 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReceptive Field Regularization Techniques for Audio Classification and Tagging with Deep Convolutional Neural Networks
Paper and Code
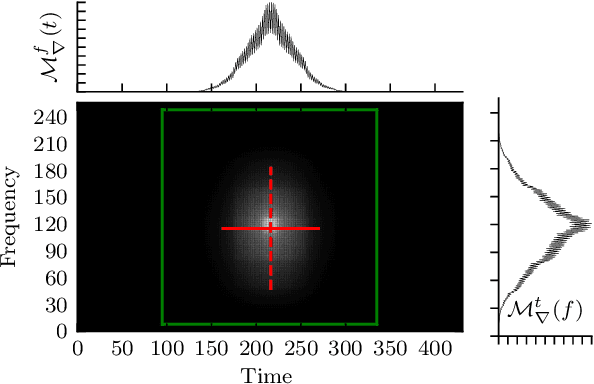
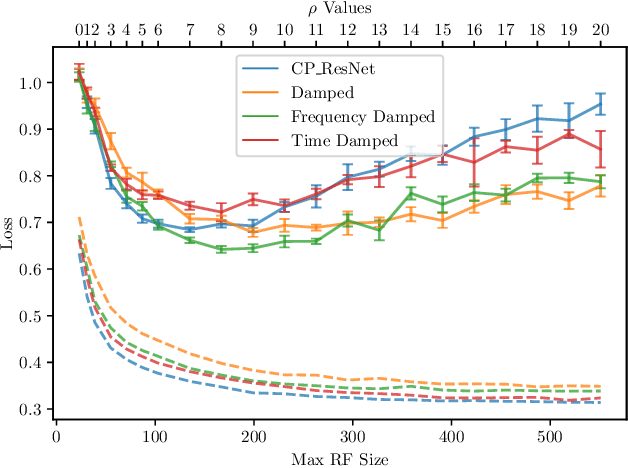
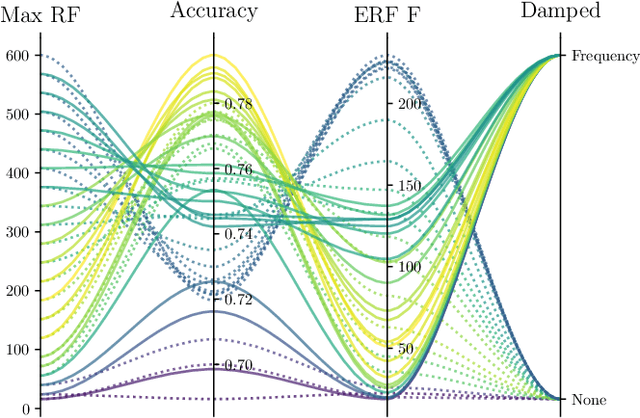
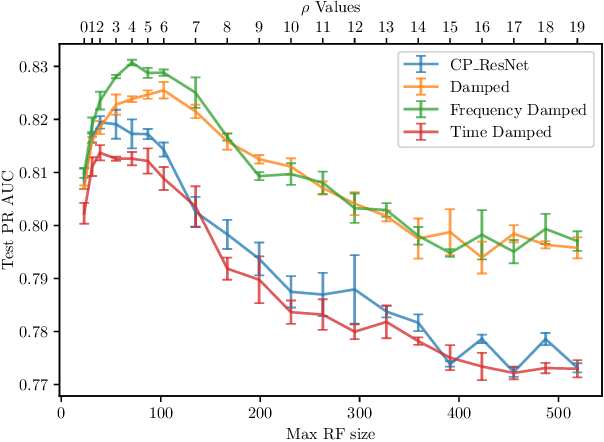
In this paper, we study the performance of variants of well-known Convolutional Neural Network (CNN) architectures on different audio tasks. We show that tuning the Receptive Field (RF) of CNNs is crucial to their generalization. An insufficient RF limits the CNN's ability to fit the training data. In contrast, CNNs with an excessive RF tend to over-fit the training data and fail to generalize to unseen testing data. As state-of-the-art CNN architectures-in computer vision and other domains-tend to go deeper in terms of number of layers, their RF size increases and therefore they degrade in performance in several audio classification and tagging tasks. We study well-known CNN architectures and how their building blocks affect their receptive field. We propose several systematic approaches to control the RF of CNNs and systematically test the resulting architectures on different audio classification and tagging tasks and datasets. The experiments show that regularizing the RF of CNNs using our proposed approaches can drastically improve the generalization of models, out-performing complex architectures and pre-trained models on larger datasets. The proposed CNNs achieve state-of-the-art results in multiple tasks, from acoustic scene classification to emotion and theme detection in music to instrument recognition, as demonstrated by top ranks in several pertinent challenges (DCASE, MediaEval).