 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021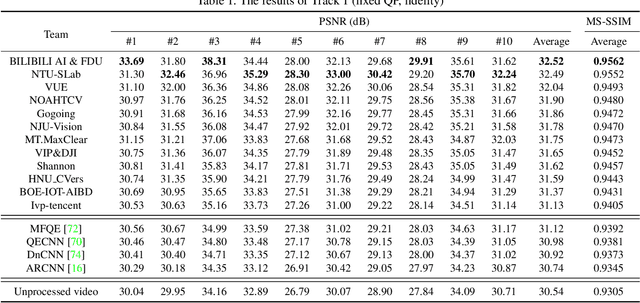
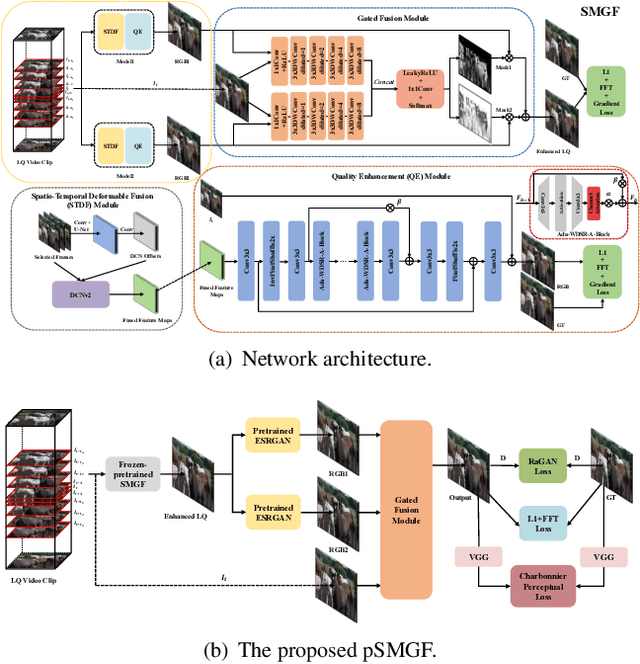
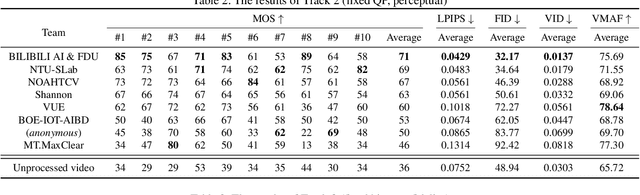
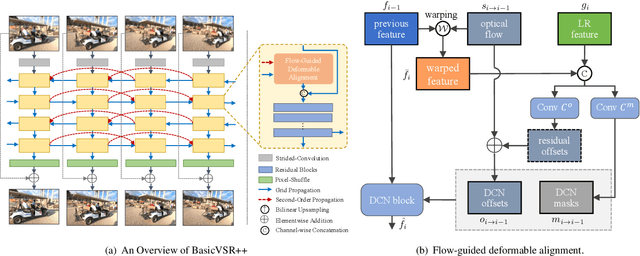
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
Is Faster R-CNN Doing Well for Pedestrian Detection?
Jul 27, 2016


