 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeProPose: Deficiency-Proof 3D Human Pose Estimation via Adaptive Multi-View Fusion
Paper and Code
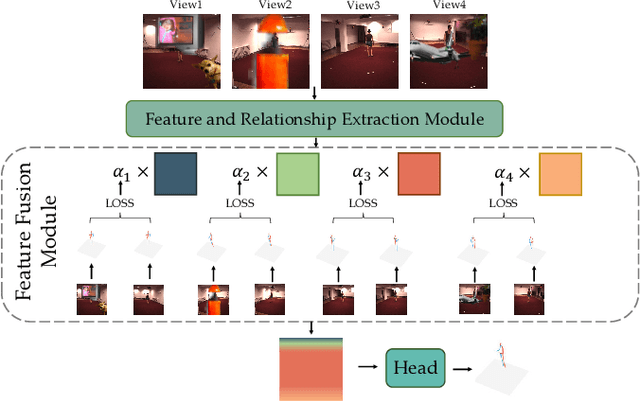
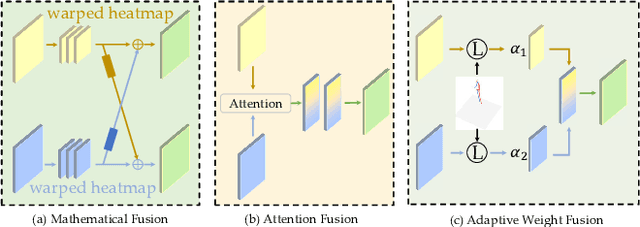
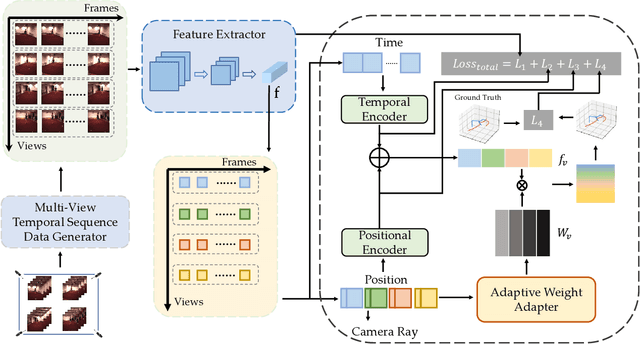
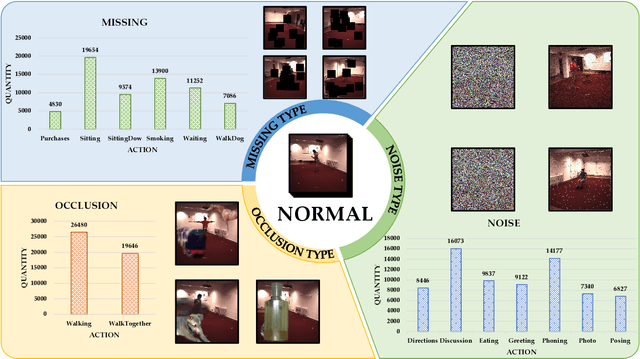
3D human pose estimation has wide applications in fields such as intelligent surveillance, motion capture, and virtual reality. However, in real-world scenarios, issues such as occlusion, noise interference, and missing viewpoints can severely affect pose estimation. To address these challenges, we introduce the task of Deficiency-Aware 3D Pose Estimation. Traditional 3D pose estimation methods often rely on multi-stage networks and modular combinations, which can lead to cumulative errors and increased training complexity, making them unable to effectively address deficiency-aware estimation. To this end, we propose DeProPose, a flexible method that simplifies the network architecture to reduce training complexity and avoid information loss in multi-stage designs. Additionally, the model innovatively introduces a multi-view feature fusion mechanism based on relative projection error, which effectively utilizes information from multiple viewpoints and dynamically assigns weights, enabling efficient integration and enhanced robustness to overcome deficiency-aware 3D Pose Estimation challenges. Furthermore, to thoroughly evaluate this end-to-end multi-view 3D human pose estimation model and to advance research on occlusion-related challenges, we have developed a novel 3D human pose estimation dataset, termed the Deficiency-Aware 3D Pose Estimation (DA-3DPE) dataset. This dataset encompasses a wide range of deficiency scenarios, including noise interference, missing viewpoints, and occlusion challenges. Compared to state-of-the-art methods, DeProPose not only excels in addressing the deficiency-aware problem but also shows improvement in conventional scenarios, providing a powerful and user-friendly solution for 3D human pose estimation. The source code will be available at https://github.com/WUJINHUAN/DeProPose.