 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSL: Understanding and Improving Softmax Recommender Systems with Competition-Aware Scaling
Feb 06, 2026Softmax Loss (SL) is being increasingly adopted for recommender systems (RS) as it has demonstrated better performance, robustness and fairness. Yet in implicit-feedback, a single global temperature and equal treatment of uniformly sampled negatives can lead to brittle training, because sampled sets may contain varying degrees of relevant or informative competitors. The optimal loss sharpness for a user-item pair with a particular set of negatives, can be suboptimal or destabilising for another with different negatives. We introduce Dual-scale Softmax Loss (DSL), which infers effective sharpness from the sampled competition itself. DSL adds two complementary branches to the log-sum-exp backbone. Firstly it reweights negatives within each training instance using hardness and item--item similarity, secondly it adapts a per-example temperature from the competition intensity over a constructed competitor slate. Together, these components preserve the geometry of SL while reshaping the competition distribution across negatives and across examples. Over several representative benchmarks and backbones, DSL yields substantial gains over strong baselines, with improvements over SL exceeding $10%$ in several settings and averaging $6.22%$ across datasets, metrics, and backbones. Under out-of-distribution (OOD) popularity shift, the gains are larger, with an average of $9.31%$ improvement over SL. We further provide a theoretical, distributionally robust optimisation (DRO) analysis, which demonstrates how DSL reshapes the robust payoff and the KL deviation for ambiguous instances. This helps explain the empirically observed improvements in accuracy and robustness.
Multimodal Enhancement of Sequential Recommendation
Feb 06, 2026We propose a novel recommender framework, MuSTRec (Multimodal and Sequential Transformer-based Recommendation), that unifies multimodal and sequential recommendation paradigms. MuSTRec captures cross-item similarities and collaborative filtering signals, by building item-item graphs from extracted text and visual features. A frequency-based self-attention module additionally captures the short- and long-term user preferences. Across multiple Amazon datasets, MuSTRec demonstrates superior performance (up to 33.5% improvement) over multimodal and sequential state-of-the-art baselines. Finally, we detail some interesting facets of this new recommendation paradigm. These include the need for a new data partitioning regime, and a demonstration of how integrating user embeddings into sequential recommendation leads to drastically increased short-term metrics (up to 200% improvement) on smaller datasets. Our code is availabe at https://anonymous.4open.science/r/MuSTRec-D32B/ and will be made publicly available.
Sequences as Nodes for Contrastive Multimodal Graph Recommendation
Feb 06, 2026To tackle cold-start and data sparsity issues in recommender systems, numerous multimodal, sequential, and contrastive techniques have been proposed. While these augmentations can boost recommendation performance, they tend to add noise and disrupt useful semantics. To address this, we propose MuSICRec (Multimodal Sequence-Item Contrastive Recommender), a multi-view graph-based recommender that combines collaborative, sequential, and multimodal signals. We build a sequence-item (SI) view by attention pooling over the user's interacted items to form sequence nodes. We propagate over the SI graph, obtaining a second view organically as an alternative to artificial data augmentation, while simultaneously injecting sequential context signals. Additionally, to mitigate modality noise and align the multimodal information, the contribution of text and visual features is modulated according to an ID-guided gate. We evaluate under a strict leave-two-out split against a broad range of sequential, multimodal, and contrastive baselines. On the Amazon Baby, Sports, and Electronics datasets, MuSICRec outperforms state-of-the-art baselines across all model types. We observe the largest gains for short-history users, mitigating sparsity and cold-start challenges. Our code is available at https://anonymous.4open.science/r/MuSICRec-3CEE/ and will be made publicly available.
Modelling the Distribution of Human Motion for Sign Language Assessment
Aug 19, 2024



Sign Language Assessment (SLA) tools are useful to aid in language learning and are underdeveloped. Previous work has focused on isolated signs or comparison against a single reference video to assess Sign Languages (SL). This paper introduces a novel SLA tool designed to evaluate the comprehensibility of SL by modelling the natural distribution of human motion. We train our pipeline on data from native signers and evaluate it using SL learners. We compare our results to ratings from a human raters study and find strong correlation between human ratings and our tool. We visually demonstrate our tools ability to detect anomalous results spatio-temporally, providing actionable feedback to aid in SL learning and assessment.