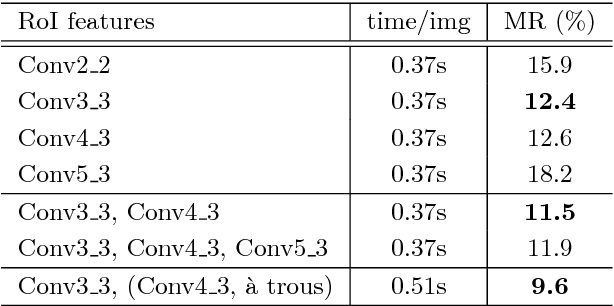
Detecting pedestrian has been arguably addressed as a special topic beyond general object detection. Although recent deep learning object detectors such as Fast/Faster R-CNN [1, 2] have shown excellent performance for general object detection, they have limited success for detecting pedestrian, and previous leading pedestrian detectors were in general hybrid methods combining hand-crafted and deep convolutional features. In this paper, we investigate issues involving Faster R-CNN [2] for pedestrian detection. We discover that the Region Proposal Network (RPN) in Faster R-CNN indeed performs well as a stand-alone pedestrian detector, but surprisingly, the downstream classifier degrades the results. We argue that two reasons account for the unsatisfactory accuracy: (i) insufficient resolution of feature maps for handling small instances, and (ii) lack of any bootstrapping strategy for mining hard negative examples. Driven by these observations, we propose a very simple but effective baseline for pedestrian detection, using an RPN followed by boosted forests on shared, high-resolution convolutional feature maps. We comprehensively evaluate this method on several benchmarks (Caltech, INRIA, ETH, and KITTI), presenting competitive accuracy and good speed. Code will be made publicly available.
End-to-End Photo-Sketch Generation via Fully Convolutional Representation Learning
Apr 11, 2015
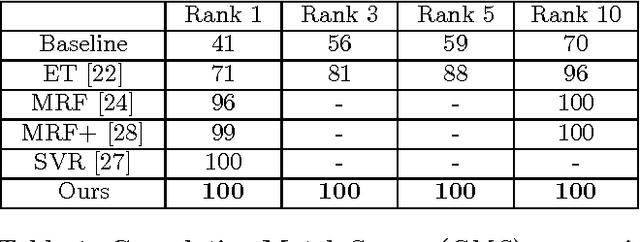
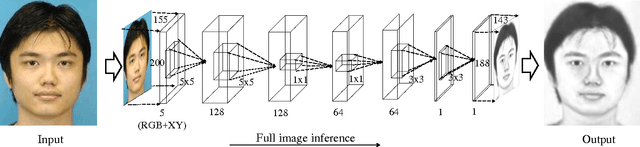

Sketch-based face recognition is an interesting task in vision and multimedia research, yet it is quite challenging due to the great difference between face photos and sketches. In this paper, we propose a novel approach for photo-sketch generation, aiming to automatically transform face photos into detail-preserving personal sketches. Unlike the traditional models synthesizing sketches based on a dictionary of exemplars, we develop a fully convolutional network to learn the end-to-end photo-sketch mapping. Our approach takes whole face photos as inputs and directly generates the corresponding sketch images with efficient inference and learning, in which the architecture are stacked by only convolutional kernels of very small sizes. To well capture the person identity during the photo-sketch transformation, we define our optimization objective in the form of joint generative-discriminative minimization. In particular, a discriminative regularization term is incorporated into the photo-sketch generation, enhancing the discriminability of the generated person sketches against other individuals. Extensive experiments on several standard benchmarks suggest that our approach outperforms other state-of-the-art methods in both photo-sketch generation and face sketch verification.
Deep Joint Task Learning for Generic Object Extraction
Feb 03, 2015



This paper investigates how to extract objects-of-interest without relying on hand-craft features and sliding windows approaches, that aims to jointly solve two sub-tasks: (i) rapidly localizing salient objects from images, and (ii) accurately segmenting the objects based on the localizations. We present a general joint task learning framework, in which each task (either object localization or object segmentation) is tackled via a multi-layer convolutional neural network, and the two networks work collaboratively to boost performance. In particular, we propose to incorporate latent variables bridging the two networks in a joint optimization manner. The first network directly predicts the positions and scales of salient objects from raw images, and the latent variables adjust the object localizations to feed the second network that produces pixelwise object masks. An EM-type method is presented for the optimization, iterating with two steps: (i) by using the two networks, it estimates the latent variables by employing an MCMC-based sampling method; (ii) it optimizes the parameters of the two networks unitedly via back propagation, with the fixed latent variables. Extensive experiments suggest that our framework significantly outperforms other state-of-the-art approaches in both accuracy and efficiency (e.g. 1000 times faster than competing approaches).
* 9 pages, 4 figures, NIPS 2014