 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndowing Deep 3D Models with Rotation Invariance Based on Principal Component Analysis
Oct 20, 2019



In this paper, we propose a simple yet effective method to endow deep 3D models with rotation invariance by expressing the coordinates in an intrinsic frame determined by the object shape itself. Key to our approach is to find such an intrinsic frame which should be unique to the identical object shape and consistent across different instances of the same category, e.g. the frame axes of desks should be all roughly along the edges. Interestingly, the principal component analysis exactly provides an effective way to define such a frame, i.e. setting the principal components as the frame axes. As the principal components have direction ambiguity caused by the sign-ambiguity of eigenvector computation, there exist several intrinsic frames for each object. In order to achieve absolute rotation invariance for a deep model, we adopt the coordinates expressed in all intrinsic frames as inputs to obtain multiple output features, which will be further aggregated as a final feature via a self-attention module. Our method is theoretically rotation-invariant and can be flexibly embedded into the current network architectures. Comprehensive experiments demonstrate that our approach can achieve near state-of-the-art performance on rotation-augmented dataset for ModelNet40 classification and outperform other models on SHREC'17 perturbed retrieval task.
Justlookup: One Millisecond Deep Feature Extraction for Point Clouds By Lookup Tables
Aug 14, 2019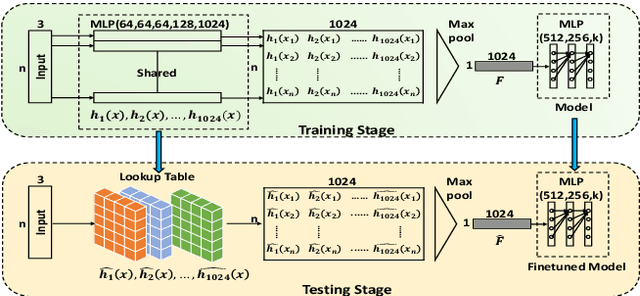



Deep models are capable of fitting complex high dimensional functions while usually yielding large computation load. There is no way to speed up the inference process by classical lookup tables due to the high-dimensional input and limited memory size. Recently, a novel architecture (PointNet) for point clouds has demonstrated that it is possible to obtain a complicated deep function from a set of 3-variable functions. In this paper, we exploit this property and apply a lookup table to encode these 3-variable functions. This method ensures that the inference time is only determined by the memory access no matter how complicated the deep function is. We conduct extensive experiments on ModelNet and ShapeNet datasets and demonstrate that we can complete the inference process in 1.5 ms on an Intel i7-8700 CPU (single core mode), 32x speedup over the PointNet architecture without any performance degradation.
