 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Fairness Learning via Inverse Conditional Permutation
Apr 09, 2024Equalized odds, as a popular notion of algorithmic fairness, aims to ensure that sensitive variables, such as race and gender, do not unfairly influence the algorithm prediction when conditioning on the true outcome. Despite rapid advancements, most of the current research focuses on the violation of equalized odds caused by one sensitive attribute, leaving the challenge of simultaneously accounting for multiple attributes under-addressed. We address this gap by introducing a fairness learning approach that integrates adversarial learning with a novel inverse conditional permutation. This approach effectively and flexibly handles multiple sensitive attributes, potentially of mixed data types. The efficacy and flexibility of our method are demonstrated through both simulation studies and empirical analysis of real-world datasets.
Conformalized semi-supervised random forest for classification and abnormality detection
Feb 04, 2023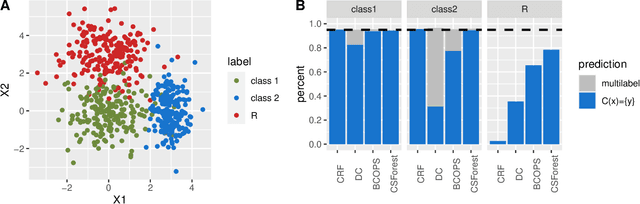
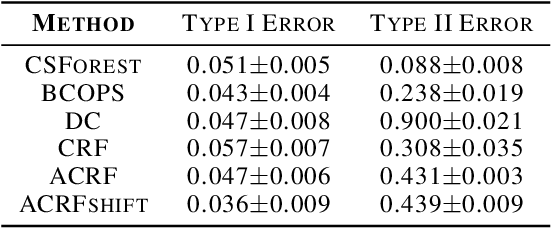
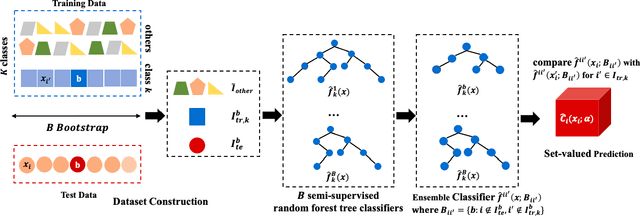
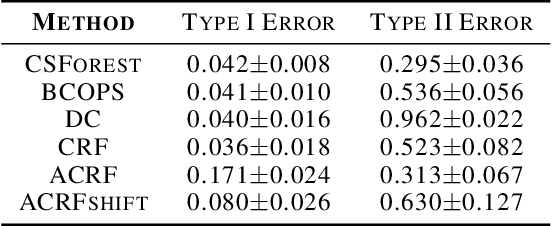
Traditional classifiers infer labels under the premise that the training and test samples are generated from the same distribution. This assumption can be problematic for safety-critical applications such as medical diagnosis and network attack detection. In this paper, we consider the multi-class classification problem when the training data and the test data may have different distributions. We propose conformalized semi-supervised random forest (CSForest), which constructs set-valued predictions $C(x)$ to include the correct class label with desired probability while detecting outliers efficiently. We compare the proposed method to other state-of-art methods in both a synthetic example and a real data application to demonstrate the strength of our proposal.
GAN-based federated learning for label protection in binary classification
Feb 04, 2023



As an emerging technique, vertical federated learning collaborates with different data sources to jointly train a machine learning model without data exchange. However, federated learning is computationally expensive and inefficient in modeling due to complex encryption algorithms and secure computation protocols. Split learning offers an alternative solution to circumvent these challenges. Despite this, vanilla split learning still suffers privacy leakage. Here, we propose the Generative Adversarial Federated Model (GAFM), which integrates the vanilla split learning framework with the Generative Adversarial Network (GAN) for protection against label leakage from gradients in binary classification tasks. We compare our proposal to existing models, including Marvell, Max Norm, and SplitNN, on three publicly available datasets, where GAFM shows significant improvement regarding the trade-off between classification accuracy and label privacy protection. We also provide heuristic justification for why GAFM can improve over baselines and demonstrate that GAFM offers label protection through gradient perturbation compared to SplitNN.
