal matrices in minutes while alternatives would take hours. As such, POGO sets a milestone to finally exploit orthogonality constraints in ML at scale. A PyTorch implementation of POGO is publicly available at https://github.com/adrianjav/pogo.
How to Square Tensor Networks and Circuits Without Squaring Them
Dec 18, 2025Squared tensor networks (TNs) and their extension as computational graphs--squared circuits--have been used as expressive distribution estimators, yet supporting closed-form marginalization. However, the squaring operation introduces additional complexity when computing the partition function or marginalizing variables, which hinders their applicability in ML. To solve this issue, canonical forms of TNs are parameterized via unitary matrices to simplify the computation of marginals. However, these canonical forms do not apply to circuits, as they can represent factorizations that do not directly map to a known TN. Inspired by the ideas of orthogonality in canonical forms and determinism in circuits enabling tractable maximization, we show how to parameterize squared circuits to overcome their marginalization overhead. Our parameterizations unlock efficient marginalization even in factorizations different from TNs, but encoded as circuits, whose structure would otherwise make marginalization computationally hard. Finally, our experiments on distribution estimation show how our proposed conditions in squared circuits come with no expressiveness loss, while enabling more efficient learning.
DeCaFlow: A Deconfounding Causal Generative Model
Mar 19, 2025Causal generative models (CGMs) have recently emerged as capable approaches to simulate the causal mechanisms generating our observations, enabling causal inference. Unfortunately, existing approaches either are overly restrictive, assuming the absence of hidden confounders, or lack generality, being tailored to a particular query and graph. In this work, we introduce DeCaFlow, a CGM that accounts for hidden confounders in a single amortized training process using only observational data and the causal graph. Importantly, DeCaFlow can provably identify all causal queries with a valid adjustment set or sufficiently informative proxy variables. Remarkably, for the first time to our knowledge, we show that a confounded counterfactual query is identifiable, and thus solvable by DeCaFlow, as long as its interventional counterpart is as well. Our empirical results on diverse settings (including the Ecoli70 dataset, with 3 independent hidden confounders, tens of observed variables and hundreds of causal queries) show that DeCaFlow outperforms existing approaches, while demonstrating its out-of-the-box flexibility.
COPA: Comparing the Incomparable to Explore the Pareto Front
Mar 18, 2025



In machine learning (ML), it is common to account for multiple objectives when, e.g., selecting a model to deploy. However, it is often unclear how one should compare, aggregate and, ultimately, trade-off these objectives, as they might be measured in different units or scales. For example, when deploying large language models (LLMs), we might not only care about their performance, but also their CO2 consumption. In this work, we investigate how objectives can be sensibly compared and aggregated to navigate their Pareto front. To do so, we propose to make incomparable objectives comparable via their CDFs, approximated by their relative rankings. This allows us to aggregate them while matching user-specific preferences, allowing practitioners to meaningfully navigate and search for models in the Pareto front. We demonstrate the potential impact of our methodology in diverse areas such as LLM selection, domain generalization, and AutoML benchmarking, where classical ways to aggregate and normalize objectives fail.
Causal normalizing flows: from theory to practice
Jun 08, 2023



In this work, we deepen on the use of normalizing flows for causal reasoning. Specifically, we first leverage recent results on non-linear ICA to show that causal models are identifiable from observational data given a causal ordering, and thus can be recovered using autoregressive normalizing flows (NFs). Second, we analyze different design and learning choices for causal normalizing flows to capture the underlying causal data-generating process. Third, we describe how to implement the do-operator in causal NFs, and thus, how to answer interventional and counterfactual questions. Finally, in our experiments, we validate our design and training choices through a comprehensive ablation study; compare causal NFs to other approaches for approximating causal models; and empirically demonstrate that causal NFs can be used to address real-world problems, where the presence of mixed discrete-continuous data and partial knowledge on the causal graph is the norm. The code for this work can be found at https://github.com/psanch21/causal-flows.
