 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation for Image Dehazing
May 10, 2020

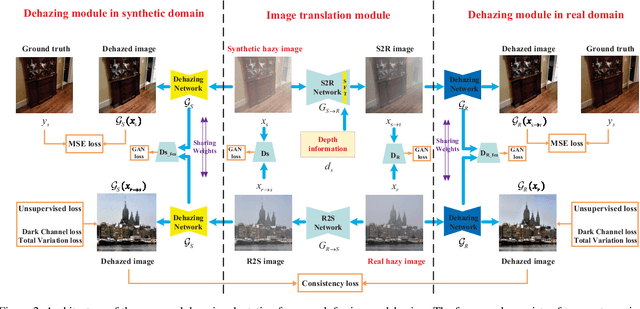
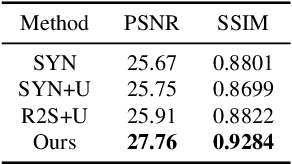
Image dehazing using learning-based methods has achieved state-of-the-art performance in recent years. However, most existing methods train a dehazing model on synthetic hazy images, which are less able to generalize well to real hazy images due to domain shift. To address this issue, we propose a domain adaptation paradigm, which consists of an image translation module and two image dehazing modules. Specifically, we first apply a bidirectional translation network to bridge the gap between the synthetic and real domains by translating images from one domain to another. And then, we use images before and after translation to train the proposed two image dehazing networks with a consistency constraint. In this phase, we incorporate the real hazy image into the dehazing training via exploiting the properties of the clear image (e.g., dark channel prior and image gradient smoothing) to further improve the domain adaptivity. By training image translation and dehazing network in an end-to-end manner, we can obtain better effects of both image translation and dehazing. Experimental results on both synthetic and real-world images demonstrate that our model performs favorably against the state-of-the-art dehazing algorithms.
GTNet: Generative Transfer Network for Zero-Shot Object Detection
Jan 24, 2020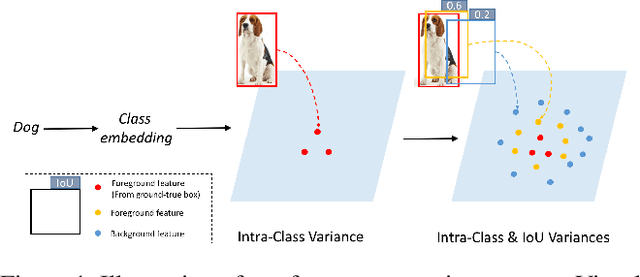
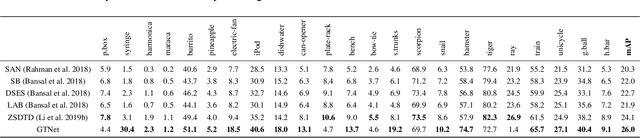
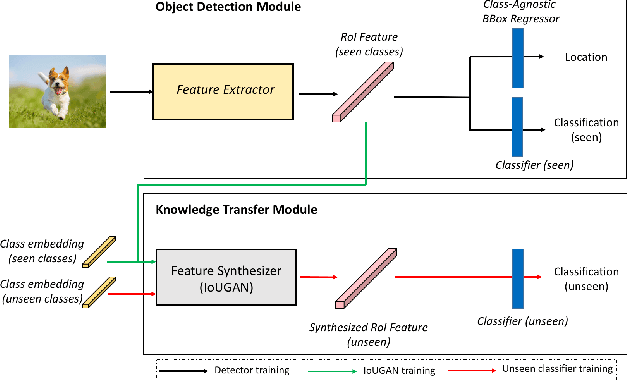
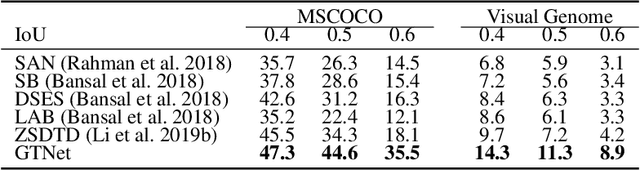
We propose a Generative Transfer Network (GTNet) for zero shot object detection (ZSD). GTNet consists of an Object Detection Module and a Knowledge Transfer Module. The Object Detection Module can learn large-scale seen domain knowledge. The Knowledge Transfer Module leverages a feature synthesizer to generate unseen class features, which are applied to train a new classification layer for the Object Detection Module. In order to synthesize features for each unseen class with both the intra-class variance and the IoU variance, we design an IoU-Aware Generative Adversarial Network (IoUGAN) as the feature synthesizer, which can be easily integrated into GTNet. Specifically, IoUGAN consists of three unit models: Class Feature Generating Unit (CFU), Foreground Feature Generating Unit (FFU), and Background Feature Generating Unit (BFU). CFU generates unseen features with the intra-class variance conditioned on the class semantic embeddings. FFU and BFU add the IoU variance to the results of CFU, yielding class-specific foreground and background features, respectively. We evaluate our method on three public datasets and the results demonstrate that our method performs favorably against the state-of-the-art ZSD approaches.