Face Recognition from Sequential Sparse 3D data via Deep Registration
Oct 23, 2018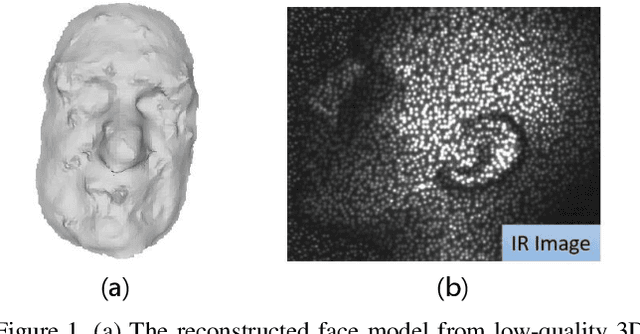

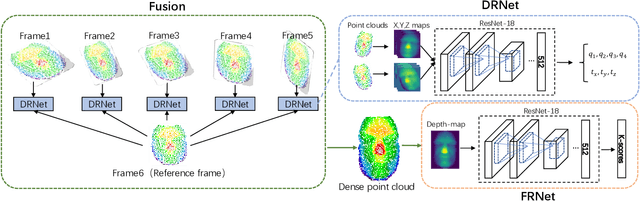
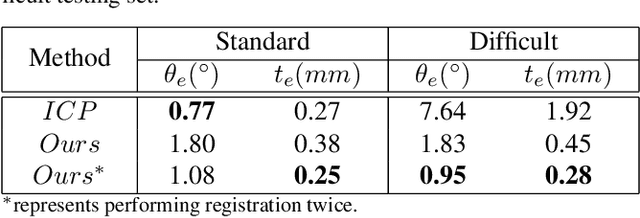
Previous works have shown that face recognition with high accuracy 3D data is more reliable and insensitive to pose and light variations. Recently, low-cost and portable 3D acquisition techniques like ToF(Time of Flight) and DoE based structured light enable us to access 3D data easily, e.g. via a mobile phone. However, these devices can only provide sparse(limited speckles in structured light system) and noisy 3D data which can not support face recognition directly. In this paper, we aim at achieving high performance face recognition for devices equipped with such modules which is very meaningful in practice as such devices will be very popular. We propose a framework to perform face recognition by fusing a sequence of low-quality 3D data. As 3D data are sparse and noisy which can not be well handled by conventional methods like the ICP algorithm, we design a PointNet-like Deep Registration Network(DRNet) which works with ordered 3D point coordinates while preserving the ability of mining local structures via convolution. Meanwhile we develop a novel loss function to optimize our DRNet based on the quaternion expression which obviously outperforms other widely used functions. For face recognition, we design a deep convolutional network which takes the fused 3D depth-map as input based on AMSoftmax model. Experiments show that our DRNet can achieve rotation error 0.95 degrees and translation error 0.28mm for registration. The face recognition on fused data also achieves rank-1 accuracy 99.2%, FAR-0.001 97.5% on Bosphorus dataset which is comparable with state-of-the-art high-quality data based recognition performance.
Automatically Building Face Datasets of New Domains from Weakly Labeled Data with Pretrained Models
Nov 24, 2016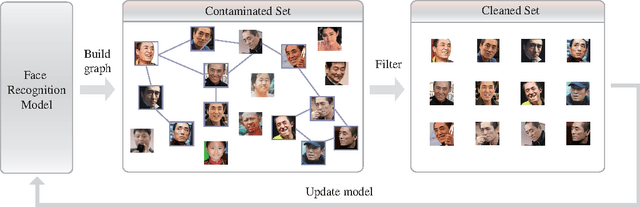
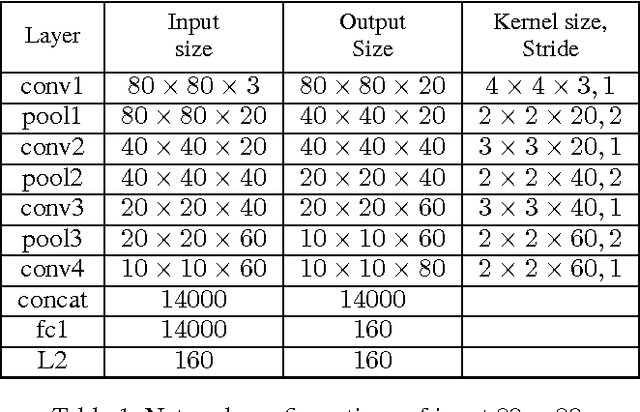
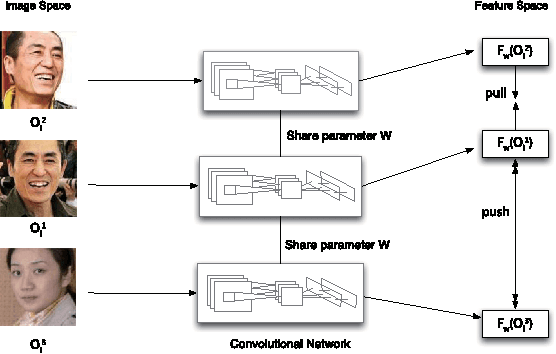
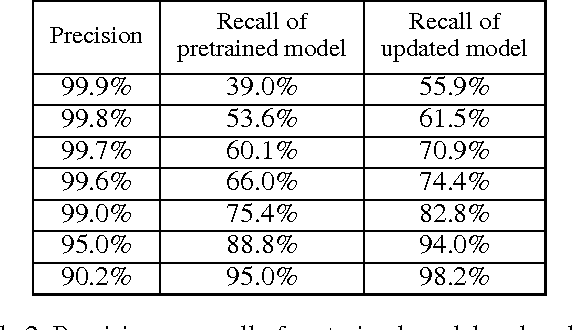
Training data are critical in face recognition systems. However, labeling a large scale face data for a particular domain is very tedious. In this paper, we propose a method to automatically and incrementally construct datasets from massive weakly labeled data of the target domain which are readily available on the Internet under the help of a pretrained face model. More specifically, given a large scale weakly labeled dataset in which each face