Learnable Graph Convolutional Attention Networks
Nov 21, 2022Existing Graph Neural Networks (GNNs) compute the message exchange between nodes by either aggregating uniformly (convolving) the features of all the neighboring nodes, or by applying a non-uniform score (attending) to the features. Recent works have shown the strengths and weaknesses of the resulting GNN architectures, respectively, GCNs and GATs. In this work, we aim at exploiting the strengths of both approaches to their full extent. To this end, we first introduce the graph convolutional attention layer (CAT), which relies on convolutions to compute the attention scores. Unfortunately, as in the case of GCNs and GATs, we show that there exists no clear winner between the three (neither theoretically nor in practice) as their performance directly depends on the nature of the data (i.e., of the graph and features). This result brings us to the main contribution of our work, the learnable graph convolutional attention network (L-CAT): a GNN architecture that automatically interpolates between GCN, GAT and CAT in each layer, by adding only two scalar parameters. Our results demonstrate that L-CAT is able to efficiently combine different GNN layers along the network, outperforming competing methods in a wide range of datasets, and resulting in a more robust model that reduces the need of cross-validating.
Mitigating Modality Collapse in Multimodal VAEs via Impartial Optimization
Jun 09, 2022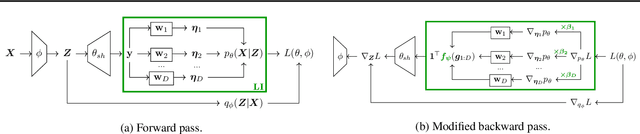
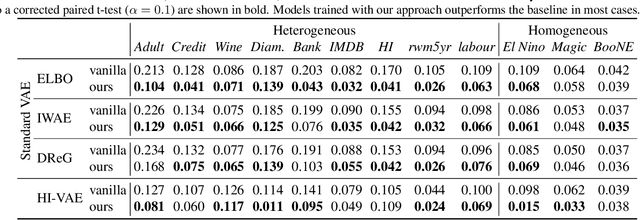
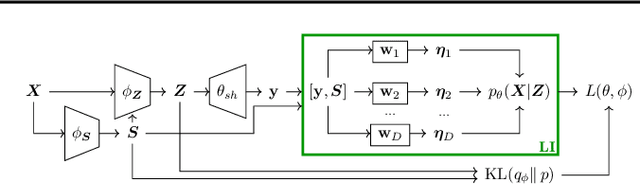
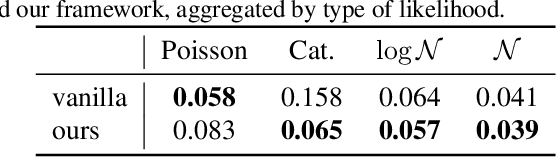
A number of variational autoencoders (VAEs) have recently emerged with the aim of modeling multimodal data, e.g., to jointly model images and their corresponding captions. Still, multimodal VAEs tend to focus solely on a subset of the modalities, e.g., by fitting the image while neglecting the caption. We refer to this limitation as modality collapse. In this work, we argue that this effect is a consequence of conflicting gradients during multimodal VAE training. We show how to detect the sub-graphs in the computational graphs where gradients conflict (impartiality blocks), as well as how to leverage existing gradient-conflict solutions from multitask learning to mitigate modality collapse. That is, to ensure impartial optimization across modalities. We apply our training framework to several multimodal VAE models, losses and datasets from the literature, and empirically show that our framework significantly improves the reconstruction performance, conditional generation, and coherence of the latent space across modalities.
