 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeProPose: Deficiency-Proof 3D Human Pose Estimation via Adaptive Multi-View Fusion
Feb 23, 2025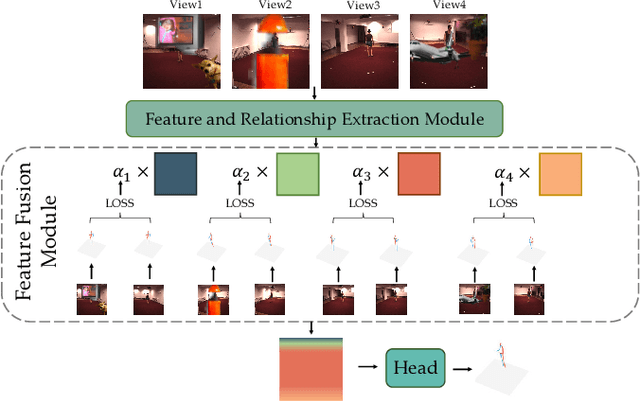
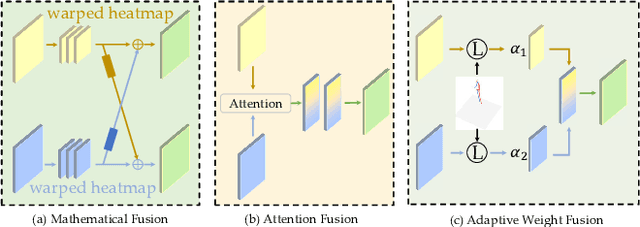
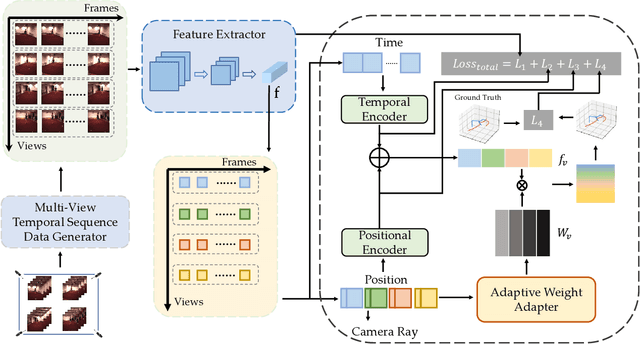
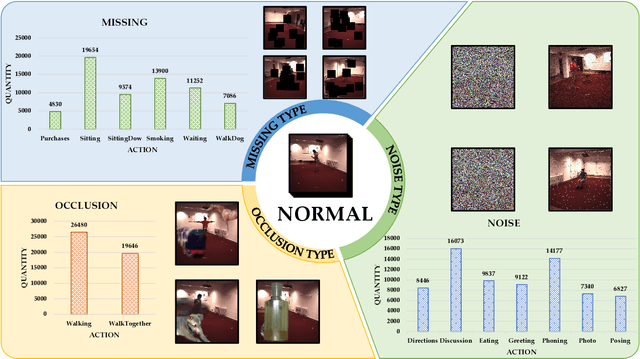
3D human pose estimation has wide applications in fields such as intelligent surveillance, motion capture, and virtual reality. However, in real-world scenarios, issues such as occlusion, noise interference, and missing viewpoints can severely affect pose estimation. To address these challenges, we introduce the task of Deficiency-Aware 3D Pose Estimation. Traditional 3D pose estimation methods often rely on multi-stage networks and modular combinations, which can lead to cumulative errors and increased training complexity, making them unable to effectively address deficiency-aware estimation. To this end, we propose DeProPose, a flexible method that simplifies the network architecture to reduce training complexity and avoid information loss in multi-stage designs. Additionally, the model innovatively introduces a multi-view feature fusion mechanism based on relative projection error, which effectively utilizes information from multiple viewpoints and dynamically assigns weights, enabling efficient integration and enhanced robustness to overcome deficiency-aware 3D Pose Estimation challenges. Furthermore, to thoroughly evaluate this end-to-end multi-view 3D human pose estimation model and to advance research on occlusion-related challenges, we have developed a novel 3D human pose estimation dataset, termed the Deficiency-Aware 3D Pose Estimation (DA-3DPE) dataset. This dataset encompasses a wide range of deficiency scenarios, including noise interference, missing viewpoints, and occlusion challenges. Compared to state-of-the-art methods, DeProPose not only excels in addressing the deficiency-aware problem but also shows improvement in conventional scenarios, providing a powerful and user-friendly solution for 3D human pose estimation. The source code will be available at https://github.com/WUJINHUAN/DeProPose.
Towards Precise 3D Human Pose Estimation with Multi-Perspective Spatial-Temporal Relational Transformers
Jan 30, 2024



3D human pose estimation captures the human joint points in three-dimensional space while keeping the depth information and physical structure. That is essential for applications that require precise pose information, such as human-computer interaction, scene understanding, and rehabilitation training. Due to the challenges in data collection, mainstream datasets of 3D human pose estimation are primarily composed of multi-view video data collected in laboratory environments, which contains rich spatial-temporal correlation information besides the image frame content. Given the remarkable self-attention mechanism of transformers, capable of capturing the spatial-temporal correlation from multi-view video datasets, we propose a multi-stage framework for 3D sequence-to-sequence (seq2seq) human pose detection. Firstly, the spatial module represents the human pose feature by intra-image content, while the frame-image relation module extracts temporal relationships and 3D spatial positional relationship features between the multi-perspective images. Secondly, the self-attention mechanism is adopted to eliminate the interference from non-human body parts and reduce computing resources. Our method is evaluated on Human3.6M, a popular 3D human pose detection dataset. Experimental results demonstrate that our approach achieves state-of-the-art performance on this dataset.
LF Tracy: A Unified Single-Pipeline Approach for Salient Object Detection in Light Field Cameras
Jan 30, 2024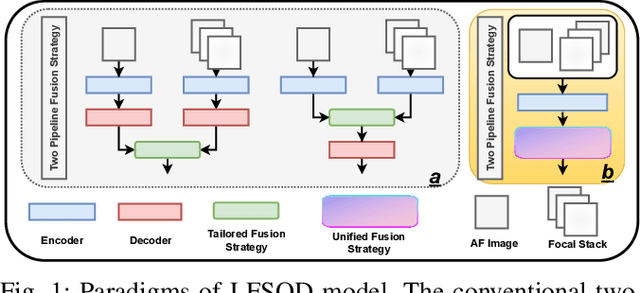
Leveraging the rich information extracted from light field (LF) cameras is instrumental for dense prediction tasks. However, adapting light field data to enhance Salient Object Detection (SOD) still follows the traditional RGB methods and remains under-explored in the community. Previous approaches predominantly employ a custom two-stream design to discover the implicit angular feature within light field cameras, leading to significant information isolation between different LF representations. In this study, we propose an efficient paradigm (LF Tracy) to address this limitation. We eschew the conventional specialized fusion and decoder architecture for a dual-stream backbone in favor of a unified, single-pipeline approach. This comprises firstly a simple yet effective data augmentation strategy called MixLD to bridge the connection of spatial, depth, and implicit angular information under different LF representations. A highly efficient information aggregation (IA) module is then introduced to boost asymmetric feature-wise information fusion. Owing to this innovative approach, our model surpasses the existing state-of-the-art methods, particularly demonstrating a 23% improvement over previous results on the latest large-scale PKU dataset. By utilizing only 28.9M parameters, the model achieves a 10% increase in accuracy with 3M additional parameters compared to its backbone using RGB images and an 86% rise to its backbone using LF images. The source code will be made publicly available at https://github.com/FeiBryantkit/LF-Tracy.