image is associated with a label, i.e. the name of an identity, we create a graph for each identity with edges linking matched faces verified by the existing model under a tight threshold. Then we use the maximal subgraph as the cleaned data for that identity. With the cleaned dataset, we update the existing face model and use the new model to filter the original dataset to get a larger cleaned dataset. We collect a large weakly labeled dataset containing 530,560 Asian face images of 7,962 identities from the Internet, which will be published for the study of face recognition. By running the filtering process, we obtain a cleaned datasets (99.7+% purity) of size 223,767 (recall 70.9%). On our testing dataset of Asian faces, the model trained by the cleaned dataset achieves recognition rate 93.1%, which obviously outperforms the model trained by the public dataset CASIA whose recognition rate is 85.9%.
Deep Joint Face Hallucination and Recognition
Nov 24, 2016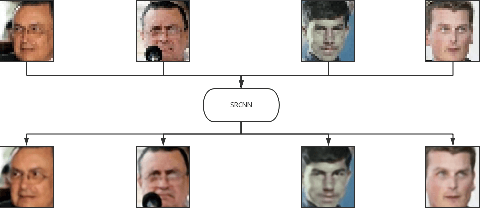

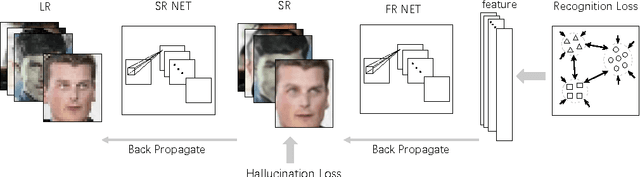
Deep models have achieved impressive performance for face hallucination tasks. However, we observe that directly feeding the hallucinated facial images into recog- nition models can even degrade the recognition performance despite the much better visualization quality. In this paper, we address this problem by jointly learning a deep model for two tasks, i.e. face hallucination and recognition. In particular, we design an end-to-end deep convolution network with hallucination sub-network cascaded by recognition sub-network. The recognition sub- network are responsible for producing discriminative feature representations using the hallucinated images as inputs generated by hallucination sub-network. During training, we feed LR facial images into the network and optimize the parameters by minimizing two loss items, i.e. 1) face hallucination loss measured by the pixel wise difference between the ground truth HR images and network-generated images; and 2) verification loss which is measured by the classification error and intra-class distance. We extensively evaluate our method on LFW and YTF datasets. The experimental results show that our method can achieve recognition accuracy 97.95% on 4x down-sampled LFW testing set, outperforming the accuracy 96.35% of conventional face recognition model. And on the more challenging YTF dataset, we achieve recognition accuracy 90.65%, a margin over the recognition accuracy 89.45% obtained by conventional face recognition model on the 4x down-sampled version.
