Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMPose: Alternatively Mixed Global-Local Attention Model for 3D Human Pose Estimation
Oct 11, 2022
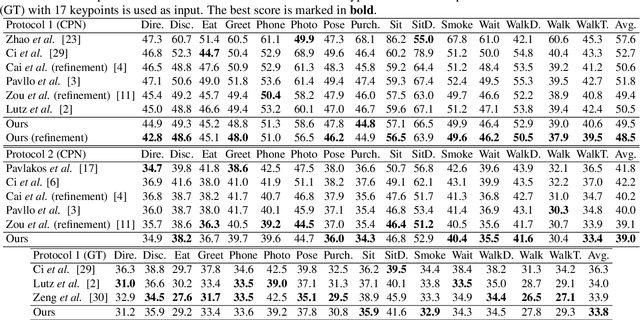
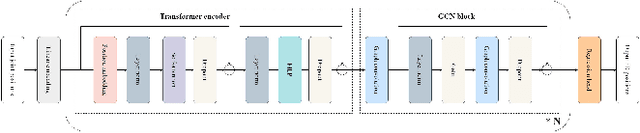
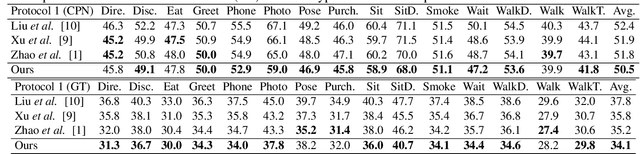
The graph convolutional network has been applied to 3D human pose estimation. In addition, the pure transformer model recently show the promising result in the video-based method. However, the single-frame method still need to model the physically connected relations among joints because the feature representation transformed only by the global attention has the lack of the relationships of human skeleton. We propose a novel architecture to combine the physically connected and global relations among joints in human. We evaluate our method on Human3.6m and compare with the state-of-the-art models. Our model show superior result over all other models. Our model has better generalization ability by cross-dataset comparison on MPI-INF-3DHP.
* 7 pages, 4 figures
Via