 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePure-Pass: Fine-Grained, Adaptive Masking for Dynamic Token-Mixing Routing in Lightweight Image Super-Resolution
Oct 02, 2025Image Super-Resolution (SR) aims to reconstruct high-resolution images from low-resolution counterparts, but the computational complexity of deep learning-based methods often hinders practical deployment. CAMixer is the pioneering work to integrate the advantages of existing lightweight SR methods and proposes a content-aware mixer to route token mixers of varied complexities according to the difficulty of content recovery. However, several limitations remain, such as poor adaptability, coarse-grained masking and spatial inflexibility, among others. We propose Pure-Pass (PP), a pixel-level masking mechanism that identifies pure pixels and exempts them from expensive computations. PP utilizes fixed color center points to classify pixels into distinct categories, enabling fine-grained, spatially flexible masking while maintaining adaptive flexibility. Integrated into the state-of-the-art ATD-light model, PP-ATD-light achieves superior SR performance with minimal overhead, outperforming CAMixer-ATD-light in reconstruction quality and parameter efficiency when saving a similar amount of computation.
WeChat-YATT: A Simple, Scalable and Balanced RLHF Trainer
Aug 11, 2025Reinforcement Learning from Human Feedback (RLHF) has emerged as a prominent paradigm for training large language models and multimodal systems. Despite notable advances enabled by existing RLHF training frameworks, significant challenges remain in scaling to complex multimodal workflows and adapting to dynamic workloads. In particular, current systems often encounter limitations related to controller scalability when managing large models, as well as inefficiencies in orchestrating intricate RLHF pipelines, especially in scenarios that require dynamic sampling and resource allocation. In this paper, we introduce WeChat-YATT (Yet Another Transformer Trainer in WeChat), a simple, scalable, and balanced RLHF training framework specifically designed to address these challenges. WeChat-YATT features a parallel controller programming model that enables flexible and efficient orchestration of complex RLHF workflows, effectively mitigating the bottlenecks associated with centralized controller architectures and facilitating scalability in large-scale data scenarios. In addition, we propose a dynamic placement schema that adaptively partitions computational resources and schedules workloads, thereby significantly reducing hardware idle time and improving GPU utilization under variable training conditions. We evaluate WeChat-YATT across a range of experimental scenarios, demonstrating that it achieves substantial improvements in throughput compared to state-of-the-art RLHF training frameworks. Furthermore, WeChat-YATT has been successfully deployed to train models supporting WeChat product features for a large-scale user base, underscoring its effectiveness and robustness in real-world applications.
G-Core: A Simple, Scalable and Balanced RLHF Trainer
Jul 30, 2025Reinforcement Learning from Human Feedback (RLHF) has become an increasingly popular paradigm for training large language models (LLMs) and diffusion models. While existing RLHF training systems have enabled significant progress, they often face challenges in scaling to multi-modal and diffusion workflows and adapting to dynamic workloads. In particular, current approaches may encounter limitations in controller scalability, flexible resource placement, and efficient orchestration when handling complex RLHF pipelines, especially in scenarios involving dynamic sampling or generative reward modeling. In this paper, we present \textbf{G-Core}, a simple, scalable, and balanced RLHF training framework designed to address these challenges. G-Core introduces a parallel controller programming model, enabling flexible and efficient orchestration of complex RLHF workflows without the bottlenecks of a single centralized controller. Furthermore, we propose a dynamic placement schema that adaptively partitions resources and schedules workloads, significantly reducing hardware idle time and improving utilization, even under highly variable training conditions. G-Core has successfully trained models that support WeChat product features serving a large-scale user base, demonstrating its effectiveness and robustness in real-world scenarios. Our results show that G-Core advances the state of the art in RLHF training, providing a solid foundation for future research and deployment of large-scale, human-aligned models.