Learning a Discriminative Prior for Blind Image Deblurring
Apr 04, 2018
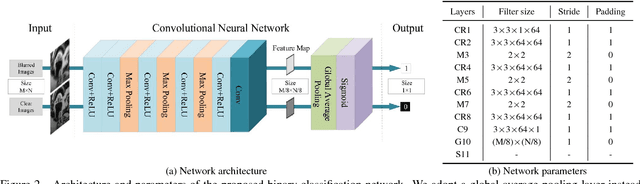
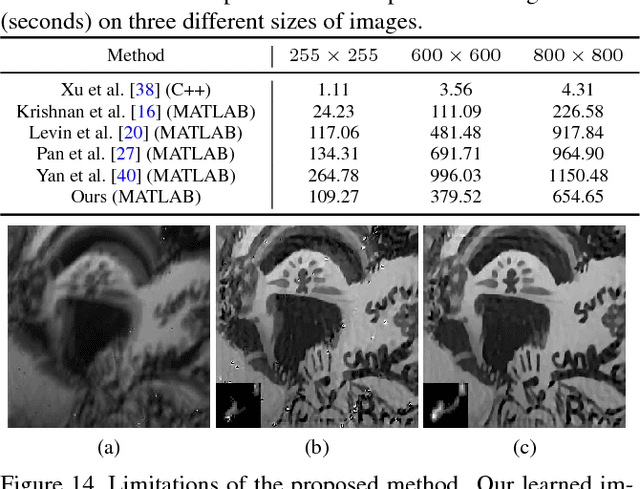
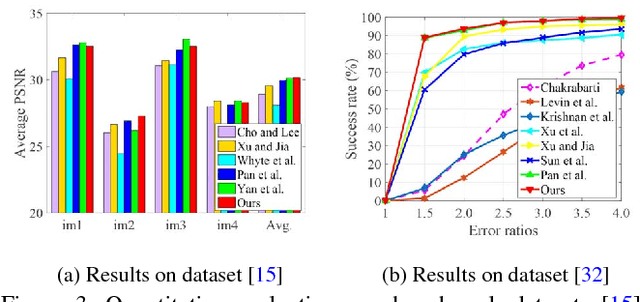
We present an effective blind image deblurring method based on a data-driven discriminative prior.Our work is motivated by the fact that a good image prior should favor clear images over blurred images.In this work, we formulate the image prior as a binary classifier which can be achieved by a deep convolutional neural network (CNN).The learned prior is able to distinguish whether an input image is clear or not.Embedded into the maximum a posterior (MAP) framework, it helps blind deblurring in various scenarios, including natural, face, text, and low-illumination images.However, it is difficult to optimize the deblurring method with the learned image prior as it involves a non-linear CNN.Therefore, we develop an efficient numerical approach based on the half-quadratic splitting method and gradient decent algorithm to solve the proposed model.Furthermore, the proposed model can be easily extended to non-uniform deblurring.Both qualitative and quantitative experimental results show that our method performs favorably against state-of-the-art algorithms as well as domain-specific image deblurring approaches.