 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWideSearch: Benchmarking Agentic Broad Info-Seeking
Aug 11, 2025From professional research to everyday planning, many tasks are bottlenecked by wide-scale information seeking, which is more repetitive than cognitively complex. With the rapid development of Large Language Models (LLMs), automated search agents powered by LLMs offer a promising solution to liberate humans from this tedious work. However, the capability of these agents to perform such "wide-context" collection reliably and completely remains largely unevaluated due to a lack of suitable benchmarks. To bridge this gap, we introduce WideSearch, a new benchmark engineered to evaluate agent reliability on these large-scale collection tasks. The benchmark features 200 manually curated questions (100 in English, 100 in Chinese) from over 15 diverse domains, grounded in real user queries. Each task requires agents to collect large-scale atomic information, which could be verified one by one objectively, and arrange it into a well-organized output. A rigorous five-stage quality control pipeline ensures the difficulty, completeness, and verifiability of the dataset. We benchmark over 10 state-of-the-art agentic search systems, including single-agent, multi-agent frameworks, and end-to-end commercial systems. Most systems achieve overall success rates near 0\%, with the best performer reaching just 5\%. However, given sufficient time, cross-validation by multiple human testers can achieve a near 100\% success rate. These results demonstrate that present search agents have critical deficiencies in large-scale information seeking, underscoring urgent areas for future research and development in agentic search. Our dataset, evaluation pipeline, and benchmark results have been publicly released at https://widesearch-seed.github.io/
SignRep: Enhancing Self-Supervised Sign Representations
Mar 11, 2025Sign language representation learning presents unique challenges due to the complex spatio-temporal nature of signs and the scarcity of labeled datasets. Existing methods often rely either on models pre-trained on general visual tasks, that lack sign-specific features, or use complex multimodal and multi-branch architectures. To bridge this gap, we introduce a scalable, self-supervised framework for sign representation learning. We leverage important inductive (sign) priors during the training of our RGB model. To do this, we leverage simple but important cues based on skeletons while pretraining a masked autoencoder. These sign specific priors alongside feature regularization and an adversarial style agnostic loss provide a powerful backbone. Notably, our model does not require skeletal keypoints during inference, avoiding the limitations of keypoint-based models during downstream tasks. When finetuned, we achieve state-of-the-art performance for sign recognition on the WLASL, ASL-Citizen and NMFs-CSL datasets, using a simpler architecture and with only a single-modality. Beyond recognition, our frozen model excels in sign dictionary retrieval and sign translation, surpassing standard MAE pretraining and skeletal-based representations in retrieval. It also reduces computational costs for training existing sign translation models while maintaining strong performance on Phoenix2014T, CSL-Daily and How2Sign.
Sign2GPT: Leveraging Large Language Models for Gloss-Free Sign Language Translation
May 07, 2024



Automatic Sign Language Translation requires the integration of both computer vision and natural language processing to effectively bridge the communication gap between sign and spoken languages. However, the deficiency in large-scale training data to support sign language translation means we need to leverage resources from spoken language. We introduce, Sign2GPT, a novel framework for sign language translation that utilizes large-scale pretrained vision and language models via lightweight adapters for gloss-free sign language translation. The lightweight adapters are crucial for sign language translation, due to the constraints imposed by limited dataset sizes and the computational requirements when training with long sign videos. We also propose a novel pretraining strategy that directs our encoder to learn sign representations from automatically extracted pseudo-glosses without requiring gloss order information or annotations. We evaluate our approach on two public benchmark sign language translation datasets, namely RWTH-PHOENIX-Weather 2014T and CSL-Daily, and improve on state-of-the-art gloss-free translation performance with a significant margin.
