 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Cell-Level Quality of Service Estimation on 5G Networks Using Machine Learning Techniques
Jan 06, 2023This study presents a general machine learning framework to estimate the traffic-measurement-level experience rate at given throughput values in the form of a Key Performance Indicator for the cells on base stations across various cities, using busy-hour counter data, and several technical parameters together with the network topology. Relying on feature engineering techniques, scores of additional predictors are proposed to enhance the effects of raw correlated counter values over the corresponding targets, and to represent the underlying interactions among groups of cells within nearby spatial locations effectively. An end-to-end regression modeling is applied on the transformed data, with results presented on unseen cities of varying sizes.
Building Segmentation on Satellite Images and Performance of Post-Processing Methods
Dec 28, 2022



Researchers are doing intensive work on satellite images due to the information it contains with the development of computer vision algorithms and the ease of accessibility to satellite images. Building segmentation of satellite images can be used for many potential applications such as city, agricultural, and communication network planning. However, since no dataset exists for every region, the model trained in a region must gain generality. In this study, we trained several models in China and post-processing work was done on the best model selected among them. These models are evaluated in the Chicago region of the INRIA dataset. As can be seen from the results, although state-of-art results in this area have not been achieved, the results are promising. We aim to present our initial experimental results of a building segmentation from satellite images in this study.
Semi-Supervised Domain Adaptation for Semantic Segmentation of Roads from Satellite Images
Dec 26, 2022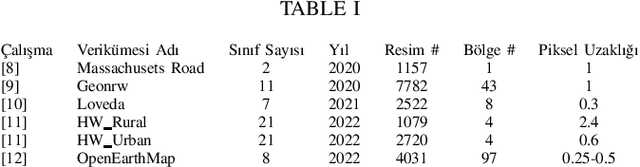
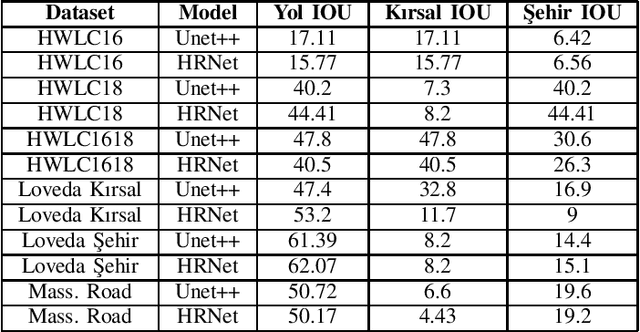
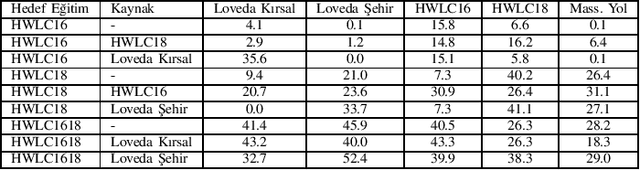
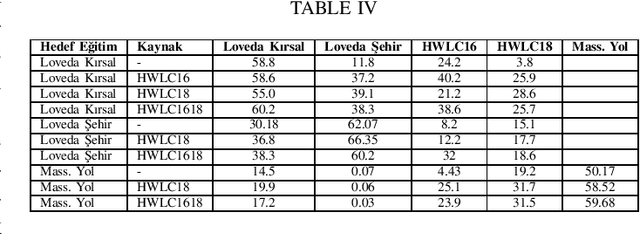
This paper presents the preliminary findings of a semi-supervised segmentation method for extracting roads from sattelite images. Artificial Neural Networks and image segmentation methods are among the most successful methods for extracting road data from satellite images. However, these models require large amounts of training data from different regions to achieve high accuracy rates. In cases where this data needs to be of more quantity or quality, it is a standard method to train deep neural networks by transferring knowledge from annotated data obtained from different sources. This study proposes a method that performs path segmentation with semi-supervised learning methods. A semi-supervised field adaptation method based on pseudo-labeling and Minimum Class Confusion method has been proposed, and it has been observed to increase performance in targeted datasets.
Minimum Class Confusion based Transfer for Land Cover Segmentation in Rural and Urban Regions
Dec 05, 2022Transfer Learning methods are widely used in satellite image segmentation problems and improve performance upon classical supervised learning methods. In this study, we present a semantic segmentation method that allows us to make land cover maps by using transfer learning methods. We compare models trained in low-resolution images with insufficient data for the targeted region or zoom level. In order to boost performance on target data we experiment with models trained with unsupervised, semi-supervised and supervised transfer learning approaches, including satellite images from public datasets and other unlabeled sources. According to experimental results, transfer learning improves segmentation performance 3.4% MIoU (Mean Intersection over Union) in rural regions and 12.9% MIoU in urban regions. We observed that transfer learning is more effective when two datasets share a comparable zoom level and are labeled with identical rules; otherwise, semi-supervised learning is more effective by using the data as unlabeled. In addition, experiments showed that HRNet outperformed building segmentation approaches in multi-class segmentation.
Cheating Detection Pipeline for Online Interviews and Exams
Jun 28, 2021

