 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreast Ultrasound Tumor Generation via Mask Generator and Text-Guided Network:A Clinically Controllable Framework with Downstream Evaluation
Jul 10, 2025The development of robust deep learning models for breast ultrasound (BUS) image analysis is significantly constrained by the scarcity of expert-annotated data. To address this limitation, we propose a clinically controllable generative framework for synthesizing BUS images. This framework integrates clinical descriptions with structural masks to generate tumors, enabling fine-grained control over tumor characteristics such as morphology, echogencity, and shape. Furthermore, we design a semantic-curvature mask generator, which synthesizes structurally diverse tumor masks guided by clinical priors. During inference, synthetic tumor masks serve as input to the generative framework, producing highly personalized synthetic BUS images with tumors that reflect real-world morphological diversity. Quantitative evaluations on six public BUS datasets demonstrate the significant clinical utility of our synthetic images, showing their effectiveness in enhancing downstream breast cancer diagnosis tasks. Furthermore, visual Turing tests conducted by experienced sonographers confirm the realism of the generated images, indicating the framework's potential to support broader clinical applications.
Computationally Efficient Unsupervised Deep Learning for Robust Joint AP Clustering and Beamforming Design in Cell-Free Systems
Apr 03, 2024In this paper, we consider robust joint access point (AP) clustering and beamforming design with imperfect channel state information (CSI) in cell-free systems. Specifically, we jointly optimize AP clustering and beamforming with imperfect CSI to simultaneously maximize the worst-case sum rate and minimize the number of AP clustering under power constraint and the sparsity constraint of AP clustering. By transformations, the semi-infinite constraints caused by the imperfect CSI are converted into more tractable forms for facilitating a computationally efficient unsupervised deep learning algorithm. In addition, to further reduce the computational complexity, a computationally effective unsupervised deep learning algorithm is proposed to implement robust joint AP clustering and beamforming design with imperfect CSI in cell-free systems. Numerical results demonstrate that the proposed unsupervised deep learning algorithm achieves a higher worst-case sum rate under a smaller number of AP clustering with computational efficiency.
AMPose: Alternatively Mixed Global-Local Attention Model for 3D Human Pose Estimation
Oct 11, 2022
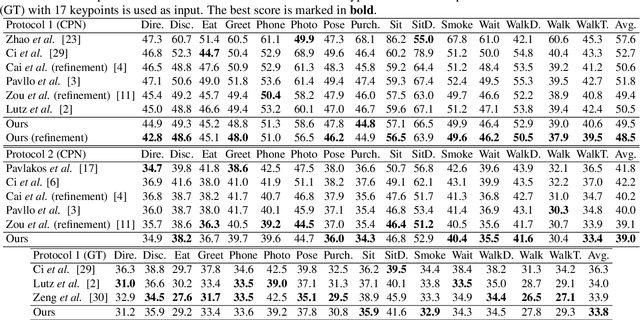
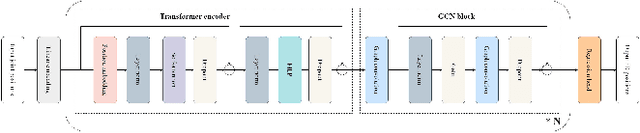
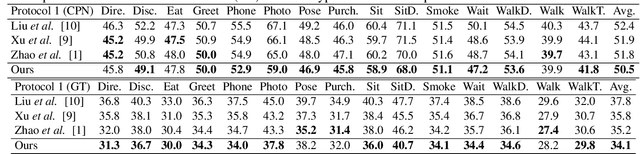
The graph convolutional network has been applied to 3D human pose estimation. In addition, the pure transformer model recently show the promising result in the video-based method. However, the single-frame method still need to model the physically connected relations among joints because the feature representation transformed only by the global attention has the lack of the relationships of human skeleton. We propose a novel architecture to combine the physically connected and global relations among joints in human. We evaluate our method on Human3.6m and compare with the state-of-the-art models. Our model show superior result over all other models. Our model has better generalization ability by cross-dataset comparison on MPI-INF-3DHP.
Endowing Deep 3D Models with Rotation Invariance Based on Principal Component Analysis
Oct 20, 2019