Learnt Contrastive Concept Embeddings for Sign Recognition
Aug 18, 2023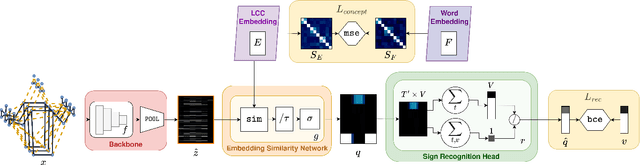
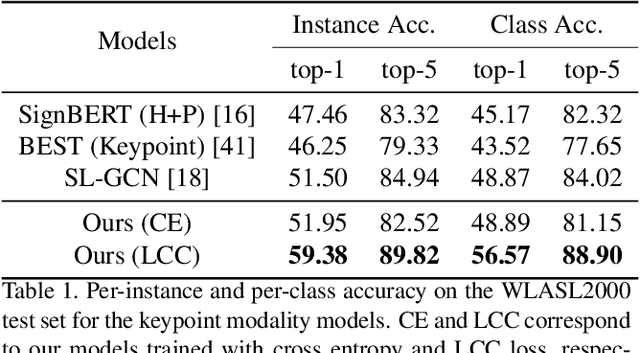
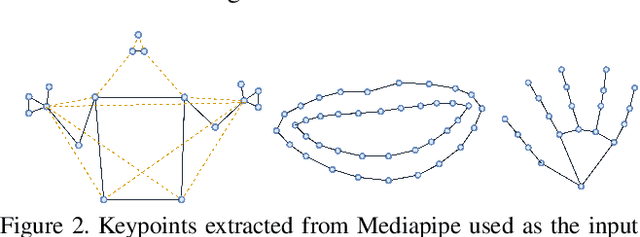
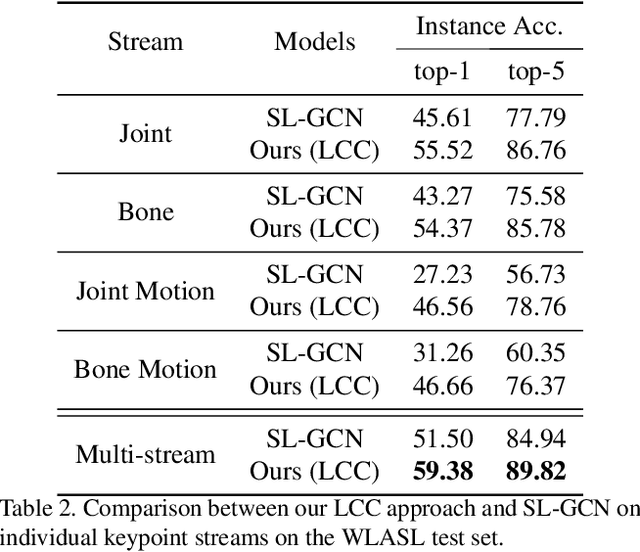
In natural language processing (NLP) of spoken languages, word embeddings have been shown to be a useful method to encode the meaning of words. Sign languages are visual languages, which require sign embeddings to capture the visual and linguistic semantics of sign. Unlike many common approaches to Sign Recognition, we focus on explicitly creating sign embeddings that bridge the gap between sign language and spoken language. We propose a learning framework to derive LCC (Learnt Contrastive Concept) embeddings for sign language, a weakly supervised contrastive approach to learning sign embeddings. We train a vocabulary of embeddings that are based on the linguistic labels for sign video. Additionally, we develop a conceptual similarity loss which is able to utilise word embeddings from NLP methods to create sign embeddings that have better sign language to spoken language correspondence. These learnt representations allow the model to automatically localise the sign in time. Our approach achieves state-of-the-art keypoint-based sign recognition performance on the WLASL and BOBSL datasets.
Hierarchical I3D for Sign Spotting
Oct 03, 2022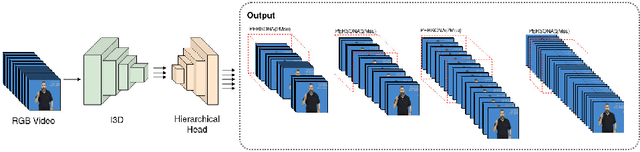

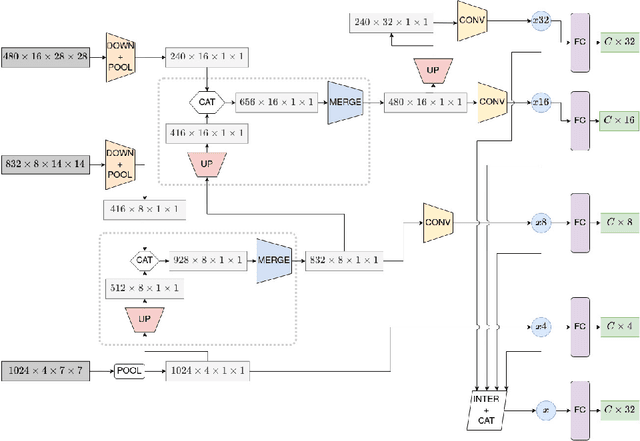
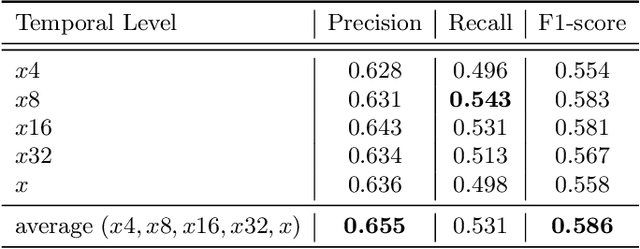
Most of the vision-based sign language research to date has focused on Isolated Sign Language Recognition (ISLR), where the objective is to predict a single sign class given a short video clip. Although there has been significant progress in ISLR, its real-life applications are limited. In this paper, we focus on the challenging task of Sign Spotting instead, where the goal is to simultaneously identify and localise signs in continuous co-articulated sign videos. To address the limitations of current ISLR-based models, we propose a hierarchical sign spotting approach which learns coarse-to-fine spatio-temporal sign features to take advantage of representations at various temporal levels and provide more precise sign localisation. Specifically, we develop Hierarchical Sign I3D model (HS-I3D) which consists of a hierarchical network head that is attached to the existing spatio-temporal I3D model to exploit features at different layers of the network. We evaluate HS-I3D on the ChaLearn 2022 Sign Spotting Challenge - MSSL track and achieve a state-of-the-art 0.607 F1 score, which was the top-1 winning solution of the competition.