DARI: Distance metric And Representation Integration for Person Verification
Apr 15, 2016
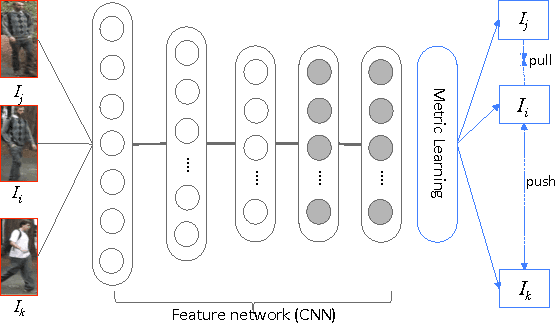
The past decade has witnessed the rapid development of feature representation learning and distance metric learning, whereas the two steps are often discussed separately. To explore their interaction, this work proposes an end-to-end learning framework called DARI, i.e. Distance metric And Representation Integration, and validates the effectiveness of DARI in the challenging task of person verification. Given the training images annotated with the labels, we first produce a large number of triplet units, and each one contains three images, i.e. one person and the matched/mismatch references. For each triplet unit, the distance disparity between the matched pair and the mismatched pair tends to be maximized. We solve this objective by building a deep architecture of convolutional neural networks. In particular, the Mahalanobis distance matrix is naturally factorized as one top fully-connected layer that is seamlessly integrated with other bottom layers representing the image feature. The image feature and the distance metric can be thus simultaneously optimized via the one-shot backward propagation. On several public datasets, DARI shows very promising performance on re-identifying individuals cross cameras against various challenges, and outperforms other state-of-the-art approaches.
Unconstrained Facial Landmark Localization with Backbone-Branches Fully-Convolutional Networks
Apr 14, 2016



This paper investigates how to rapidly and accurately localize facial landmarks in unconstrained, cluttered environments rather than in the well segmented face images. We present a novel Backbone-Branches Fully-Convolutional Neural Network (BB-FCN), which produces facial landmark response maps directly from raw images without relying on pre-process or sliding window approaches. BB-FCN contains one backbone and a number of network branches with each corresponding to one landmark type, and it operates in a progressive manner. Specifically, the backbone roughly detects the locations of facial landmarks by taking the whole image as input, and the branches further refine the localizations based on a local observation from the backbone's intermediate feature map. Moreover, our backbone-branches architecture does not contain full-connection layers for location regression, leading to efficient learning and inference. Our extensive experiments show that our model achieves superior performances over other state-of-the-arts under both the constrained (i.e. with face regions) and the "in the wild" scenarios.
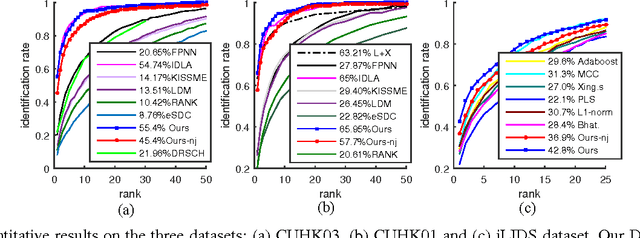
Deep Feature Learning with Relative Distance Comparison for Person Re-identification
Dec 11, 2015
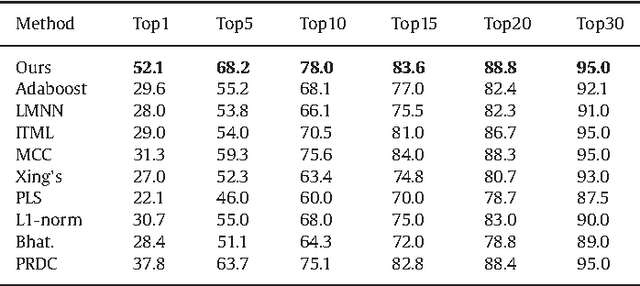
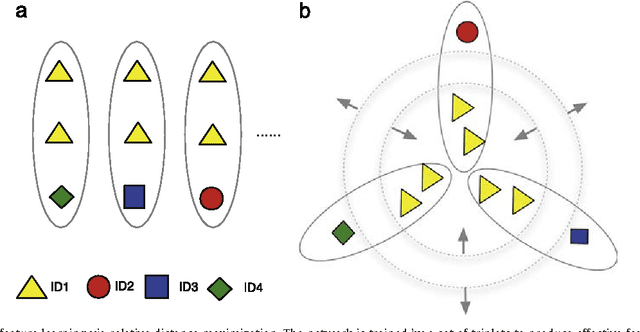
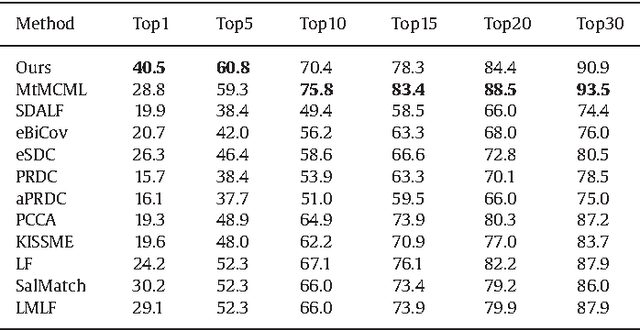