Rotograd: Dynamic Gradient Homogenization for Multi-Task Learning
Mar 03, 2021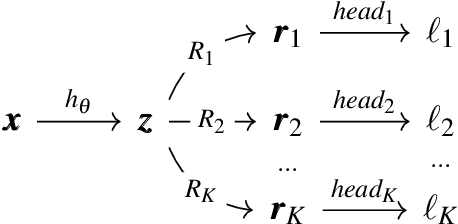
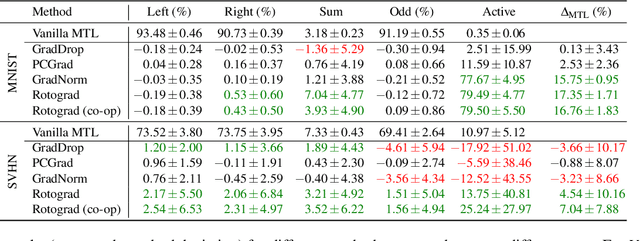
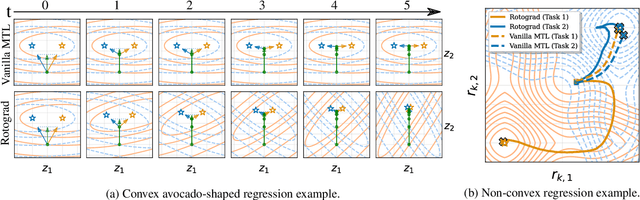
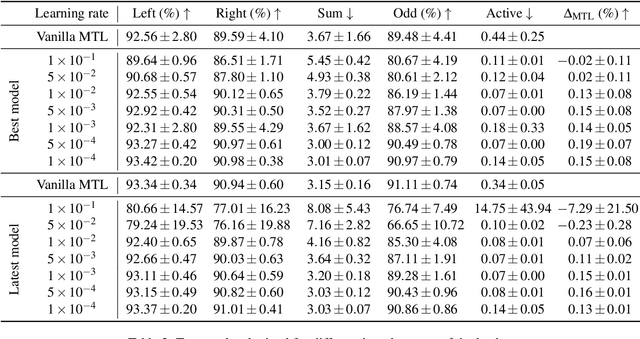
While multi-task learning (MTL) has been successfully applied in several domains, it still triggers challenges. As a consequence of negative transfer, simultaneously learning several tasks can lead to unexpectedly poor results. A key factor contributing to this undesirable behavior is the problem of conflicting gradients. In this paper, we propose a novel approach for MTL, Rotograd, which homogenizes the gradient directions across all tasks by rotating their shared representation. Our algorithm is formalized as a Stackelberg game, which allows us to provide stability guarantees. Rotograd can be transparently combined with task-weighting approaches (e.g., GradNorm) to mitigate negative transfer, resulting in a robust learning process. Thorough empirical evaluation on several architectures (e.g., ResNet) and datasets (e.g., CIFAR) verifies our theoretical results, and shows that Rotograd outperforms previous approaches. A Pytorch implementation can be found in https://github.com/adrianjav/rotograd .
Relative gradient optimization of the Jacobian term in unsupervised deep learning
Jun 26, 2020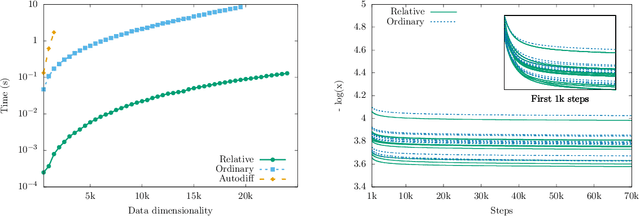
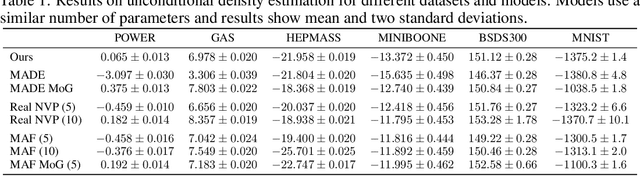

Learning expressive probabilistic models correctly describing the data is a ubiquitous problem in machine learning. A popular approach for solving it is mapping the observations into a representation space with a simple joint distribution, which can typically be written as a product of its marginals -- thus drawing a connection with the field of nonlinear independent component analysis. Deep density models have been widely used for this task, but their likelihood-based training requires estimating the log-determinant of the Jacobian and is computationally expensive, thus imposing a trade-off between computation and expressive power. In this work, we propose a new approach for exact likelihood-based training of such neural networks. Based on relative gradients, we exploit the matrix structure of neural network parameters to compute updates efficiently even in high-dimensional spaces; the computational cost of the training is quadratic in the input size, in contrast with the cubic scaling of the naive approaches. This allows fast training with objective functions involving the log-determinant of the Jacobian without imposing constraints on its structure, in stark contrast to normalizing flows. An implementation of our method can be found at https://github.com/fissoreg/relative-gradient-jacobian