Improving Robot Localisation by Ignoring Visual Distraction
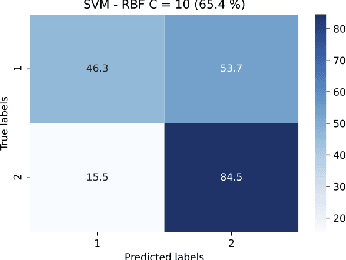
Jul 25, 2021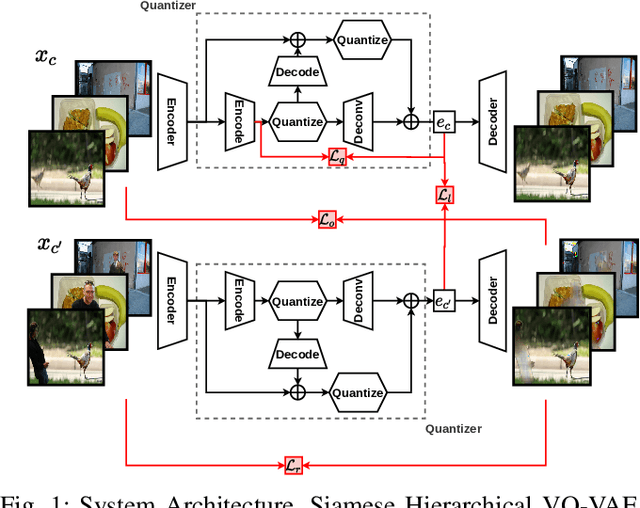
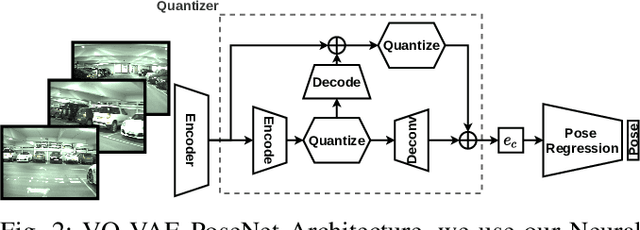


Attention is an important component of modern deep learning. However, less emphasis has been put on its inverse: ignoring distraction. Our daily lives require us to explicitly avoid giving attention to salient visual features that confound the task we are trying to accomplish. This visual prioritisation allows us to concentrate on important tasks while ignoring visual distractors. In this work, we introduce Neural Blindness, which gives an agent the ability to completely ignore objects or classes that are deemed distractors. More explicitly, we aim to render a neural network completely incapable of representing specific chosen classes in its latent space. In a very real sense, this makes the network "blind" to certain classes, allowing and agent to focus on what is important for a given task, and demonstrates how this can be used to improve localisation.
BERT meets LIWC: Exploring State-of-the-Art Language Models for Predicting Communication Behavior in Couples' Conflict Interactions
Jun 03, 2021
Many processes in psychology are complex, such as dyadic interactions between two interacting partners (e.g. patient-therapist, intimate relationship partners). Nevertheless, many basic questions about interactions are difficult to investigate because dyadic processes can be within a person and between partners, they are based on multimodal aspects of behavior and unfold rapidly. Current analyses are mainly based on the behavioral coding method, whereby human coders annotate behavior based on a coding schema. But coding is labor-intensive, expensive, slow, focuses on few modalities. Current approaches in psychology use LIWC for analyzing couples' interactions. However, advances in natural language processing such as BERT could enable the development of systems to potentially automate behavioral coding, which in turn could substantially improve psychological research. In this work, we train machine learning models to automatically predict positive and negative communication behavioral codes of 368 German-speaking Swiss couples during an 8-minute conflict interaction on a fine-grained scale (10-seconds sequences) using linguistic features and paralinguistic features derived with openSMILE. Our results show that both simpler TF-IDF features as well as more complex BERT features performed better than LIWC, and that adding paralinguistic features did not improve the performance. These results suggest it might be time to consider modern alternatives to LIWC, the de facto linguistic features in psychology, for prediction tasks in couples research. This work is a further step towards the automated coding of couples' behavior which could enhance couple research and therapy, and be utilized for other dyadic interactions as well.