Identifying the same individual across different scenes is an important yet difficult task in intelligent video surveillance. Its main difficulty lies in how to preserve similarity of the same person against large appearance and structure variation while discriminating different individuals. In this paper, we present a scalable distance driven feature learning framework based on the deep neural network for person re-identification, and demonstrate its effectiveness to handle the existing challenges. Specifically, given the training images with the class labels (person IDs), we first produce a large number of triplet units, each of which contains three images, i.e. one person with a matched reference and a mismatched reference. Treating the units as the input, we build the convolutional neural network to generate the layered representations, and follow with the $L2$ distance metric. By means of parameter optimization, our framework tends to maximize the relative distance between the matched pair and the mismatched pair for each triplet unit. Moreover, a nontrivial issue arising with the framework is that the triplet organization cubically enlarges the number of training triplets, as one image can be involved into several triplet units. To overcome this problem, we develop an effective triplet generation scheme and an optimized gradient descent algorithm, making the computational load mainly depends on the number of original images instead of the number of triplets. On several challenging databases, our approach achieves very promising results and outperforms other state-of-the-art approaches.
End-to-End Photo-Sketch Generation via Fully Convolutional Representation Learning
Apr 11, 2015
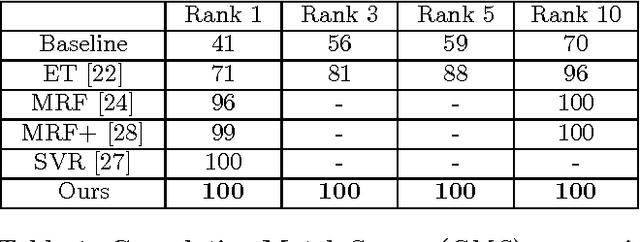
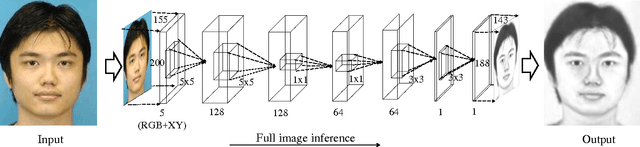

Sketch-based face recognition is an interesting task in vision and multimedia research, yet it is quite challenging due to the great difference between face photos and sketches. In this paper, we propose a novel approach for photo-sketch generation, aiming to automatically transform face photos into detail-preserving personal sketches. Unlike the traditional models synthesizing sketches based on a dictionary of exemplars, we develop a fully convolutional network to learn the end-to-end photo-sketch mapping. Our approach takes whole face photos as inputs and directly generates the corresponding sketch images with efficient inference and learning, in which the architecture are stacked by only convolutional kernels of very small sizes. To well capture the person identity during the photo-sketch transformation, we define our optimization objective in the form of joint generative-discriminative minimization. In particular, a discriminative regularization term is incorporated into the photo-sketch generation, enhancing the discriminability of the generated person sketches against other individuals. Extensive experiments on several standard benchmarks suggest that our approach outperforms other state-of-the-art methods in both photo-sketch generation and face sketch verification.