 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Globally Convergent Evolutionary Strategy for Stochastic Constrained Optimization with Applications to Reinforcement Learning
Paper and Code
Feb 21, 2022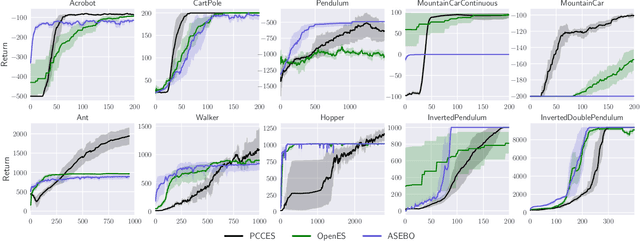
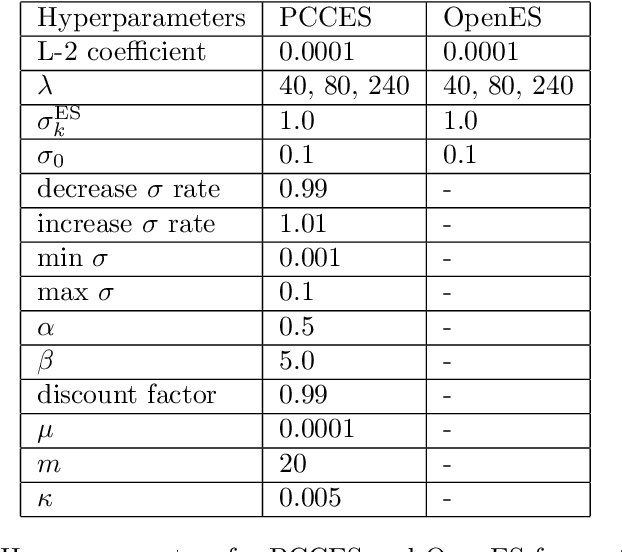
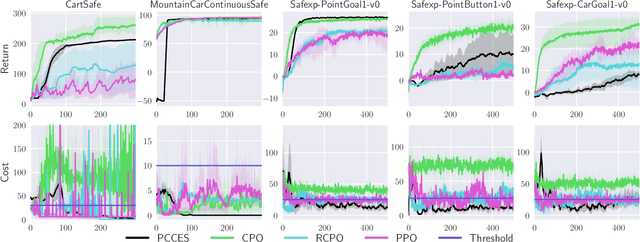
Evolutionary strategies have recently been shown to achieve competing levels of performance for complex optimization problems in reinforcement learning. In such problems, one often needs to optimize an objective function subject to a set of constraints, including for instance constraints on the entropy of a policy or to restrict the possible set of actions or states accessible to an agent. Convergence guarantees for evolutionary strategies to optimize stochastic constrained problems are however lacking in the literature. In this work, we address this problem by designing a novel optimization algorithm with a sufficient decrease mechanism that ensures convergence and that is based only on estimates of the functions. We demonstrate the applicability of this algorithm on two types of experiments: i) a control task for maximizing rewards and ii) maximizing rewards subject to a non-relaxable set of constraints.