 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Building Face Datasets of New Domains from Weakly Labeled Data with Pretrained Models
Paper and Code
Nov 24, 2016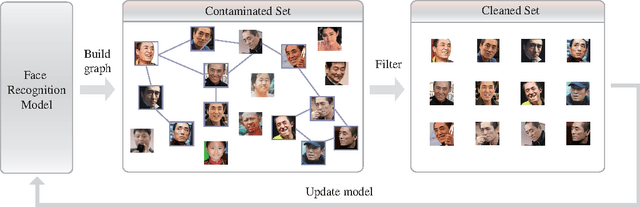
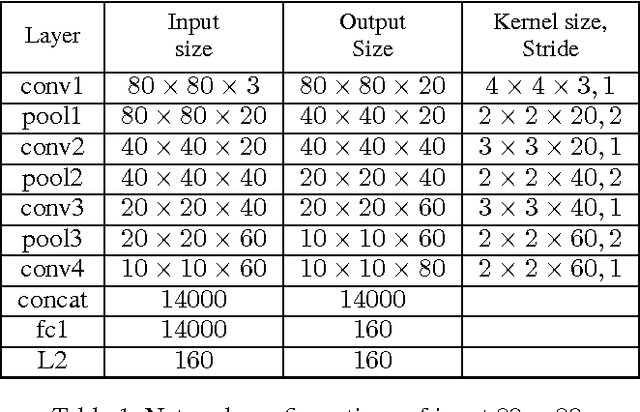
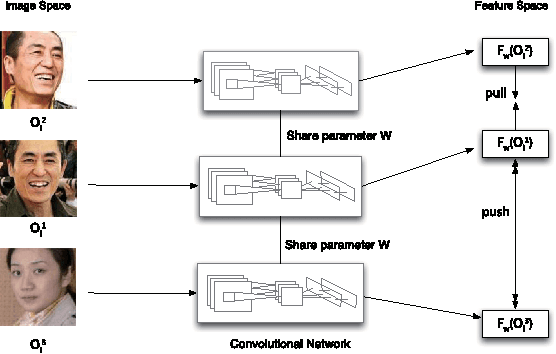
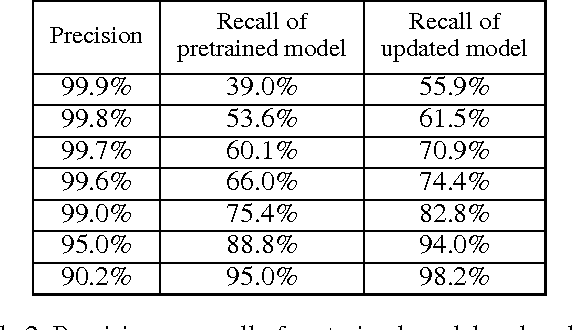
Training data are critical in face recognition systems. However, labeling a large scale face data for a particular domain is very tedious. In this paper, we propose a method to automatically and incrementally construct datasets from massive weakly labeled data of the target domain which are readily available on the Internet under the help of a pretrained face model. More specifically, given a large scale weakly labeled dataset in which each face image is associated with a label, i.e. the name of an identity, we create a graph for each identity with edges linking matched faces verified by the existing model under a tight threshold. Then we use the maximal subgraph as the cleaned data for that identity. With the cleaned dataset, we update the existing face model and use the new model to filter the original dataset to get a larger cleaned dataset. We collect a large weakly labeled dataset containing 530,560 Asian face images of 7,962 identities from the Internet, which will be published for the study of face recognition. By running the filtering process, we obtain a cleaned datasets (99.7+% purity) of size 223,767 (recall 70.9%). On our testing dataset of Asian faces, the model trained by the cleaned dataset achieves recognition rate 93.1%, which obviously outperforms the model trained by the public dataset CASIA whose recognition rate is 85.9%.