 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical I3D for Sign Spotting
Paper and Code
Oct 03, 2022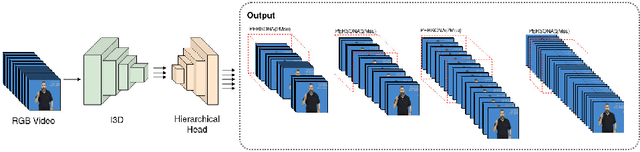

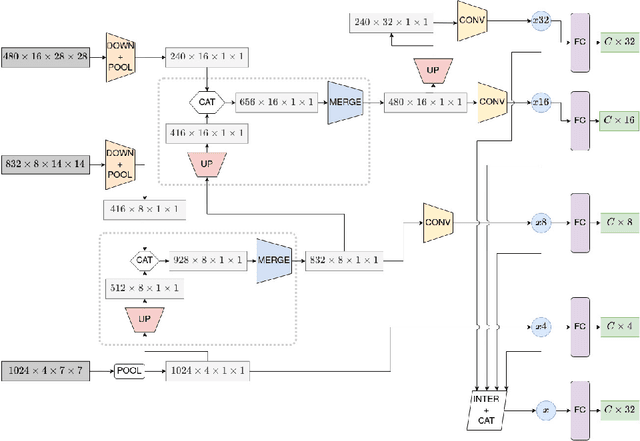
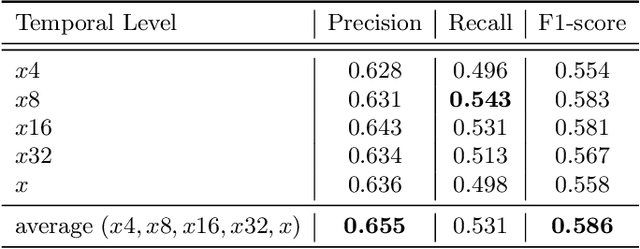
Most of the vision-based sign language research to date has focused on Isolated Sign Language Recognition (ISLR), where the objective is to predict a single sign class given a short video clip. Although there has been significant progress in ISLR, its real-life applications are limited. In this paper, we focus on the challenging task of Sign Spotting instead, where the goal is to simultaneously identify and localise signs in continuous co-articulated sign videos. To address the limitations of current ISLR-based models, we propose a hierarchical sign spotting approach which learns coarse-to-fine spatio-temporal sign features to take advantage of representations at various temporal levels and provide more precise sign localisation. Specifically, we develop Hierarchical Sign I3D model (HS-I3D) which consists of a hierarchical network head that is attached to the existing spatio-temporal I3D model to exploit features at different layers of the network. We evaluate HS-I3D on the ChaLearn 2022 Sign Spotting Challenge - MSSL track and achieve a state-of-the-art 0.607 F1 score, which was the top-1 winning solution of the competition.