Automatically Building Face Datasets of New Domains from Weakly Labeled Data with Pretrained Models
Nov 24, 2016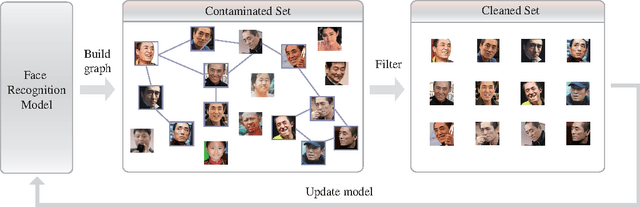
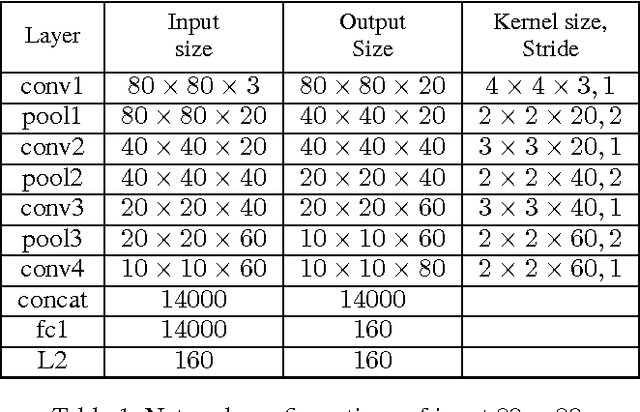
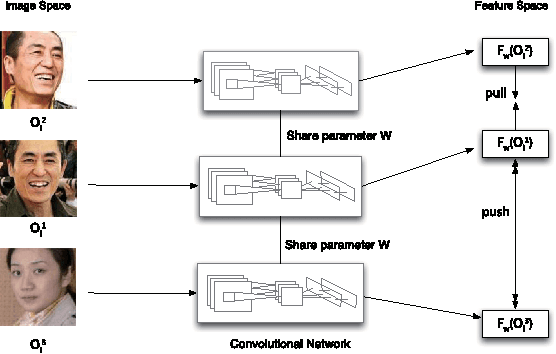
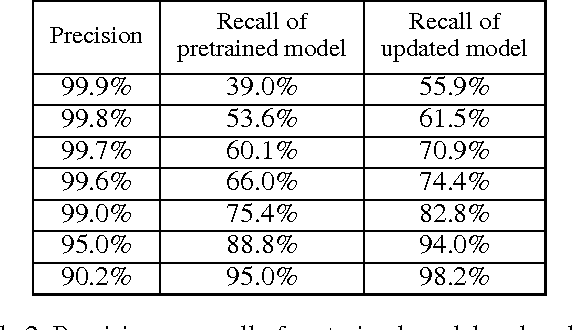
Training data are critical in face recognition systems. However, labeling a large scale face data for a particular domain is very tedious. In this paper, we propose a method to automatically and incrementally construct datasets from massive weakly labeled data of the target domain which are readily available on the Internet under the help of a pretrained face model. More specifically, given a large scale weakly labeled dataset in which each face image is associated with a label, i.e. the name of an identity, we create a graph for each identity with edges linking matched faces verified by the existing model under a tight threshold. Then we use the maximal subgraph as the cleaned data for that identity. With the cleaned dataset, we update the existing face model and use the new model to filter the original dataset to get a larger cleaned dataset. We collect a large weakly labeled dataset containing 530,560 Asian face images of 7,962 identities from the Internet, which will be published for the study of face recognition. By running the filtering process, we obtain a cleaned datasets (99.7+% purity) of size 223,767 (recall 70.9%). On our testing dataset of Asian faces, the model trained by the cleaned dataset achieves recognition rate 93.1%, which obviously outperforms the model trained by the public dataset CASIA whose recognition rate is 85.9%.
Deep Joint Face Hallucination and Recognition
Nov 24, 2016

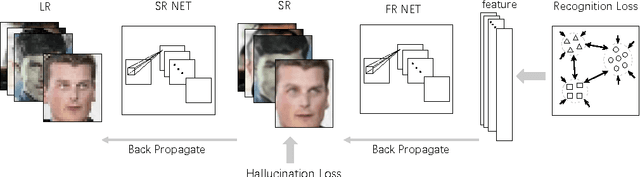
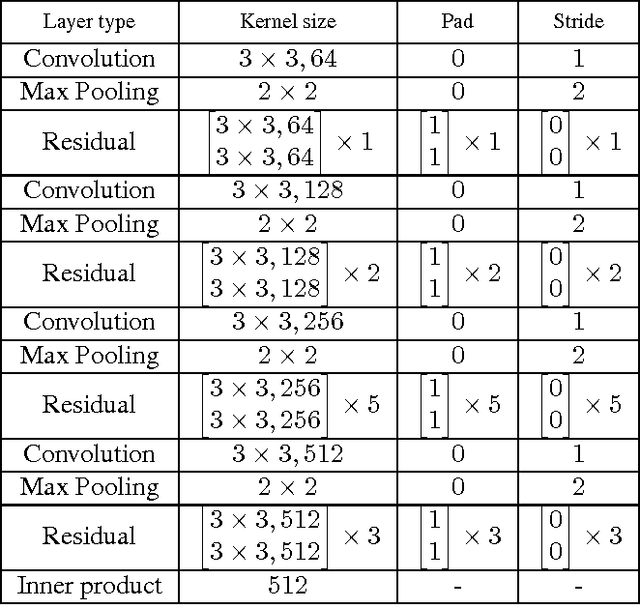
Deep models have achieved impressive performance for face hallucination tasks. However, we observe that directly feeding the hallucinated facial images into recog- nition models can even degrade the recognition performance despite the much better visualization quality. In this paper, we address this problem by jointly learning a deep model for two tasks, i.e. face hallucination and recognition. In particular, we design an end-to-end deep convolution network with hallucination sub-network cascaded by recognition sub-network. The recognition sub- network are responsible for producing discriminative feature representations using the hallucinated images as inputs generated by hallucination sub-network. During training, we feed LR facial images into the network and optimize the parameters by minimizing two loss items, i.e. 1) face hallucination loss measured by the pixel wise difference between the ground truth HR images and network-generated images; and 2) verification loss which is measured by the classification error and intra-class distance. We extensively evaluate our method on LFW and YTF datasets. The experimental results show that our method can achieve recognition accuracy 97.95% on 4x down-sampled LFW testing set, outperforming the accuracy 96.35% of conventional face recognition model. And on the more challenging YTF dataset, we achieve recognition accuracy 90.65%, a margin over the recognition accuracy 89.45% obtained by conventional face recognition model on the 4x down-sampled version.