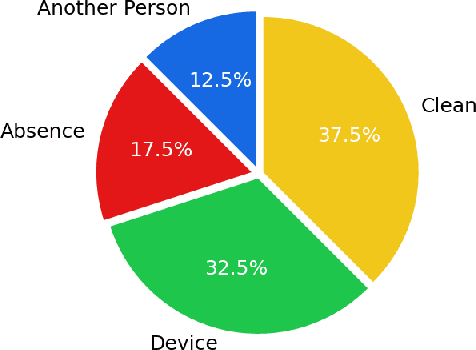
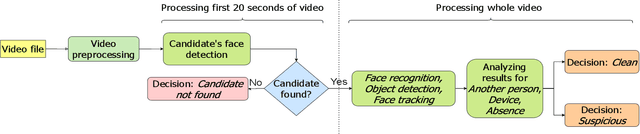
Remote examination and job interviews have gained popularity and become indispensable because of both pandemics and the advantage of remote working circumstances. Most companies and academic institutions utilize these systems for their recruitment processes and also for online exams. However, one of the critical problems of the remote examination systems is conducting the exams in a reliable environment. In this work, we present a cheating analysis pipeline for online interviews and exams. The system only requires a video of the candidate, which is recorded during the exam. Then cheating detection pipeline is employed to detect another person, electronic device usage, and candidate absence status. The pipeline consists of face detection, face recognition, object detection, and face tracking algorithms. To evaluate the performance of the pipeline we collected a private video dataset. The video dataset includes both cheating activities and clean videos. Ultimately, our pipeline presents an efficient and fast guideline to detect and analyze cheating activities in an online interview and exam video.
A Case Study: Using Genetic Algorithm for Job Scheduling Problem
Jun 09, 2021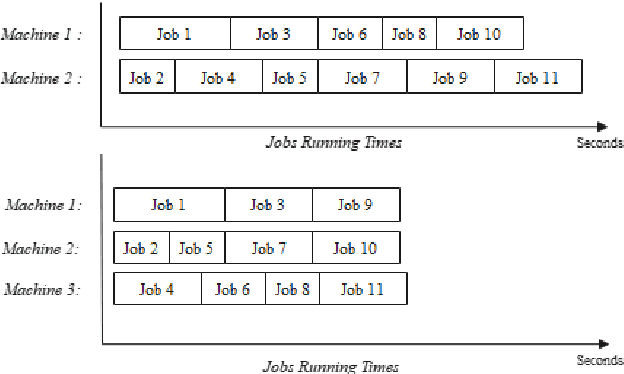
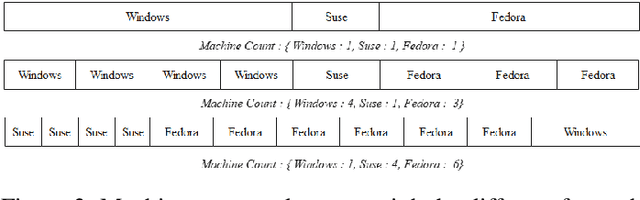
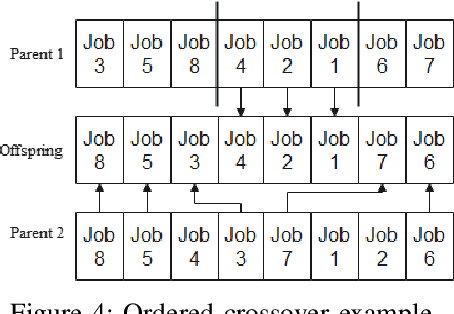
Nowadays, DevOps pipelines of huge projects are getting more and more complex. Each job in the pipeline might need different requirements including specific hardware specifications and dependencies. To achieve minimal makespan, developers always apply as much machines as possible. Consequently, others may be stalled for waiting resource released. Minimizing the makespan of each job using a few resource is a challenging problem. In this study, it is aimed to 1) automatically determine the priority of jobs to reduce the waiting time in the line, 2) automatically allocate the machine resource to each job. In this work, the problem is formulated as a multi-objective optimization problem. We use GA algorithm to automatically determine job priorities and resource demand for minimizing individual makespan and resource usage. Finally, the experimental results show that our proposed priority list generation algorithm is more effective than current priority list producing method in the aspects of makespan and allocated machine count.
FOGA: Flag Optimization with Genetic Algorithm
May 15, 2021

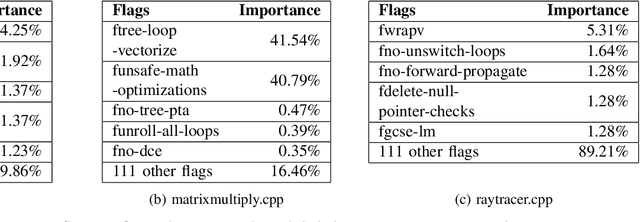
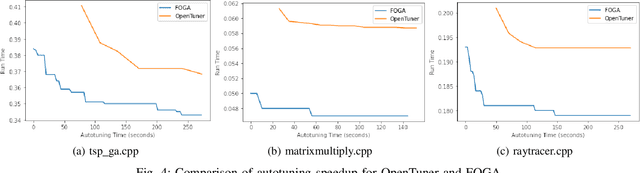
Recently, program autotuning has become very popular especially in embedded systems, when we have limited resources such as computing power and memory where these systems run generally time-critical applications. Compiler optimization space gradually expands with the renewed compiler options and inclusion of new architectures. These advancements bring autotuning even more important position. In this paper, we introduced Flag Optimization with Genetic Algorithm (FOGA) as an autotuning solution for GCC flag optimization. FOGA has two main advantages over the other autotuning approaches: the first one is the hyperparameter tuning of the genetic algorithm (GA), the second one is the maximum iteration parameter to stop when no further improvement occurs. We demonstrated remarkable speedup in the execution time of C++ source codes with the help of optimization flags provided by FOGA when compared to the state of the art framework OpenTuner.