 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Dynamics Reinforcement Learning via Domain Adaptation and Reward Augmented Imitation
Paper and Code
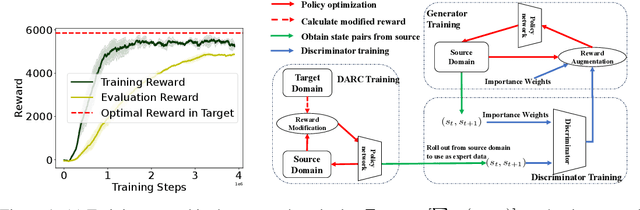
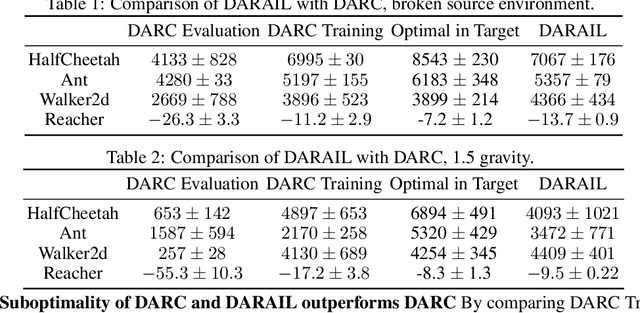
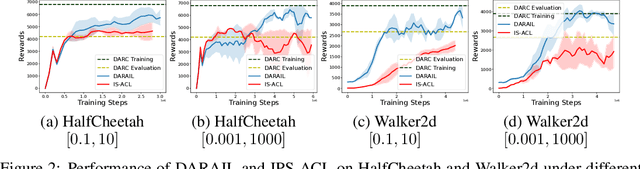
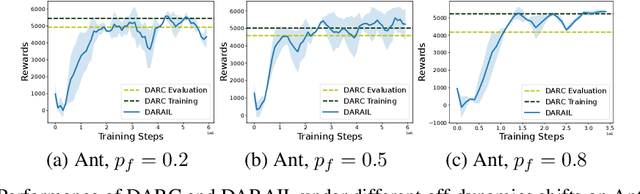
Training a policy in a source domain for deployment in the target domain under a dynamics shift can be challenging, often resulting in performance degradation. Previous work tackles this challenge by training on the source domain with modified rewards derived by matching distributions between the source and the target optimal trajectories. However, pure modified rewards only ensure the behavior of the learned policy in the source domain resembles trajectories produced by the target optimal policies, which does not guarantee optimal performance when the learned policy is actually deployed to the target domain. In this work, we propose to utilize imitation learning to transfer the policy learned from the reward modification to the target domain so that the new policy can generate the same trajectories in the target domain. Our approach, Domain Adaptation and Reward Augmented Imitation Learning (DARAIL), utilizes the reward modification for domain adaptation and follows the general framework of generative adversarial imitation learning from observation (GAIfO) by applying a reward augmented estimator for the policy optimization step. Theoretically, we present an error bound for our method under a mild assumption regarding the dynamics shift to justify the motivation of our method. Empirically, our method outperforms the pure modified reward method without imitation learning and also outperforms other baselines in benchmark off-dynamics environments.