In this paper, we propose a simple yet effective method to endow deep 3D models with rotation invariance by expressing the coordinates in an intrinsic frame determined by the object shape itself. Key to our approach is to find such an intrinsic frame which should be unique to the identical object shape and consistent across different instances of the same category, e.g. the frame axes of desks should be all roughly along the edges. Interestingly, the principal component analysis exactly provides an effective way to define such a frame, i.e. setting the principal components as the frame axes. As the principal components have direction ambiguity caused by the sign-ambiguity of eigenvector computation, there exist several intrinsic frames for each object. In order to achieve absolute rotation invariance for a deep model, we adopt the coordinates expressed in all intrinsic frames as inputs to obtain multiple output features, which will be further aggregated as a final feature via a self-attention module. Our method is theoretically rotation-invariant and can be flexibly embedded into the current network architectures. Comprehensive experiments demonstrate that our approach can achieve near state-of-the-art performance on rotation-augmented dataset for ModelNet40 classification and outperform other models on SHREC'17 perturbed retrieval task.
Justlookup: One Millisecond Deep Feature Extraction for Point Clouds By Lookup Tables
Aug 14, 2019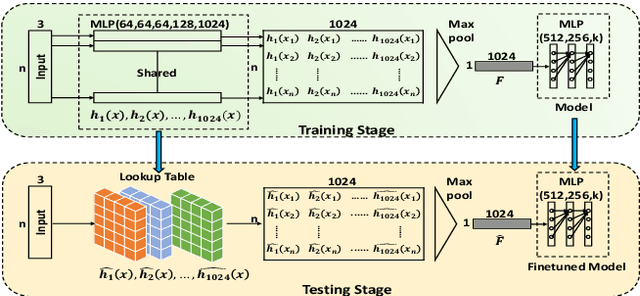



Deep models are capable of fitting complex high dimensional functions while usually yielding large computation load. There is no way to speed up the inference process by classical lookup tables due to the high-dimensional input and limited memory size. Recently, a novel architecture (PointNet) for point clouds has demonstrated that it is possible to obtain a complicated deep function from a set of 3-variable functions. In this paper, we exploit this property and apply a lookup table to encode these 3-variable functions. This method ensures that the inference time is only determined by the memory access no matter how complicated the deep function is. We conduct extensive experiments on ModelNet and ShapeNet datasets and demonstrate that we can complete the inference process in 1.5 ms on an Intel i7-8700 CPU (single core mode), 32x speedup over the PointNet architecture without any performance degradation.
Face Recognition from Sequential Sparse 3D data via Deep Registration
Oct 23, 2018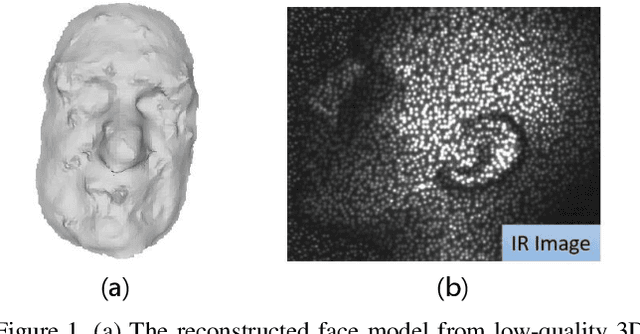

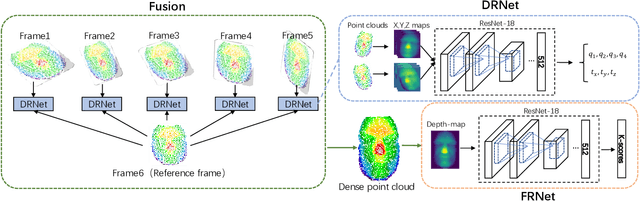
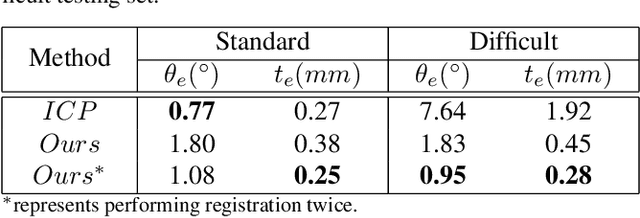
Previous works have shown that face recognition with high accuracy 3D data is more reliable and insensitive to pose and light variations. Recently, low-cost and portable 3D acquisition techniques like ToF(Time of Flight) and DoE based structured light enable us to access 3D data easily, e.g. via a mobile phone. However, these devices can only provide sparse(limited speckles in structured light system) and noisy 3D data which can not support face recognition directly. In this paper, we aim at achieving high performance face recognition for devices equipped with such modules which is very meaningful in practice as such devices will be very popular. We propose a framework to perform face recognition by fusing a sequence of low-quality 3D data. As 3D data are sparse and noisy which can not be well handled by conventional methods like the ICP algorithm, we design a PointNet-like Deep Registration Network(DRNet) which works with ordered 3D point coordinates while preserving the ability of mining local structures via convolution. Meanwhile we develop a novel loss function to optimize our DRNet based on the quaternion expression which obviously outperforms other widely used functions. For face recognition, we design a deep convolutional network which takes the fused 3D depth-map as input based on AMSoftmax model. Experiments show that our DRNet can achieve rotation error 0.95 degrees and translation error 0.28mm for registration. The face recognition on fused data also achieves rank-1 accuracy 99.2%, FAR-0.001 97.5% on Bosphorus dataset which is comparable with state-of-the-art high-quality data based recognition performance.