$\ell_1$-norm constrained multi-block sparse canonical correlation analysis via proximal gradient descent
Jan 14, 2022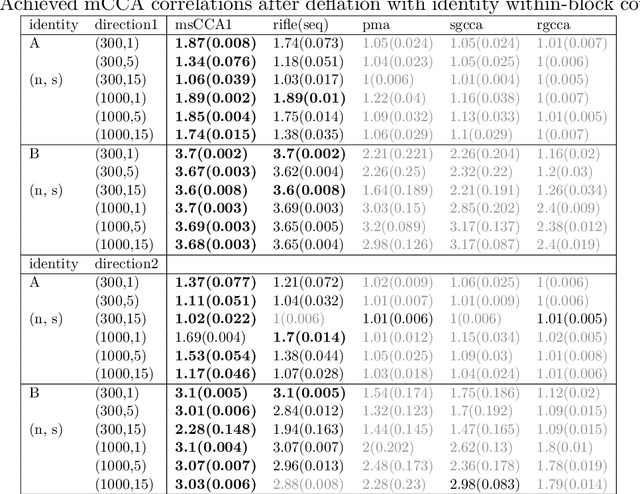
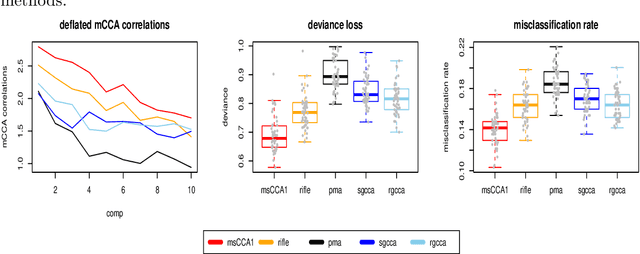
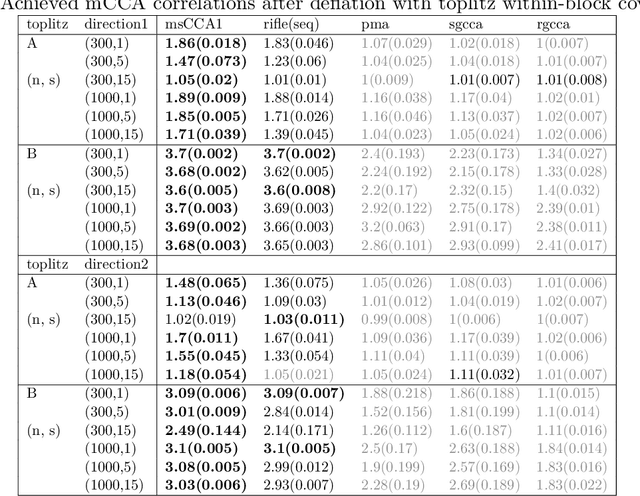
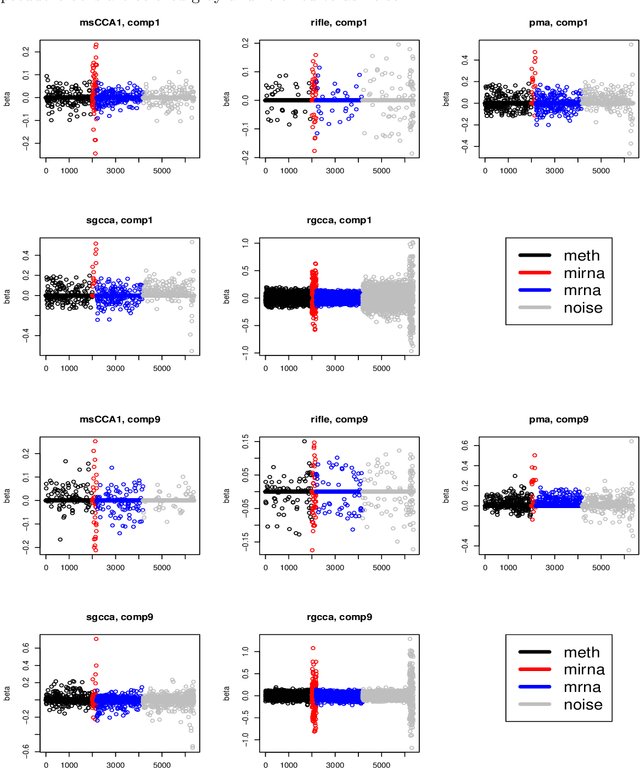
Multi-block CCA constructs linear relationships explaining coherent variations across multiple blocks of data. We view the multi-block CCA problem as finding leading generalized eigenvectors and propose to solve it via a proximal gradient descent algorithm with $\ell_1$ constraint for high dimensional data. In particular, we use a decaying sequence of constraints over proximal iterations, and show that the resulting estimate is rate-optimal under suitable assumptions. Although several previous works have demonstrated such optimality for the $\ell_0$ constrained problem using iterative approaches, the same level of theoretical understanding for the $\ell_1$ constrained formulation is still lacking. We also describe an easy-to-implement deflation procedure to estimate multiple eigenvectors sequentially. We compare our proposals to several existing methods whose implementations are available on R CRAN, and the proposed methods show competitive performances in both simulations and a real data example.
Prediction and outlier detection: a distribution-free prediction set with a balanced objective
May 14, 2019



We consider the multi-class classification problem when the training data and the out-of-sample test data may have different distributions and propose a method called BCOPS (balanced and conformal optimized prediction set) that constructs a prediction set C(x) which tries to optimize out-of-sample performance, aiming to include the correct class as often as possible, but also detecting outliers x, for which the method returns no prediction (corresponding to C(x) equal to the empty set). BCOPS combines supervised-learning algorithms with the method of conformal prediction to minimize a misclassification loss averaged over the out-of-sample distribution. The constructed prediction sets have a finite-sample coverage guarantee without distributional assumptions. We also develop a variant of BCOPS in the online setting where we optimize the misclassification loss averaged over a proxy of the out-of-sample distribution. We also describe new methods for the evaluation of out-of-sample performance with mismatched data. We prove asymptotic consistency and efficiency of the proposed methods under suitable assumptions and illustrate our methods on real data examples.